TensorFlow - LongFormer - NER - [CV 0.633]
Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
www.kaggle.com
캐글 공모전에 참가하면서 분석한 상위 링크의 코드를 리뷰하고자 한다.
NLP 문제에 대해 Longformer 모델을 TensorFlow 구문으로 학습한 코드이다.
Furthermore this notebook is one fold. It trains with 90% data and validates on 10% data. We can convert this notebook to K-fold or train with 100% data for boost in LB.
현재 노트북은 1 fold, K-fold 학습할 수 있다고 한다.

cuda gpu 설정, 토큰 불러오기, 모델 불러오기
LOAD_TOKENS_FROM을 None으로 할 경우, 토큰을 새롭게 산출.
LOAD_MODEL_FROM 을 None으로 할 경우, 새로운 모델을 학습.
Architecture 모델 불러오기

위 코드와 연결되어서
MODEL_NAME의 모델을 불러오고, tokenizer, config, backbone 모델 저장

auto_mixed_precision은 특정 float 32 연산을 float 16 연산으로 바꿔 수행함으로써 처리 속도를 높이고 효율을 높이는 옵션, 아래의 set_experimental_options에 관한 링크가 있다.
https://www.tensorflow.org/api_docs/python/tf/config/optimizer/set_experimental_options?hl=ko

Train 파일 불러오기.

AutoTokenizer로 Tokenizer를 불러오고
token과 attention, NER의 14개 클래스의 빈 배열을 각각 만들어주었다.
target 사전과 맵을 만들어주었다.

assert 구문, 행 간 차이를 이용해서 데이터가 오름차순이 아니라면 프로그램 중단.
ID의 수만큼 루프를 돌면서
name 이하 구문으로 train 파일을 불러오고 tokenizer 후,
input_ids와 attention_mask를 이전에 만든 빈 배열에 넣어줌.
offset_mapping으로 idx를 가져와
targets_b와 targets_i의 조건에 맞는 요소를 표시해줌. (NER 기반)
아래는 token을 새로 만들었을 때, 각 sequence의 길이를 표시한 것.
max_len을 1024로 설정한 것이 reasonable함을 확인할 수 있음.

targets 배열을 만들고 그 안에 targets_b, targets_i를 차원을 달리하여 넣어주고
마지막에는 B나 I 토큰에 해당하지 않는 O 토큰 차원을 np.max()를 활용해 만들어 넣어줌.
토큰을 저장하고 불러오는 방법.

token layer, attention layer를 만들어주고
config를 불러오고 backbone을 설계(base 모델 실체화).
backbone 위에 dense layer를 깔아주고 model 빌드 후 컴파일.
gpu 방식에 따라 모델 빌드.

epoch, batch_size, learning rates 등을 정의하고
callback 함수를 사용해 learning rate를 epoch 마다 다르게 줌.
여기에서는 마지막 epoch에서만 0.25e-5로 다르게 주었음.
노트북 작성자는 BATCH_SIZE를 8로 주었는데
필자는 GPU가 한개라 BATCH_SIZE를 4로 줄였음. (CV값에는 큰 영향이 없었음.)
random seed를 주고 train과 valid id를 나누어 주었음, 그 후 random seed 초기화.
불러올 model 이 있을 경우, model weights를 불러옴.
아니라면 model.fit()을 통해 모델을 학습 그리고 모델 weights를 저장.

model predict로 예측값을 저장하고 target map 딕셔너리를 만들어 줌.


이전과 같은 방식으로 토큰을 만들어 주고
공백이나 특수 문자가 아닌 문자가 있는 idx를 w 리스트에 넣어줌.
구분을 위해 1e6(백만, 그냥 큰 값)을 끝에 넣어줌.
offset mapping idx를 가져와 위에 만든 w 리스트와 비교하여
word idx와 token idx 맵을 만들어 줌.
preds values를 2로 나누고 pred로 저장.
만들어 놓은 map에 따라 prediction 값을 나눠주고
id, class와 함께 데이터 프레임으로 만들고 출력.

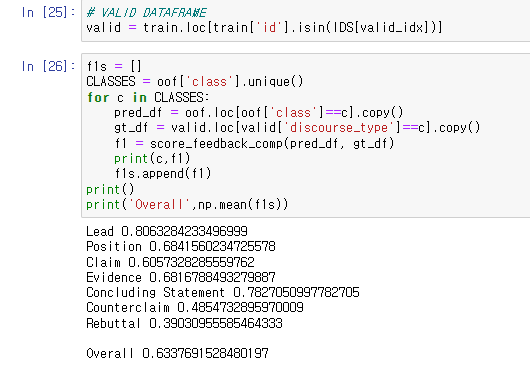
위의 함수는 prediction과 실제 값의 겹치는 정도를 산출하는 함수
아래 함수는 위 함수를 활용해 가장 많이 겹치는 값을 뽑아내고 micro F1 스코어를 산출하는 함수
아래 validation score는 노트북 작성자의 스코어
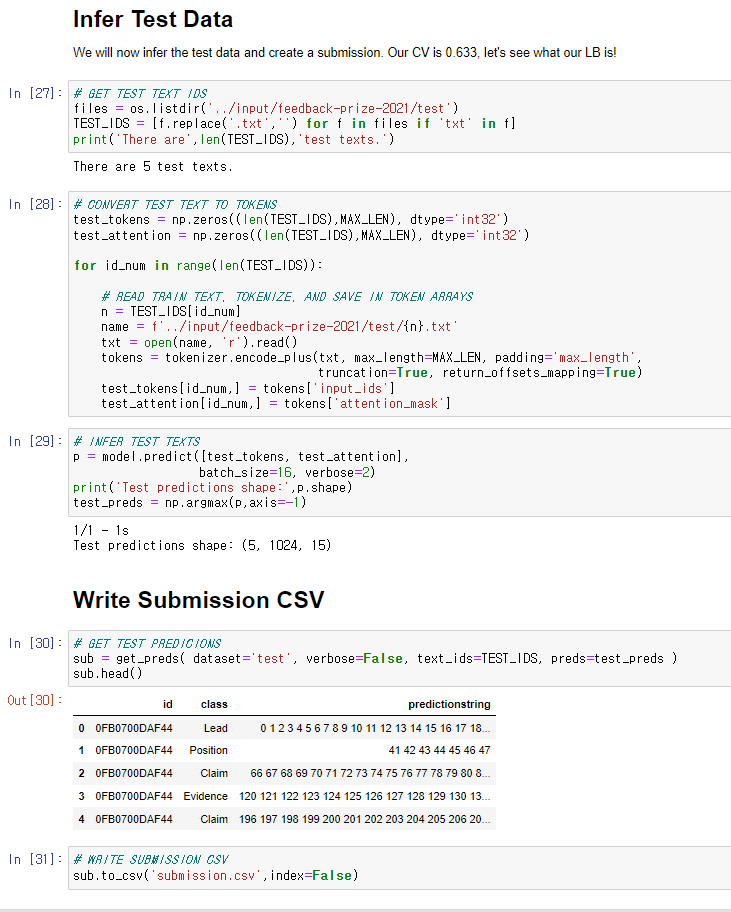
test data로 추론 작업 수행.
Submission 파일 만듦. 마무리.
'Data > 코드 리뷰' 카테고리의 다른 글
| Evaluating Student Writing_1st Place Solution (0) | 2022.04.03 |
|---|---|
| Evaluating Student Writing_2nd Place Solution (0) | 2022.03.24 |
| Data Augmentation (CSV&TXT) using Back Translation (0) | 2022.03.15 |
| two longformer is better than one (0) | 2022.03.15 |
| Pytorch data Samplers & Sequence bucketing (0) | 2022.02.28 |



