The 🤗 Datasets library - Hugging Face Course
Introduction In Chapter 3 you got your first taste of the 🤗 Datasets library and saw that there were three main steps when it came to fine-tuning a model: Load a dataset from the Hugging Face Hub. Preprocess the data with Dataset.map(). Load and compute
huggingface.co
오늘은 chapter 5 내용을 리뷰하고자 한다.
1. Data 불러오기

데이터 로드 및 확인, field를 통해 어디에서 data를 가져올지 지정(json 형식)

이렇게 딕셔너리를 통해 가져올 수도 있고 압축 파일 자체를 가져올 수도 있다.

url을 통해서 가져오는 것 역시 가능하다.
2. 데이터 편집하기
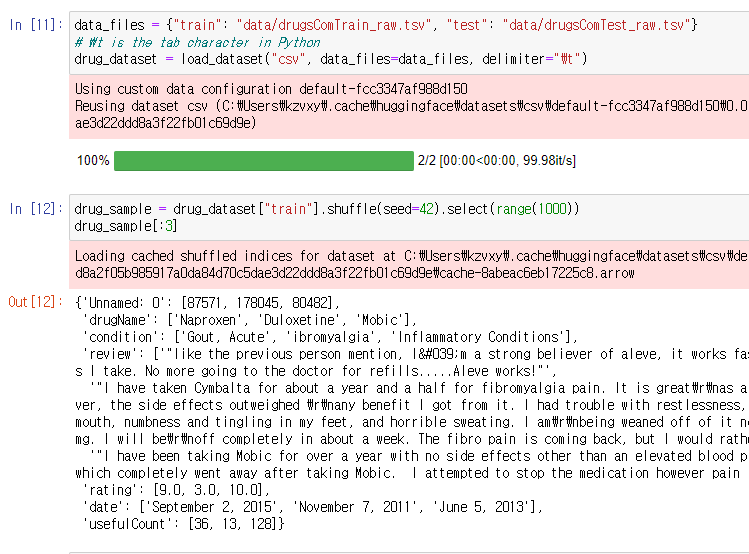
data 편집을 위해 새로운 데이터 셋을 가져왔다.
delimiter는 식별자인가 구획자이다.
shuffel에 seed를 넣어서 재사용이 가능하다. 1000개를 뽑아왔다.

unnamed를 가진 데이터셋의 길이가 본래 데이터셋의 길이와 같은지 비교해준 후,
unnamed 칼럼명을 rename_column을 통해 바꿔주었다.

NaN 값이 있기 때문에 제거해줌.

대문자를 소문자로 일괄 변형해줌. course에서는 이 단계를 먼저 수행했다가 NoneType 에러가 나서 위의 NaN을 제거 해주는 작업을 하는 식으로 진행하였다.
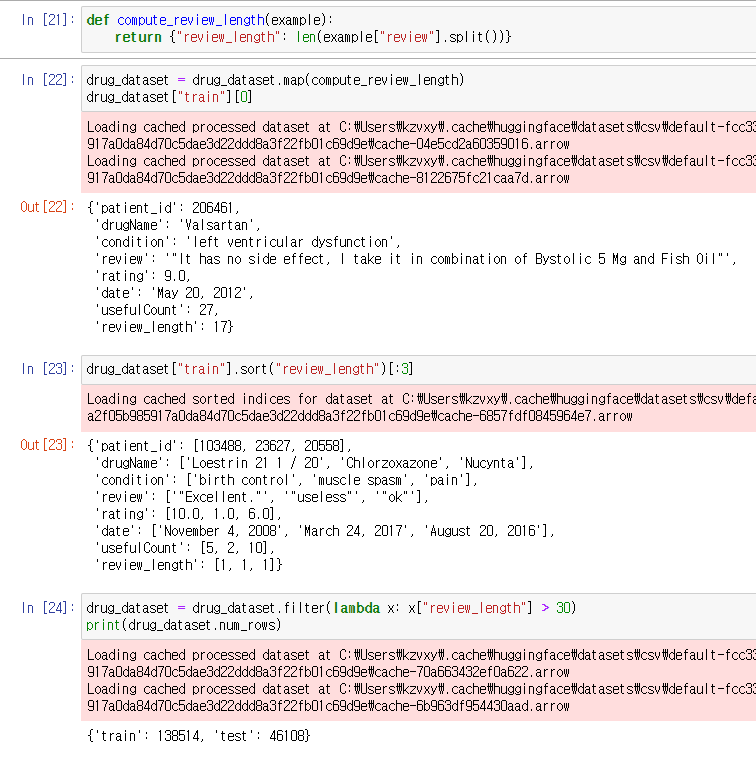
Review_length라는 새로운 Column을 만들어주었다.
그리고 review_length의 값이 30이 넘는 데이터만을 취해주었다.
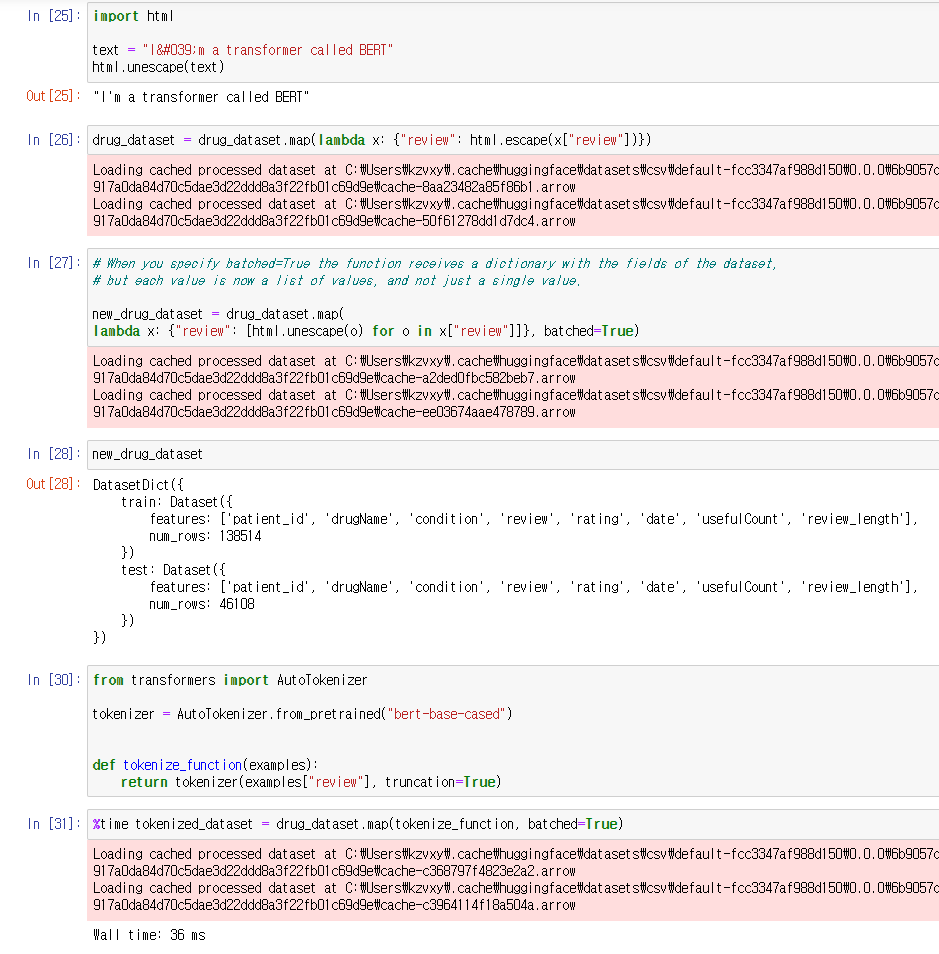
먼저, Html 문자들을 unescape와 map 함수를 사용해 일괄 처리해주었다.
여기서 map 함수의 batched=True 옵션의 장점에 대해 얘기했는데
values를 개별로 받는 것이 아니라 리스트형식으로 받아 처리를 빠르게 해준다고 한다.
tokenizer에도 처리 속도를 올려주는 use_fast라는 옵션이 있는데 이건 default가 true이니 그대로 내버려두면 된다.
%time을 통해 걸리는 시간을 체크할 수 있음.


return_overflowing_tokens는 max_length를 넘어가는 chunk를 반환할 것인지 결정하는 옵션
return_overflowing_tokens가 true 이기 때문에
drug_dataset과 tokenized_dataset의 사이즈가 달라져 오류 발생.
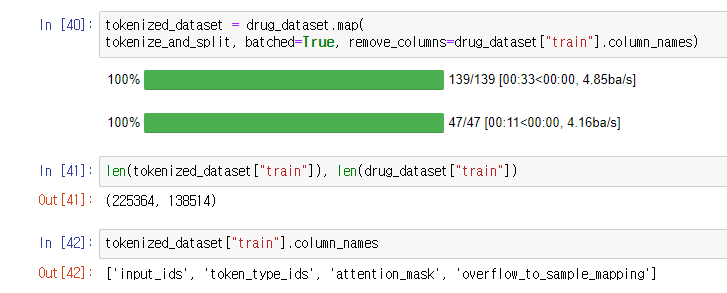
위와 같이 remove_columns 옵션을 통해 해결하거나,


여기에서 설명하듯이 overflow_to_sample_mapping 필드의 값이 리턴되도록 해주면 된다.

set_format을 통해 pandas형식으로 작업이 가능하다는 내용이다.

from_pandas로 판다스형식으로 받아올 수도 있고
reset_format으로 다시 포맷을 돌릴 수 있다.

train_test_split()을 통해 Validation set을 만들어주었다.

데이터 형식에 따라 데이터를 불러오고 저장하는 법을 설명했다.
3. 빅데이터 다루기


위의 데이터가 zstandard 라이브러리를 통해 압축된 것이라 설치 후 코드를 진행해주어야 한다.
참고로 커널 재시작해주어야함. ㅠㅠ

램 사용량을 보여주는 라이브러리와 코드
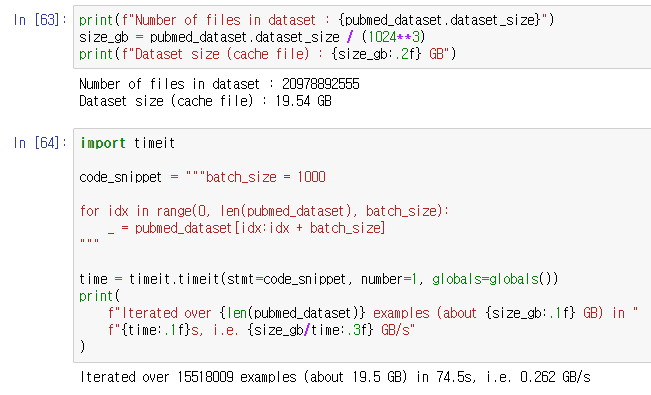
데이터 사이즈를 확인하고
또 iteration에 얼마만큼의 시간이 소요되는 지를 확인하였다.

Streaming 옵션을 통해 데이터를 Streaming mode로 load해 iterabledataset으로 처리할 수 있다.
큰 용량의 데이터의 작업에 용이한 옵션이다.
next()와 iter() 함수로 첫번째 요소에 접근이 가능하다.

빠른 처리를 위해 map함수를 사용할 수도 있다.

seed와 buffer_size를 지정할 수도 있다. seed를 잡기 위해선 buffer_size를 설정해야 한다.

처음 5개의 값을 받는 take 함수.

샘플을 건너뛰는 skip 함수를 통해 train, validation 을 나눈 모습이다.
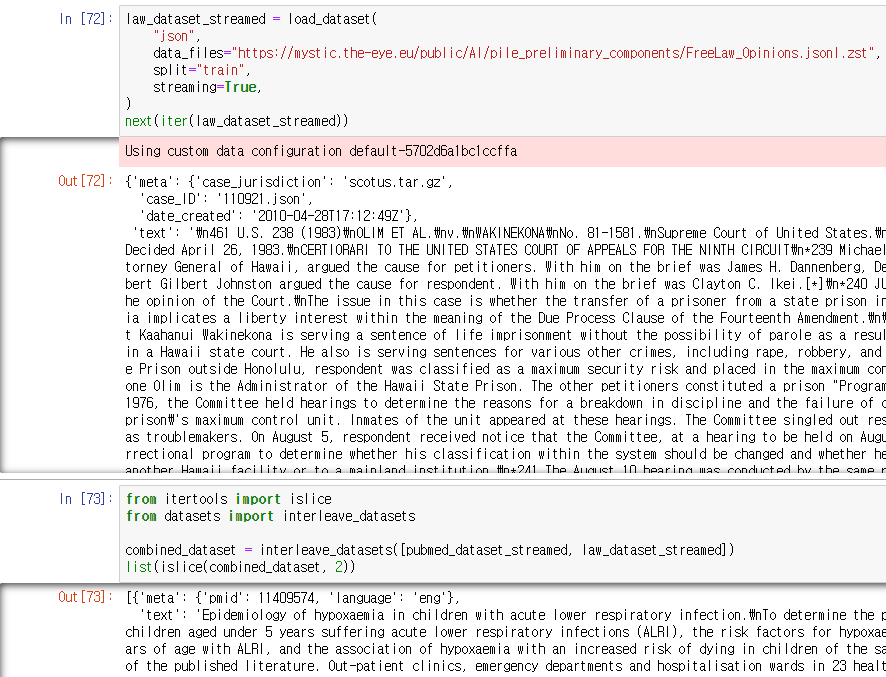
interleave_datasets 함수를 통해 IterableDataset 리스트를 하나의 IterableDataset으로 만들 수 있다.
islice로 example들을 뽑을 수 있다.

링크를 통해 데이터셋을 Streaming mode로 불러오는 것을 다시 한번 보여주었다.
4. 데이터 셋 만들기
The 🤗 Datasets library - Hugging Face Course
Sometimes the dataset that you need to build an NLP application doesn’t exist, so you’ll need to create it yourself. In this section we’ll show you how to create a corpus of GitHub issues, which are commonly used to track bugs or features in GitHub r
huggingface.co
이거 스킵함.
5. FAISS를 사용한 의미론적 탐색
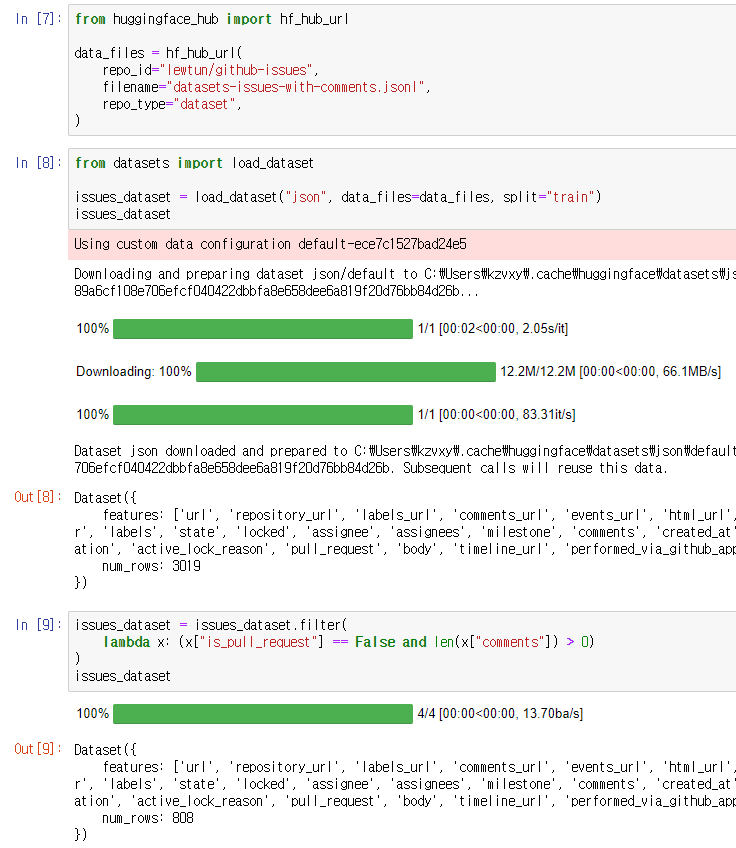
데이터 셋을 불러오고 데이터 필터링

불필요한 칼럼을 제거해주고 pandas로 포맷 변경
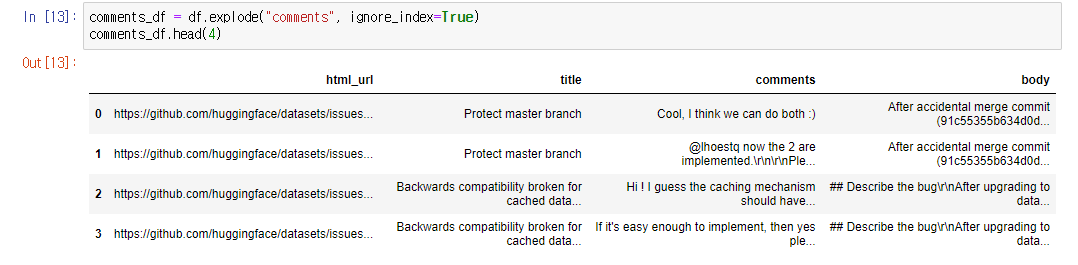
리스트로 들어간 commets를 나누어서 그에 해당하는 row를 추가해줌

comments를 나눈 후 다시 포맷을 데이터셋으로 되돌리고
comment_length 칼럼을 추가해 그것을 기준으로 데이터 필터링

마지막으로, title, body, comments의 텍스트들을 합쳐서 리턴한 text 칼럼을 만들어줌.
의미론적 탐색(Semantic serach)에 적합한 체크포인트를 가져와 model 빌드까지 해줌.

token embedding을 cls pooling해주는 함수를 정의하고
토크나이저부터 cls pooling까지 일괄처리해주는 함수를 정의함.
그리고 테스트 후에, map 함수로 일괄처리함. FAISS사용을 위해 numpy로 변환


FAISS는 Facebook AI Similarity Search였다.

faiss 설치 후, add_faiss_index로 FAISS index를 만들어줬다.
faiss-cpu랑 faiss-gpu 둘 중 하나 설치해야 된다길래 일단 cpu로 설치했다.
그리고 question_embedding 작업 수행 및 테스트(shape 확인)
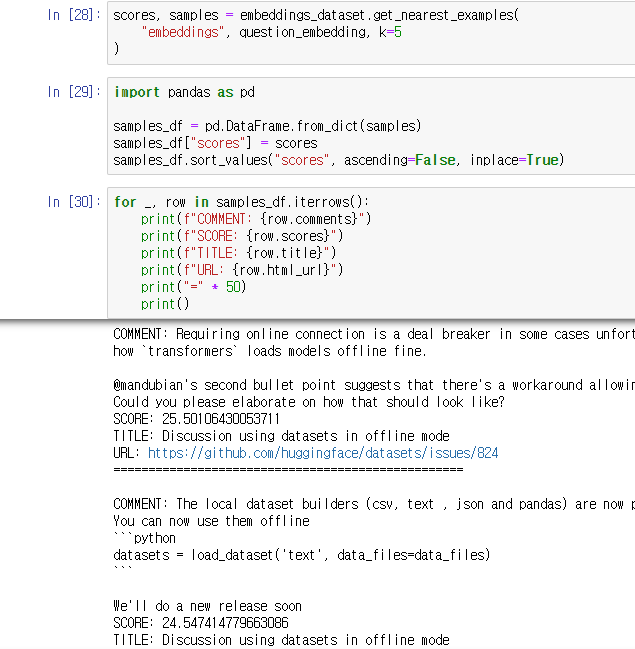
FAISS 스코어가 높은 코멘트들을 리턴하며 마무리
'Data > Information' 카테고리의 다른 글
| Hugging Face, Token classification (0) | 2022.03.16 |
|---|---|
| Huggig Face, Tokenizers (0) | 2022.02.25 |
| Hugging Face, Hub와 Repository 활용 (0) | 2022.02.22 |
| Hugging Face, pretrained models 불러오기 (0) | 2022.02.22 |
| Hugging Face, fine-tuning 까지 (0) | 2022.02.22 |



