feedback-nn-train
Explore and run machine learning code with Kaggle Notebooks | Using data from Feedback Prize - Evaluating Student Writing
www.kaggle.com
참여했던 캐글 공모전의 1nd place solution을 분석해보려고 한다.
작성된 method 위주로 리뷰를 해보겠다.

교집합, 즉 얼마나 두 집단이 겹쳐있느냐를 파악하는 함수.
set()을 활용했다.
f1_score를 구하는 함수.
log와 slient를 파라미터로 주어 slient에 따라 함수 아래의 문장을 실행하도록 하였다.
예측값과 실제값의 고유값을 비교해주고자 한듯 하다.
slient는 오타인 것 같다.
그리고 아래에서 test_pred의 'class'에 따라 루프를 돌려줬는데
loc()과 reset_index()를 활용해서 데이터프레임을 조작해주었다.
copy()로 데이터프레임을 다룰 때마다 얕은 복사를 했는데 메모리 사용을 줄이려 한 게 아닌가 싶다.
pred_df와 gt_df를 merget해주었다.
각각을 _pred와 _gt 라는 suffixes를 붙여 칼럼을 분화하여 합쳐주었다. 그 후, na를 채워주었다.
calc_overlap 함수를 통해 min_overlaps를 계산해주고
0.5 이상이 넘는 경우의 boolean 값을 potential_TP로 저장해주었다.
potential_Tp 및 집합 간의 차이를 활용해 TP, FP, FN을 계산하고 그를 통해 f1 score를 계산해주었다.
그리고 f1 score의 평균값을 리턴해주었다.
log 클래스를 작성해서 시간을 기록할 수 있게 해주었다.
파일 접근 모드에 대해서는 아래의 링크에서 잘 설명이 돼있다.
fopen() & fclose() - 파일의 접근 모드 (r, w, a, r+, w+, a+), 파일 입출력 모드, 대표적인 표준 입출력 함
fopen()함수와 fclose()함수 헤더파일 stdio.h fopen()함수 파일 스트림을 생성하고 파일을 오픈 fclose()함수 파일 스트림을 닫고, 파일도 닫기 함수 원형 함수의 원형 설명 #include FILE* fopen (const char..
codedragon.tistory.com
LRScheduler를 매개변수로 받는 함수를 작성해주었다.
클래스의 생성자 부분만 우선 가져왔다.
optimizer나 learning_rate, gamma, cycle 등 학습 조건을 설정해주었고
super()로 last_epoch의 클래스가 참조되게 해주었다.
이후 self.init_lr() 메서드를 호출하였다.

위의 클래스와 이어지는 구문이다.
init_lr은 param_group에서 lr(learning rate)를 불러와주는 메서드.
__init__ 생성자에서 호출된다.
get_lr은 step_in_cycle에 따라 lr을 다르게 리턴
step_in_cycle과 warmup_steps 에 따라 lr을 다르게 계산.
step은 epoch을 돌며 epoch 내에서 step을 계산해주는 함수.
cycle_mult를 적용해 cycle을 돌려주는 모습이다.
계산된 cycle과 epoch를 바탕으로 lr와 epoch을 갱신해주었다.

earlystopping 클래스를 작성해주었는데
patience를 활용하는 if 구문이 눈에 띈다.
epoch과 best_epoch의 차인 counter를 두어 patience를 넘었을 때
조건을 통과시키며 early stopping이 가능하도록 설정해준 모습이다.

mapping_to_ids는 mapping에 따라 text를 자르고 그 idx를 리턴해주는 함수.
is_head는 token의 길이와 그것이 '.,;?!'에 속하지 않는지를 확인해주는 함수.
get_offset_mapping은 token들의 index를 계산해서 리턴해주는 함수다.
[CLS], [SEP], [UNK] 등 special token 또는 다른 예외적인 경우들을 상정해서 메서드를 작성한 듯 보인다.

encode 함수다. text, tokenizer, data, labels_to_ids 등의 매개변수를 받아주었다.
tokenizer가 deverta-v 일 경우를 따로 고려해줬다.
get_offset_mapping 함수도 여기서 활용되었다.
encode_plus() 함수로 tokenizer 기반하여 text를 인코딩해주었다.
convert_ids_to_tokens()에 'input_ids'를 넣어 토큰들을 반환해주었고
이를 활용해 offset_mapping을 만들어주었다.
deverta-v가 아닌 경우에는 encode_plus 만으로 해결이 됐다.
discourse_start 가 data.columns에 있을 경우,
char_label로 discourse_start, discourse_end, discourse_type 등을 받고
'B-' 또는 'I-'의 NER 라벨의 고유 id 값 (discourse_type에 따른) 을 반환해서 token_label에 넣어주었다.
최종적으로 input_ids, attention_mask, token_label, offset_mapping 등을 리턴해주었다.

get_feat_helper 는 train_ids를 돌며 text 파일을 불러서 encode한 뒤, 그 리턴 값을 넘겨주는 함수.
get_feat는 이를 multiprocessing으로 처리해주는 함수이다.
data_path와 args.load_feat이 존재할 경우, pickle로 데이터를 불러와주었고
그게 아닌 경우에는 get_feat_helper 함수를 사용해 data를 병렬 처리하여 만들어주었다.
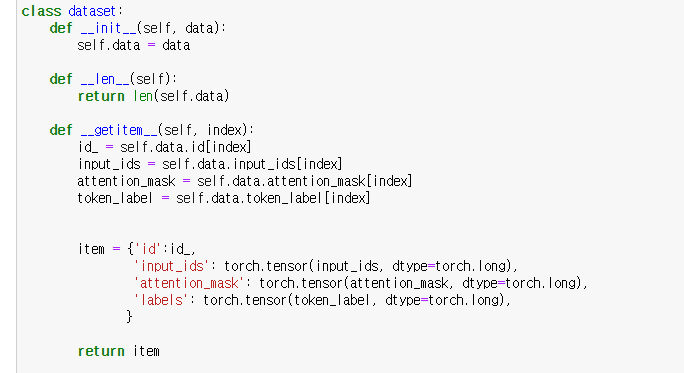
dataset 클래스는 data를 생성하고 index의 item을 돌려주는 처리를 하는 클래스.

padding을 넣어주는 feat_padding 함수를 작성해주었다.
padding 방향을 지정하는 padding_side에 따라 random_seed를 다르게 주었고
padding_side가 없는 경우에는 무작위로 random_seed를 주었다.
nonzero로 attention_mask에서 값이 존재하는 index를 가져오고
reshape(-1)로 차원을 줄여 mask_index에 저장해주었다.
index_select()로 mask_index의 index에 존재하는 값들을 불러주었다.
ids_length와 batch_length를 비교해서 truncate 혹은 padding을 해주었다.
random_seed가 0.33과 0.66을 기준으로 처리를 다르게 해주었는데
앞서 했던 padding_side에 따라 처리를 다르게 해주고자 했던 것 같다.
그외에는 add_length1을 랜덤하게 발생시켜 add_length와의 차이를 사용해 처리해주었다.

Collate는 앞서 만든 feat_padding 함수를 활용해 패딩을 해주면서
batch size에 맞게 배치를 만들어주는 클래스.
torch.stack()으로 output의 내용을 합쳐주고 torch로 변환해주었다.

model.eval()로 모델 평가에 돌입.
GradScaler()는 gradient values가 작을 경우,
underflow를 방지하기 위해 gradient를 scaling해주는 Gradient Scaling을 위한 함수.
torch.no_grad() 를 써 gradient tracking을 하지 않고
model_predict() 함수로 loss와 logits를 뽑아주었다.
logits를 갖고 accuracy를 계산하고 accuracy와 loss의 평균값을 저장해주었다.
evaluation이 끝났기 때문에 model.train()으로 mode를 변경해주었다.
discourse type에 따라 threshold를 설정하고 after_deal() 함수를 사용했는데
이를 통해 예측 결과를 뽑아준 듯하다.
loss와 accuracy, f1_score, pred 를 리턴해주었다.

train 함수 model, train_loader, test_loader, test_feat, test_df, args, model_path, log 등을 파라미터로 받았다.
optimizer롸 scheduler, es(EarlyStopping)을 설정하였고 여기서
앞서 살펴봤던 CosineAnnealingWarmupRestarts 함수와 EarlyStopping 함수를 활용하였다.
AWP 함수에 model, optimizer, adv_lr, adv_eps, start_epoch, scaler 등의 arguments를 받았다.
이 함수에 대해선 후에 다뤄보겠다.

위의 train 메서드에 이어지는 코드다.
model.train() 으로 train mode를 선언하고 train_loader의 배치를 루프문으로 돌려주었다.
input_ids, attention_mask, labels를 device로 전달해주었다.
torch.cuda.amp.autocast() 구문으로 automatic mixed precision training(float 타입을 유동적으로 변형시켜주는 것) 을 사용해줬다.
그리고 model 에서 loss와 logtis를 뽑아주었다.
zero_grad()로 gradient를 초기화하고 (다음 학습에 영향을 주지 않기 위해)
scaler.scale(loss).backward()로 loss를 gradient scaling 후 역전파시켜줬다.
f1_score가 0.64를 넘는 경우, awp 인스턴스의 attack_backward 함수를 실행했다.
clip_grad_norm 으로 parameters의 gradient norm을 모아주었다.
scaler.step(optimizer)는 먼저 optimizer의 할당된 파라미터들의 gradients를 unscales한 후,
gradients가 infs나 NaNs을 가지지 않을 경우, optimizer.step()을 불러 파라미터를 업데이트해준다.
gradients에 infs나 NaNs이 있을 경우, optimizer.step()은 skip 된다.
scaler.update()는 다음 iteration을 위해 scale을 업데이트 해주는 함수.
scheduler.step()은 learning rate scheduler를 호출하는 함수.loss를 저장해주고 step을 넘겨주었다.
Automatic Mixed Precision에 대해서는 아래 문서에 자세히 나와있다.
Automatic Mixed Precision examples — PyTorch 1.11.0 documentation
Shortcuts
pytorch.org

이어지는 train 메서드의 끝부분이다. 분석이 길어지다보니 나누게 되었다.
gpu tensor를 cpu numpy로 넘겨주기 위해 detach().cpu().nump()를 사용하였고
argmax로 value가 가장 큰 indices를 뽑아 pred에 저장해주었다.
labels을 뽑고 accuracy_score를 계산해주었다.
batch가 200개 돌 때마다 input_ids, attention_mask, labels, loss, tr_logits 등을 지우고 cache를 비워주었다.
accuracy 값만 남겨 log로 출력해주었다.
tr_loss_ 구문에서 tr_loss가 tr_accuracy로 잘못 써진 듯하다.
train_loader가 돌고 난 후 다시 한번 garbage를 모아주고 cache를 비워주었다.
tr_loss, tr_accuracy를 남겨주고 test 메서드의 리턴값들과 함께 출력했다.
es로 조건이 충족될 경우 early stopping을 걸어주었다.
best_model과 test_pred를 리턴해주었다.

train 메서드에 사용되었던 AWP 클래스이다.
f1_score가 0.64를 넘는 경우, attack_backward 메서드를 사용했는데
이는 모델 loss를 발생시키고 역전파시켜주는 함수였다.
f1_score가 0.64를 넘는 경우에 loss를 다시 발생시키고 계산하여 모델을 보완해주는 역할인 듯하다.
모델 취약점을 이끌어내는 Adversarial Attacks 방법론으로 보이는데 이에 대해서 추후 다루도록 하겠다.

_attack_step은 모델 loss와 logits을 구하기 전에 사용된 함수이다.
param의 gradients와 param.data의 표준을 저장한 뒤,
self.adv_lr * param.grad / (norm1 +e) * (norm2 +e) 의 r_at을 구해주고 param.data에 더해주었다.
그리고 backup_eps[name][0] 및 backup_eps[name][1] 와 비교하여 중간값을 도출했다.
_save는 self.adv_step의 루프문 전에 사용된 함수이다.
data 백업을 만들어주고 grad_eps와 backup_eps를 계산하여 저장해주었다.
_restore는 루프문을 빠져나오고 사용된 함수이다.
백업된 데이터로 데이터를 다시 복구해주었고 백업해놓은 공간을 비워주었다.

mapping_to_ids 함수는 text를 mapping에 따라 split한 후 그 index들을 리턴하는 함수.
get_sentence_split 함수는 text에서 시작과 끝 지점을 잡아 result로 저장해 리턴하는 함수.

word_decode 함수는 pred, b_pred, offset_mapping, text, key arguments 딕셔너리를 받는다.
먼저, b_pred의 값이 kwargs['begin_proba'] 이상이거나 pred의 이전 값과의 차이가 0.1보다 크면
pred_head에 해당 index의 mapping을 append 해줬다.
get_sentence_split()으로 문장을 나눠 sentence에 저장해주었다.
mapping과 sentence를 비교하며 offset_mapping, pred, b_pred, idx 등을 정렬해 저장해주었다.

이어지는 코드들도 offset_mapping에 관한 내용들인데
이전의 mapping과 예측값, idx등을 연속해서 사용해주었다.
np.mean(pred_)와 kwargs['min_proba'][0]을 비교하여
조건을 만족하는 mapping을 offset_mapping2로 따로 저장해주었다.
다시 offset_mapping2를 받아서 'begin_proba', 'min_sep', 'min_proba' 등의 조건을 두어
offset_mapping3으로 정리해주었다.
그리고 마지막으로 'min_length' 이하의 length를 가지는 mapping을 걸러주고
mapping_to_ids로 index를 반환한 후 저장, 리턴해주었다.

after_deal_helper는 train_ids_sub, labels_to_ids, segment_param을 매개변수로 받는 함수.
train_ids_sub의 attention_mask와 offset_mapping을 가져왔고
pred와 b_pred의 연산으로 그 둘을 재정의.
재정의한 값을 바탕으로 pred_type을 산출하고 id, discourse와 함께 딕셔너리로 받아 리턴.
after_deal은 multiprocessing으로 after_deal_helper를 병렬처리 해주는 함수.

model_predict 함수는 model, batch, model_length, max_length, padding_dict, padding_side, duplicate_cnt를
매개변수로 받는다.
batch_length를 정의한 후, batch를 불러 feat_padding 함수로 padding을 해주었다.
loops의 start와 end를 ids_length와 model_length, duplicate_cnt를 써서 정의해주었다.
모델 loss와 logits를 구해주고 preds를 도출했다.
그리고 losses의 평균과 pred_list를 리턴해주었다.

sorted_quantile은 array의 부분들을 뽑아 연산을 해주는 함수인 것 같은데 정의하고 이후에 따로 쓰지 않았다.
get_label은 mapping으로 구분한 pred_idx와 predictionstring의 true_idx를 비교하여
겹침의 정도를 나타내는 inter_rate를 도출하고 그것이 0.5를 넘을 때,
1, inter_rate, true_idx의 범위, mapping한 word의 범위를 리턴하는 함수.
inter_rate가 0.5를 넘지 않으면 0, 0, [-1, -1] 과 word의 범위를 리턴하였다.
맨 앞의 1과 0이 이 둘을 구분하는 역할을 하게 되겠다.
tuple_map은 offset_mapping을 돌며 threshold 기준으로 token index를 정렬해주는 함수로 보인다.

get_pos_feat은 text와 offset_mapping을 매개변수로 받는다.
paragraph_cnt는 '\n\n' 기준으로 text를 나누고 그 길이에 1을 더해 저장한 변수.
paragraph_th는 text에서 '\n\n'을 찾고 span()을 써 그 시작과 끝 지점을 튜플로 만들어서 저장한 변수.
paragraph_rk는 tuple_map 함수를 써서 paragrapch_th 기준으로 offset_mapping을 정렬해서 저장한 변수.
paragraph_rk_r 은 paragraph_cnt와 paragraph_rk 사이의 연산값을 저장한 변수.
루프를 돌면서 text에서 '\n\n', '\.\', ',', '\?', '\!' 을 찾고 시작과 끝 지점을 반환한 후,
이전 값과 비교하여 이어지는 index들을 sentence_th에 저장해줬다.
sentence_cnt, sentence_rk, sentence_rk_r 등도 paragraph에서 처럼 만들어주었다.
offset_mapping을 돌며 sentence_rk의 차이를 이용해 sentence_rk_of_paragraph도 만들어주었다.
sentence_cnt_of_paragraph는 paragraph_rk값을 비교해 sentence_rk_of_paragraph를 저장한 변수이고
sentence_rk_r_of_paragraph는 sentence_cnt_of_paragraph 에서 값이 존재하는 snetence_rk_of_paragraph를 빼준 값으로 결국 sentence_rk_of_paragraph 값의 index의 따른 차이를 이용해 만든 변수라 할 수 있겠다.
기존 변수의 index를 바탕으로 새로운 변수를 순차적으로 만들었다고 볼 수 있겠다.
그리고 만들어진 모든 변수들을 리턴해주었다.

TextModel은 모델을 정의한 클래스이며 생성자 메서드에서 모델 레이어를 설정해주었다.
deberta-v2-xxlarge 일 경우에는 필요한 처리를 따로 해주었다.
forward 메서드로 모델을 전파시키며 preds를 산출하고 logits를 계산해 리턴해주었다.
labels가 None이 아닌 경우에는 loss도 계산하여 전달하여 주었다.
get_loss 함수로 outputs와 targets를 비교하여 loss를 구해주었다.

get_args()는 프로그램에 사용할 인자들을 정의하는 함수이다.
parser.add_argument로 ArgumentParser에 arguments 정보를 채워주었다.
model로 longformer-base-4096 을 사용한 것을 볼 수 있다.
args와 args의 정보를 담은 log를 리턴해주었다.

see_everything은 seed를 설정해주는 함수.
random.seed, 환경 변수의 PYTHONHASHSEED, np.random.seed, torch.manual_seed, torch.cuda.manual_seed 등으로
seed를 넣어주고 코드가 재현 가능하게 해줬다.
그리고 Nondeterministic한 작업을 피하기 위해
torch.backend.cudnn.deterministic과 torch.backend.cudnn.benchmark 를 True로 설정해줬다.
아래 링크에 설명이 잘 돼있다.
Pytorch의 Reproducibility를 위한 설정들
같은 학습 데이터로 학습을 하고, 동일한 테스트 데이터로 테스트를 하였음에도 매번 실행해보면 모델의 학습 파라미터와 테스트 결과가 동일하지 않은 경우가 많다. 이는, 높은 수준의 재생산
tempdev.tistory.com
아래는 "__main__" 을 사용한 터미널 실행 코드.
get_args로 args, log를 불러들이고
seed_everything으로 재현 가능성을 확보했다.
Discousre_type을 정의하고 NER 규칙에 따라 I-, B-의 접미사를 붙였다.
그리고 고유한 id 값을 만들어 연결시켜주었다.
"kfold"를 활용해 train 데이터프레임과 test 데이터프레임을 나눠주었다.
k-fold를 적용한 데이터 프레임을 만들어주는 코드를 따로 보지 못한 것 같은데
위에서 train_folds.csv를 불러들이고 아래에서 "kfold"를 사용한 걸 보면 따로 만들어준 것 같다.
args.debug가 True일 경우, sample(frac=0.1)로 임의 표본 추출을 해줬다.
AutoTokenizer로 적합한 tokenizer를 load하고
get_feat 함수로 tokenizer를 적용해 데이터를 encoding해줬다.
train과 test 파라미터를 설정하고 dataloader로 batch를 생성했다.
모델을 생성하고 병렬 처리 선언 및 device 설정을 해줬다.
모델이 존재하는 경우에는 모델을 불러와서 test 함수를 돌려 loss, accuracy, f1_score, test_pred를 뽑았고
모델이 존재하지 않는 경우에는 train 함수를 돌려 model과 test_pred를 뽑아주었다.
그리고 모델을 저장해주었다.
후기 : 코드를 공부해보자고 시작했는데 생각보다 방대한 양이었다.
2위 코드만 리뷰해도 충분했을까 싶기도 했지만
구현 방법이 달랐기 때문에
이 코드까지 리뷰한 게 그래도 나름 의미있었던 것 같다.
이 코드가 왜 성능이 좀 더 좋았냐고 한다면 사실은 잘 모르겠다.
방법론은 2위 코드가 더 직관적인 것 같다.
이 코드는 직접 다 돌려보기도 어렵고 어디서 어떤 영향을 줬는지 가늠하기도 어렵다.
그래도 세부적인 조정을 많이 거친 느낌이 들어서 그런 데 들어간 노력들이 빛을 본 게 아닐까 싶다.
물론 머신의 가호도 있었겠지만 말이다. ㅎㅎ
덕분에 pytorch 구문이나 기계 학습 방법론에 대해 더 잘 알게 된 것 같아 만족이다.
앞으로도 꾸준히 해나가야지. (다짐)
'Data > 코드 리뷰' 카테고리의 다른 글
| [Happy_whale] EffNet Train & RAPIDS Clusters (0) | 2022.04.11 |
|---|---|
| [Happy_whale] EffNet Embedding cos Distance (0) | 2022.04.07 |
| Evaluating Student Writing_2nd Place Solution (0) | 2022.03.24 |
| Data Augmentation (CSV&TXT) using Back Translation (0) | 2022.03.15 |
| TensorFlow LongFormer NER Baseline (0) | 2022.03.15 |