two longformers are better than 1
Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
www.kaggle.com
캐글 공모전에 참가하면서 분석한 상위 링크의 코드를 리뷰하고자 한다.
NLP 문제에 대해 2개의 롱포머 모델을 사용한 코드이다.

패키지 불러오기 + 캐시 비워주기

NER 토큰 맵 만들어주기 + 경로 설정(배치와 최대 길이)

input_ids(시작과 끝 부분에 특수 토큰 만들어주기) 와 attention mask 만들어주기

배치를 하나씩 가져와서 패딩을 달리 해주는 dynamic padding

tez.Model을 arg로 받는 함수.
AutoConfig를 활용해 model로부터 config를 자동으로 불러와 주고
변경할 파라미터를 따로 update,
여기에서는 output_hidden_states, hidden_dropout_prob, layer_norm_eps, add_pooling_layer
추후에 config 더 바꿔줄 수 있는 여지 있음.
완성된 config 파라미터를 통해 transformer 모델을 automodel로 자동으로 불러와주고
동시에 hidden_size와 num_labels를 기반으로 linear하게 output 계산
transformer 모델에 ids, mask를 통과시켜 sequence_output을 도출(last_hidden_state)
feed forward 구문.
이전에 계산한 output값과 tensor 곱을 통해 logits을 계산
softmax로 확률 계산
결과값과, 0, 빈 딕셔너리를 리턴

위의 함수는 test data를 불러와 test sample을 만들어주는 함수
offset_mapping은 token idx를 출력하는 옵션
아래 함수는 multiprocessing을 위한 함수,
주어진 id를 4등분한 뒤, 위의 함수를 불러와 test sample을 만들어줌.
꼭 parallel 작업을 수행하는 건가에 대한 의문이 있음
→ 이거 때문에 딜레이 됐던 거
→ 그래서 아래와 같이 parallel 구문을 없애주면

→ 이런 에러가 뜸

→ split ids 불러오는 부분에서 ids를 나눠줬기 때문.

→ 위 함수의 for 문을 제거해서 해결

하지만...

돌아가기에는 너무 큰 모델이었나...?
대책을 강구해봐야겠음.
→ dataloader num_workers 문제라는데 모델 코드에서 수정해야 하나 싶어서 모델 코드 열어보는 중.
→ 아래 model.py에 들어가서 num_workers=0 으로 다 바꿔줌

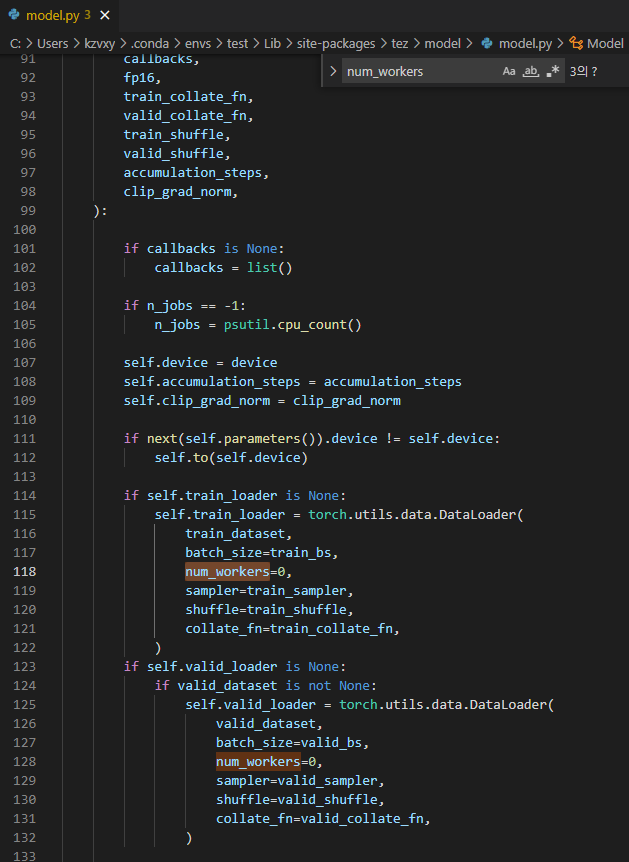

→ 그랬더니 돌아감

autoTokenizer로 model에 해당하는 최적의 토큰 불러옴.
만들어 놓은 prepare_test_data 함수로 데이터 샘플 만들어줌
collate로 배치 만들어주면서 dynamic padding
fold의 수만큼
sample, tokenizer를 써서 input_ids와 mask를 생성하고
모델 불러오고
두번째 모델의 weight를 불러옴
그리고 앙상블된 모델을 기반으로 예측값을 만들고
그것을 float 타입으로 변환해줌.
feedbackmodel 에서 불러온 모델은 large 4096이고
model.load로 longformer 1536과 longformer tez의
weights를 각각 불러오고 예측값을 계산해준 뒤 합쳐줌.
위의 모델에서 아키텍쳐를 만들고
아래 모델에서 weights를 집어넣는 것 (checkpoint)
모델 빌드에서 두 모델을 쓰기도 했고
만들어진 두 모델의 예측값을 합치기도 했음.

예측값을 토대로 score를 계산해주는 수식
raw_preds 이런 식으로 생김.
가장 높은 값과 가장 높은 값이 위치한 idx를 찾고 이것들을 리스트로 만들어줌
그리고 tt 라인으로 discourse_type으로 변환해주고
tt_score로 score를 저장해줌.

jn은 split된 문자들을 문자열로 합쳐주는 함수.
link_evidence 함수 해제
evidence인 데이터셋을 eoof 변수로 저장하고
class가 evidence가 아닌 데이터셋을 neoof 변수로 저장하였다.
thresh2를 26으로 따로 주기보다 구문 안에서 쓰고자 range(26,27,1)로 설정한 듯하다.
id가 없거나 class가 맞지 않는 데이터를 예외 처리해주고 q 변수에 저장하였다.
predictionstring을 잘라서 integer로 변환 후 맨 앞에 -1을 더하고(구분자) pst로 저장하였다.
predictionstring 토큰 값을 cur로 받은 후,
연속성과 id 기준으로 데이터를 정렬해준다.
그 후, class가 evidence가 아닌 neoof 데이터를 데이터 프레임에 병합해준다.
→ 데이터를 evidence 기준으로 정렬해주는 함수였다.

preds의 길이가 offset_mapping의 길이 보다 작을 경우 “0”으로 패딩
sample_pred_scores의 길이가 offset_mapping의 길이 보다 작을 경우 “0”으로 패딩
idx가 offset_mapping의 길이보다 작을 경우
offset_mapping의 idx를 가져와 start값으로 저장한다.
preds가 “0”이 아닌 값에 대해 label을 가져오고 나머진 “0”으로 label을 저장한다.
phrase_scores을 만들어 sample_pred_scores 값을 넣어준다.
라벨을 대조해서 0이 아닌 경우 label 앞에 I를 붙여주고 matching_label에 저장한다.
preds 값이 matching_label과 같을 경우
offset_mapping의 idx를 가져와 end 값으로 저장하고 넘겨준다.
phrase_scores을 만들어 sample_pred_scores 값을 넣어준다.
preds 값이 matching_label과 다를 경우 안쪽 while문을 벗어나준다.
locals는 특정 함수내에서 사용되는 로컬 변수들의 변수 이름 및 현재 값 등을 알고 싶을 때 사용하는 함수이다.
로컬 변수 중에 “end”가 있다면(offset_mapping으로 가져온 것)
start부터 end까지의 sample_text를 phrase에 저장하고
phrase_preds에 phrase, start, end, label, phrase_scores 변수들을 저장해준다.


아래 부분의 for문만 가져와 보았다.
word_start와 word_end, sample_text를 split한 것을 기준으로 시작과 끝 지점을 잡았다.
min 함수를 사용해 예외 처리를 해주었다.
label 기준으로 text 내의 토큰 idx를 가져온다 생각하면 된다.
그리고 label이 0이 아닐 경우,
phrase_score의 평균을 낸 후, proba_thresh를 넘는지 확인한다.
그 다음으로 split된 토큰들의 개수가 min_thresh를 넘는지 확인한다.
세 조건을 충족시켰을 경우, sample_id와 label, 그리고 phrase를 temp_df 리스트에 저장한다.
칼럼을 붙여주고 submission에 합쳐준다.
결국 예측값 중에서 임계값을 넘는 것만 취급해주는 것이라 score는 높아지는 게 당연한데
prediction을 더 잘하는 지에 대해서는 의문이 남는다.
'Data > 코드 리뷰' 카테고리의 다른 글
| Evaluating Student Writing_1st Place Solution (0) | 2022.04.03 |
|---|---|
| Evaluating Student Writing_2nd Place Solution (0) | 2022.03.24 |
| Data Augmentation (CSV&TXT) using Back Translation (0) | 2022.03.15 |
| TensorFlow LongFormer NER Baseline (0) | 2022.03.15 |
| Pytorch data Samplers & Sequence bucketing (0) | 2022.02.28 |



