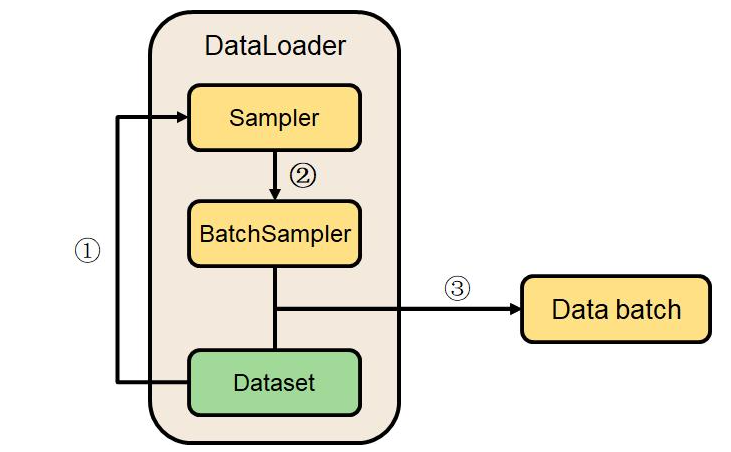
Guide: Pytorch data Samplers & Sequence bucketing Explore and run machine learning code with Kaggle Notebooks | Using data from CommonLit Readability Prize www.kaggle.com 링크의 내용 리뷰하고자 한다. Data Sampler : 주어진 데이터 풀과 배치 사이즈에서 어떻게 배치를 형성할지 결정해주며, 데이터셋의 순서(order)를 결정하기도 한다. Dataloader가 초기화될 때, 그 안에서 데이터셋의 샘플들의 sequence order를 작성한다. 이때 만들어진 sequence를 통해 데이터셋에서 데이터들이 주어진 배치사이즈만큼 배치의 형태로 나오게 된다. dataset..