Data Augmentation (CSV&TXT) using Back Translation
Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
www.kaggle.com
캐글 공모전에 참가하면서 분석한 상위 링크의 코드를 리뷰하고자 한다.
NLP 문제에 대해 Data Augmentation을 적용해 Train 볼륨을 늘리는 코드이다.

Data Augmentation을 위해 NLPaug 라는 라이브러리를 설치하고 관련 패키지를 불러온다.
nlpaug — nlpaug 1.1.10 documentation
© Copyright 2019, Edward Ma Revision bb2fc633.
nlpaug.readthedocs.io
nlpaug 라이브러리에 대한 문서는 위의 링크에 있다.

학습 데이터를 불러온다.

원래 텍스트에서 랜덤하게 뽑아 출력해보았다.
1. 유의어 기반 Augmentation
nltk 라이브러리 및 패키지들이 필요해서 다운받아주었다.

Augmentation을 수행하는 코드는 위의 두 줄이다.
추후에 여기서 소개하는 Augmentation 방법들을 비교하는 코드가 있으니
당장에 출력문을 원문과 비교하지는 않겠다.
2. Word2Vec 기반 Augmentation

단어를 벡터로 변환해 벡터 거리 인접도를 기반으로 Augmentation 작업을 수행하였다.
GoogleNews 사전 기반으로 작업한 것을 볼 수 있다.
그렇다.
Augmentation은 간략하게 기존 문장을 같은 의미의 다른 문장으로 치환하여
의미는 같지만 형태는 다른 데이터셋을 만들어주는 작업이다.
3. Contextual Embedding 기반 Augmentation

Contextual Embedding은 간략히 말하자면 문맥을 고려한 embedding 방법론이다.
단어의 sequence까지 고려해주는 방법이며 Roberta 모델을 사용하였다.
4. Back Translation 기반 Augmentation
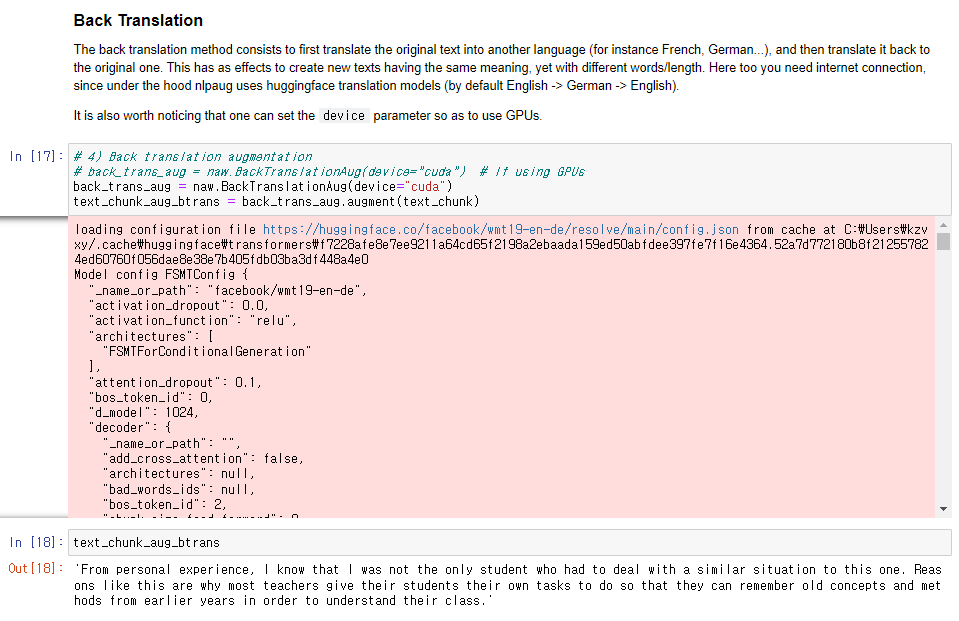
Back Translation은 텍스트를 다른 언어의 텍스트로 번역 및 치환하였다가
다시 원 언어의 텍스트로 번역 및 치환하여 변환해주는 방법론이다.
이 코드에서 사용하는 방법론이고 GPU를 사용할 수 있다.
5. 결과 비교

Synonym에서는 단순히 단어를 변환하는 것이기 때문에 문맥에 맞지 않는 단어가 등장함을 볼 수 있다.
Word2Vec에서는 Synonym 보다도 문맥에 더 어울리지 않는 단어들이 종종 등장함을 볼 수 있다.
Contextual Embedding(Roberta)에서는 앞선의 두 방법론 보다 결과가 나아보이지만 수식 구문이 많고 문장이 불완전함을 볼 수 있다.
Back Translation에서는 문장이 형식 상으로는 문제가 없어보이지만 완전한 번역이 이루어지지는 않았음을 볼 수 있다.

노트북 작성자는 실험적으로 데이터를 5개만 뽑아서 Augmented 데이터셋을 만들어 보았는데
나는 공모전에서 준 Train data 전체를 가지고 데이터셋을 만들어보았다.
거의 2일이 소모된 작업이었다.


데이터셋을 정리하고 각각의 파일로 저장해주는 코드.

데이터를 확인하고 전체 데이터셋을 저장함으로써 마무리.
'Data > 코드 리뷰' 카테고리의 다른 글
| Evaluating Student Writing_1st Place Solution (0) | 2022.04.03 |
|---|---|
| Evaluating Student Writing_2nd Place Solution (0) | 2022.03.24 |
| TensorFlow LongFormer NER Baseline (0) | 2022.03.15 |
| two longformer is better than one (0) | 2022.03.15 |
| Pytorch data Samplers & Sequence bucketing (0) | 2022.02.28 |



