Guide: Pytorch data Samplers & Sequence bucketing
Explore and run machine learning code with Kaggle Notebooks | Using data from CommonLit Readability Prize
www.kaggle.com
링크의 내용 리뷰하고자 한다.

Data Sampler : 주어진 데이터 풀과 배치 사이즈에서 어떻게 배치를 형성할지 결정해주며,
데이터셋의 순서(order)를 결정하기도 한다.
Dataloader가 초기화될 때, 그 안에서 데이터셋의 샘플들의 sequence order를 작성한다.
이때 만들어진 sequence를 통해 데이터셋에서 데이터들이 주어진 배치사이즈만큼 배치의 형태로 나오게 된다.

dataset을 불러오고 target을 기준으로 계급(bin)을 나눔.

시각화.

Dataset의 필요한 요소들을 불러올 수 있는 함수를 작성하고
roberta-base 토크나이저를 불러옴.
sampler 옵션을 변경하기 용이한 함수를 작성.
배치 내의 각 bin의 개수를 새는 함수와
배치 내의 bin 분포를 시각화하는 함수를 작성.
1. Random Sampler
- 그냥 랜덤하게 샘플링함.

2. SubsetRandom Sampler
- index 리스트를 가지고 샘플링, K fold를 써서 랜덤하게 뽑을 수 있다.

3. Sequential Sampler
- 순서대로 데이터를 샘플링, 항상 같은 순서

4. Custom Sampler (weighted)
- 가중치를 둔 커스텀 샘플러
- 각 배치들에 모든 클래스 비율이 비슷하게 뽑음

Sequence Bucketing
- 샘플링된 샘플들을 배치로 묶어줄 때 dynamic padding을 사용할 수 있게 해주는 방법론
- dynamic padding은 배치마다 padding을 다르게 주는 기술.

Dataset의 각 요소들을 가져오는 함수를 다시 작성.

샘플들을 가져와서 배치로 만들어주는 함수 작성.

dataloader의 collate_fn 옵션에 CLMcollate(config)의 도출값인 sequence를 입력해주었다.
collate_fn은 a list of samples를 mini-batch of Tensor(s)로 합쳐주는 옵션.
config에서 bucket을 False로 설정
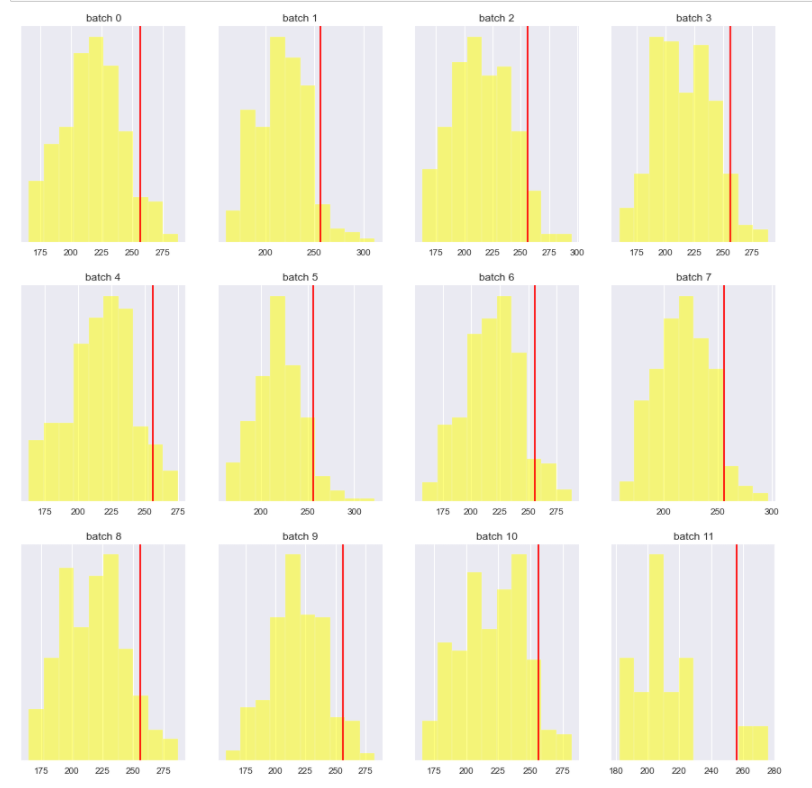
빨간 선은 덧붙여진(padded) 길이를 보여주고
분포도는 각 배치 토큰 길이의 분포를 보여줌.
dynamic padding이 적용되지 않았기 때문에 max length가 고정되었고 그에 따라 정보의 손실이 발생.
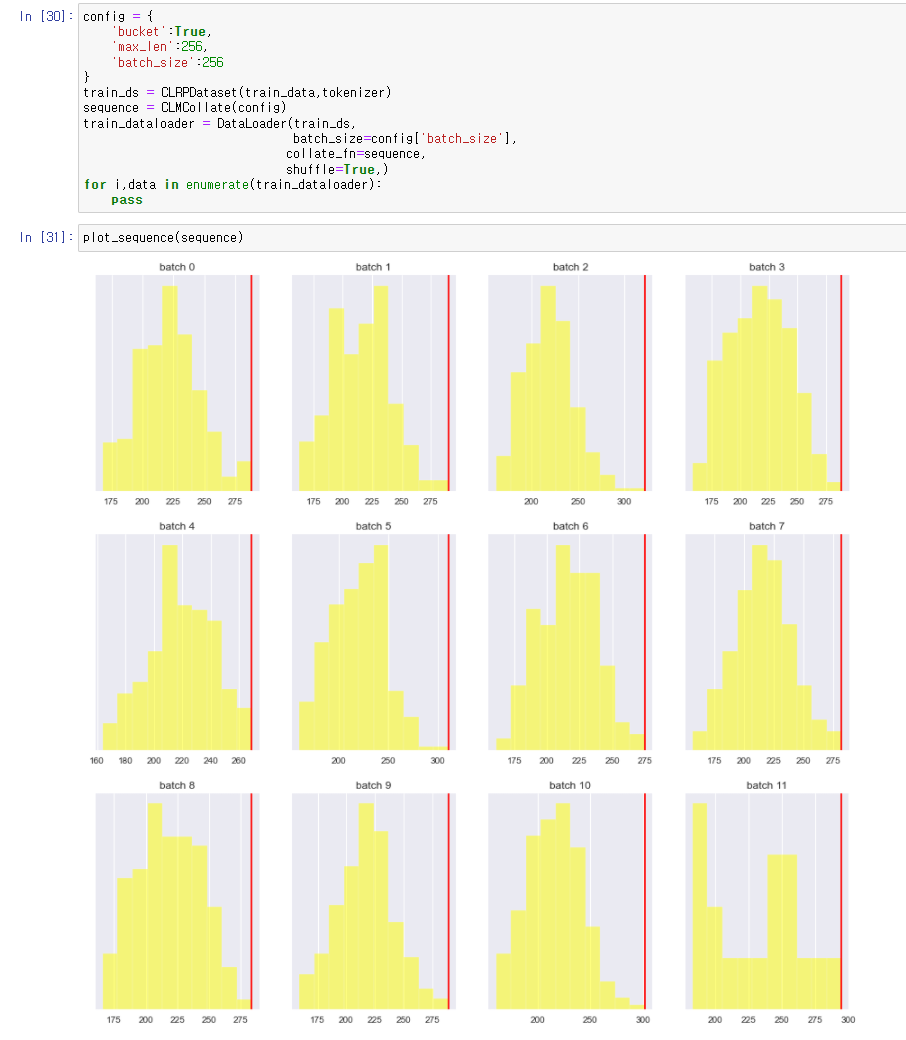
config에서 bucket을 True로 설정했을 때의 결과.
max length 이상의 token 들에 대해서도 dynamic padding이 된 것을 볼 수 있다.
dynamic padding이 불필요한 padding을 줄이기 위해서 나온 방법으로 알고 있는데
여기에서는 max length 이상의 토큰들에도 패딩이 적용되는 것으로 소개하는 느낌이 있다.
설명이 잘못된 것인지 dynamic padding 기술을 응용한 것인지 잘 모르겠다.
※ collate_fn
아래 내용은 스크린샷 링크의 내용을 번역하고 해석한 내용이며
실제 실험을 통해 직접 비교해본 내용은 아니니 참고 바란다.

automatic batching
- 미니 배치를 불러와 배치된 샘플들로 연결시켜주는 것에 관한 내용.
- batch_size 와 batch_sampler 옵션이 모두 None이면 disabled 된다.
- dataset code의 batching을 직접하고 싶거나 individual samples를 불러오고 싶을 때 disable 하기도 함.
automatic batching이 disabled 일 때,
collate_fn은 단순히 numpy 배열을 pytorch tensors로 변환해준다.
automatic batching이 enabled 일 때,
collate_fn은 (image, class_index)의 dataset 튜플들을
(batched image tensor, batched class label tensor)의 단일 튜플로 collates 해줌.
value가 텐서로 치환이 되지 않을 경우 list로 저장해주기도 함.
더 자세한 내용은 스크린샷의 링크를 참조하기 바란다.
'Data > 코드 리뷰' 카테고리의 다른 글
| Evaluating Student Writing_1st Place Solution (0) | 2022.04.03 |
|---|---|
| Evaluating Student Writing_2nd Place Solution (0) | 2022.03.24 |
| Data Augmentation (CSV&TXT) using Back Translation (0) | 2022.03.15 |
| TensorFlow LongFormer NER Baseline (0) | 2022.03.15 |
| two longformer is better than one (0) | 2022.03.15 |



