🐳Whales&Dolphins: EffNet Train & RAPIDS Clusters
Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
www.kaggle.com
앞서 리뷰한 코드와 같은 사람이 작성한 코드다.
그래서인지 이해하기 수월했고 학습 과정까지 전 과정이 담겨있어서 좋았다.

라이브러리 import하고 색상 설정하는 부분.
cuml 라이브러리가 CUDA 호환성 문제로 import 되지 않아서
sklearn의 유사 함수를 불러왔다.
성능 차이가 있는 지는 모르겠지만 코드 실행에는 문제가 없었다.
line plot으로 loss를 그려주는 함수.
value text를 plot에 출력해주는 함수.
위에서 부터 차례로, dataset을 W&B artifactory에 저장해주는 함수.
W&B 환경에 data table을 만들고 유형에 따라 plot을 만들어주는 함수.
W&B 환경에 data table을 만들고 히스토그램을 만들어주는 함수.
학습의 Reproducibility를 확보하기 위한 코드.

Train, Test 데이터가 담겨 있는 folder path를 저장해주고
학습에 사용할 parameters 을 설정해주었다.
NO_NEURONS가 눈에 띈다.
csv 파일을 불러들이고 path 칼럼을 만들어주었다.
test는 이전 코드에서 만든 데이터프레임이다.


albumentations 파이프라인을 활용해 image를 augmentate 해주었다. (train)
open cv에서는 이미지를 BGR로 저장하기에 COLOR_BGR2RGB로 RGB 형태로 변환해주었다.
Batch shape를 뽑아주었는데
Image shape는 128 넓이 * 128 높이 * 3 channel size 의 이미지 3개가 한 batch에 담겨 있음을 나타내고
Target은 size 3의 1D tensor로 image의 target class 정보를 담고 있음을 나타낸다.
Albumentations Documentation - Image augmentation for classification
Albumentations: fast and flexible image augmentations
albumentations.ai

Generalized Mean(GEM) Pooling 모듈이다.
GeM Pooling은 아래의 Pooling 방법 중 하나.
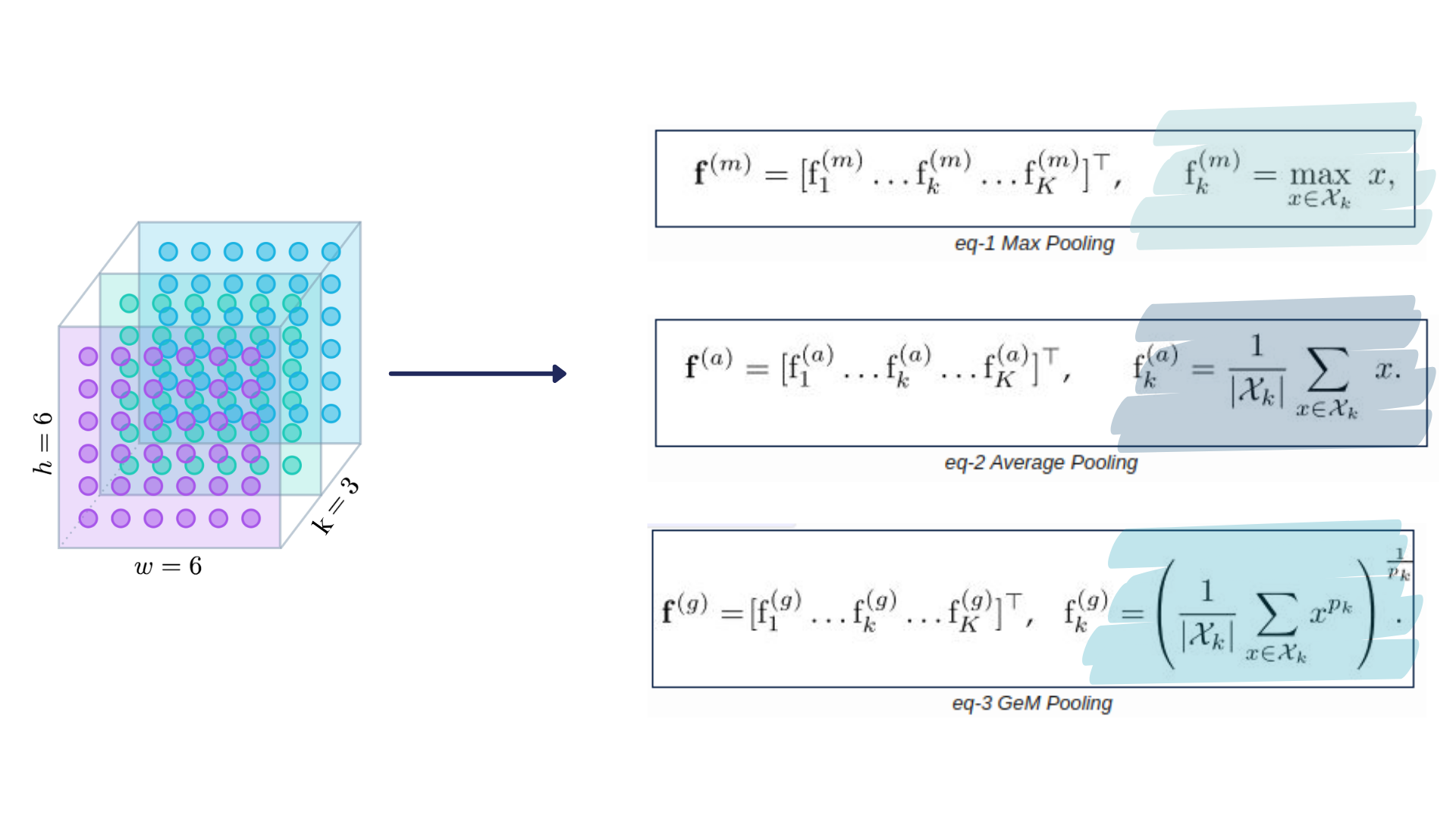
Pooling은 처리되는 데이터의 크기를 줄이는 공정이다.
영역 안에서 최대값이나 평균값, 또는 GeM에서 처럼 일반화된 평균을 구하는 방식으로 이뤄진다.
그리고 여기서 GeM Pooling을 쓰는 이유는 당연히 성능을 향상시키고자 이다.
하지만 항상 성능이 좋은 것은 아니라고 한다.
추가로, GeM Pooling의 파라미터인 Pk 값이 정해지거나 학습될 수 있기 때문에(역전파 때), GeM pooling 자체도 학습 가능하다고 한다. ( The pooling parameter pk can be set or learned, since this operation can be learned during back-propagation. In other words, GeM Pooling can also be trainable.)
초월 번역일까봐 내용을 가져왔다.
아래는 GeM pooling과 Average pooling을 비교 실험한 코드.
GitHub - amaarora/amaarora.github.io
Contribute to amaarora/amaarora.github.io development by creating an account on GitHub.
github.com

이번에는 ArcFace 모듈.
일반적으로 사용되는 softmax 대신에 loss function으로 사용하고자 작성되었다.
같은 클래스의 샘플들을 더욱 묶어주고 다른 클래스의 샘플들을 더욱 떨어뜨려주는 함수다.
가까운 클래스 사이의 구분을 명확하게 해준다. {softmax는 결정 경계(decision boundary)가 모호함.}
Papers with Code - ArcFace Explained
ArcFace, or Additive Angular Margin Loss, is a loss function used in face recognition tasks. The softmax is traditionally used in these tasks. However, the softmax loss function does not explicitly optimise the feature embedding to enforce higher similarit
paperswithcode.com

모델을 설계한 후, device에 전달하고 생성해주었다.
생성자 함수에서 create_model로 모델 생성 후 features 저장.
nn.Identity()는 placeholder identity operator로 input과 동일한 tensor를 output으로 전달해주는 함수다.
backbone 모델의 classifier나 global_pool을 사용하지 않기 위해서 혹은
추후에 새롭게 정의한 바대로 사용하기 위해서
nn.Identity()로 정의해주거나 덮어씌워준 것 같다. (추측)
Embedding layer를 설계해주고 arcface도 정의해주었다.
forward의 모델 흐름은 노트북 작성자가 만든 아래의 모델 schema를 보면 되겠다.


example_loader 내의 batch를 돌며
layers output의 shape를 확인하고
샘플 loss를 산출.
그리고 example을 지워준 후, gc.collect()로 가비지 수거.

model과 optimizer, scheduler, criterion 등을 담는 get_model_optimizer_criterion() 함수를 정의.
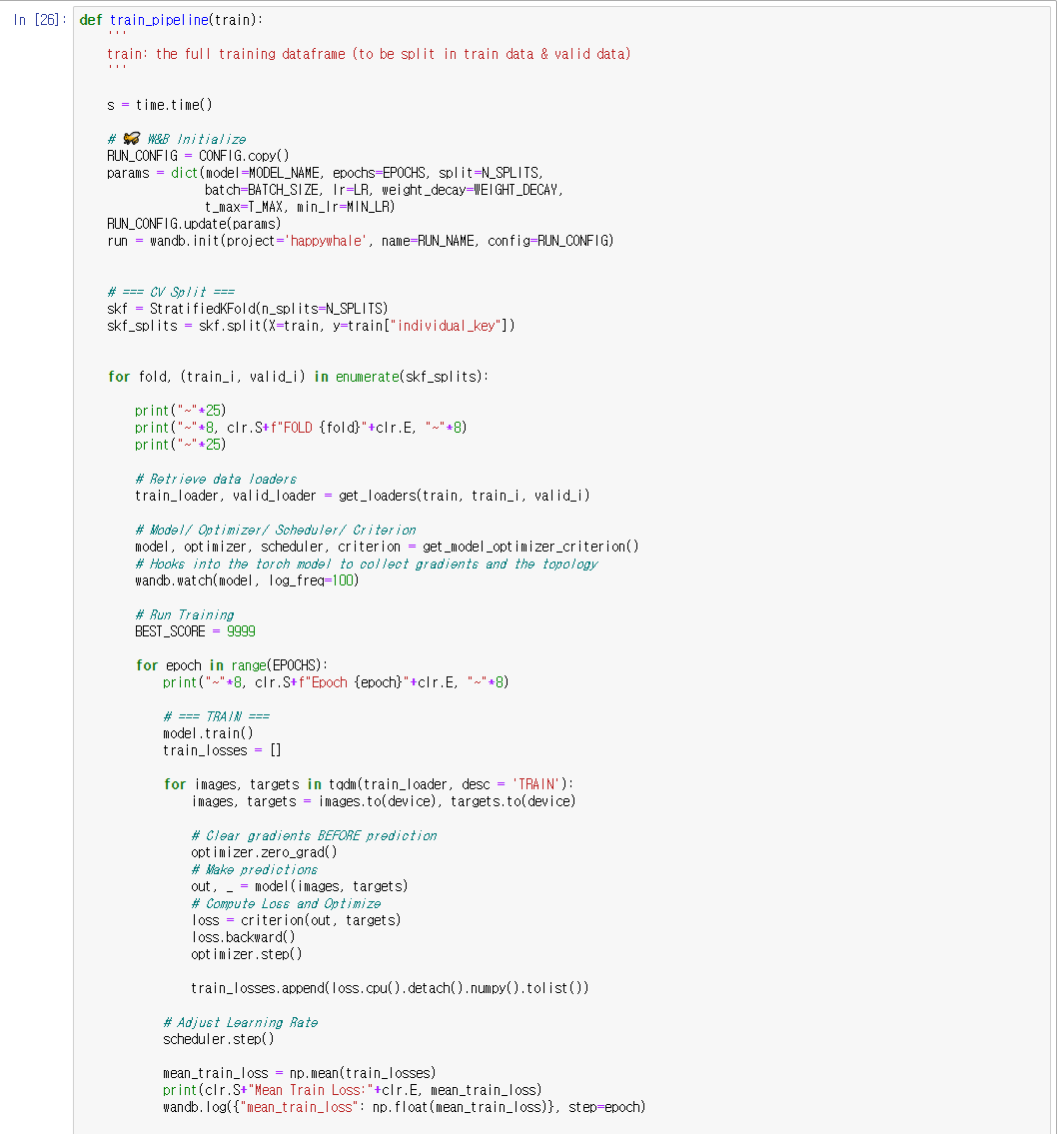
pipeline의 config 부분부터 train 부분까지.
CONFIG.copy()로 CONFIG를 가져왔고
파리미터도 가져와서 사용할 수 있게 dictionary로 만들어주었다.
params을 update()에 넣어 config를 update 해주었다.
wandb.init()으로 W&B에 초기화해주었다.
StrafiedKFold로 데이터를 나누어주었다.
get_loaders와 get_model_optimizer_criterion 함수를 써서
batch를 만들어주고 필요한 설정을 해주었다.
wandb.watch()로 model gradients와 topology를 남기도록 해주었다.
batch를 돌면서 images와 targets를 device로 보내고 model에 넣어 prediction을 뽑아주었다.
그리고 loss를 계산후, 역전파 해주고
optimizer.step()을 호출하여 역전파 단계에서 수집된 변화도로 매개 변수를 조정해주었다.
loss를 train_losses에 저장해주었다.
scheduler.step()으로 학습률을 조정해주었다.
train_losses의 평균을 구하고 W&B에 log를 넘겨주었다.

pipeline의 eval과 update 부분.
train과 유사한 방식으로 batch를 도는데 여기서는 preds를 뽑아주었다.
loss_graph를 그리고 W&B에도 plot을 만들어주었다.
mean_valid_loss가 BEST_SCORE 보다 낮을 경우, weights를 저장해주었다.
캐시를 비워주고 gc.collect()를 호출, wandb.finish()로 W&B 환경을 닫아주었다.

파라미터를 설정하고 파이프라인을 실행해주었다.
loss가 구해지고 plot이 그려지는 것을 볼 수 있다.

저장된 모델을 불러와서 image_embedding을 뽑아주는 작업을 해주었다.
후에 로컬과 W&B에 저장해주었다.

NearestNeighbors() 함수로 knn_model을 만들어 주었다.
k-NN은 k개의 가장 가까운 이웃들을 토대로 개체의 클래스(또는 집합)를 판정해주는 알고리즘이다.
참고로 나는 sklearn 라이브러리의 함수를 썼기 때문에 RAPIDS suite는 아니다.
image_embeddings에 모델을 fit해주고 distances와 indices를 뽑아주었다.
distances는 그룹 내의 각 point 간의 거리,
indices는 각 image의 index 열이라고 작성자가 주석을 달아놓았다.
distance와 indices를 활용해 split을 나눠주었고
또 split을 활용해image_embeddings에서 grouped_images와 grouped_embeddings를 뽑아주었다.

Cosine distance로 cosine_similarity를 계산해주는 함수.
heatmap을 그려주는 함수.

그룹을 하나 뽑아 히트맵을 그려보았다.
이전 글의 출력과 비교하자면,
data 기반의 학습이 이루어졌기 때문에 cosine_similarity 값이 보다 높아진 것을 확인할 수 있다.

또 다른 예시.

여러 embeddings를 가져와 그 평균을 이용하고자 하였다.
pretrained_model name 등의 파라미터들을 설정하였다.
model을 부르고 test 데이터셋을 바탕으로
embeddings를 뽑아 test_embeddings란 변수로 합쳐주었다.
그리고 test_embeddings의 평균을 내주었다.

저장된 embeddings를 불러 평균을 내주고 train_embeddings로 합쳐주었다.
knn_final_model에 train_embeddings를 fit해주었다.
그리고 test_embeddings를 집어넣어 distances와 indices를 뽑아주었다.
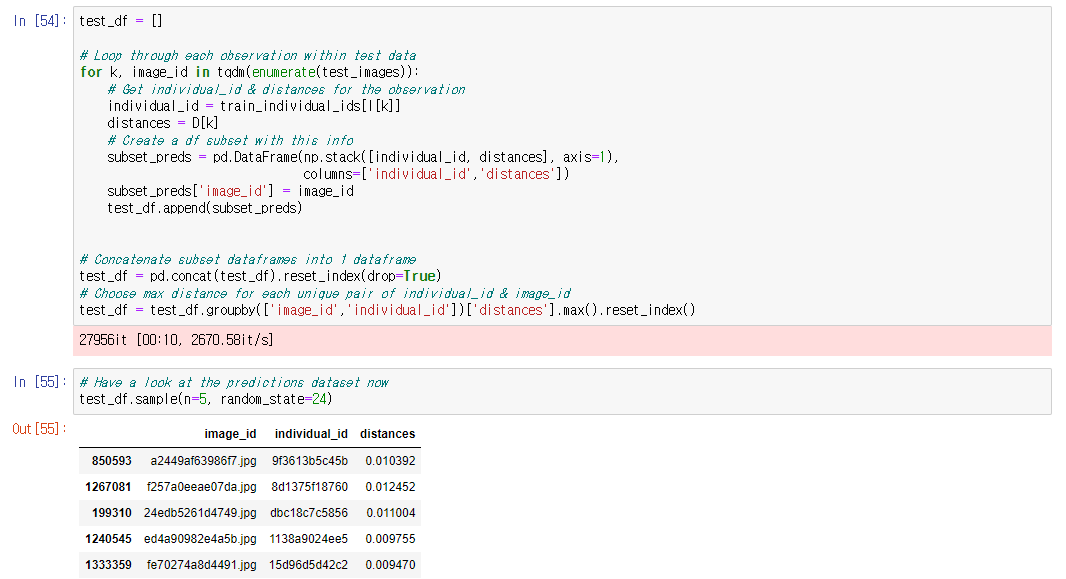
knn으로 뽑은 distances와 indices를
test_images에 적용시켜 test_df를 만들어주었다.

test_df를 가져와 image_id와 individual_id의 dictionary를 만들어주었다.
thresh 값을 설정해 distance와 비교하고 "new_individual"을 경우에 따라 뒤와 앞에 넣어주었다.
preds의 길이가 5에 맞춰지지 않는다면 sample_list의 id를 사용해서 값을 채워주었다.
'Data > 코드 리뷰' 카테고리의 다른 글
| [Happy_whale] EffNet Embedding cos Distance (0) | 2022.04.07 |
|---|---|
| Evaluating Student Writing_1st Place Solution (0) | 2022.04.03 |
| Evaluating Student Writing_2nd Place Solution (0) | 2022.03.24 |
| Data Augmentation (CSV&TXT) using Back Translation (0) | 2022.03.15 |
| TensorFlow LongFormer NER Baseline (0) | 2022.03.15 |