Fine-tuning a pretrained model - Hugging Face Course
Now we’ll see how to achieve the same results as we did in the last section without using the Trainer class. Again, we assume you have done the data processing in section 2. Here is a short summary covering everything you will need: Before actually writi
huggingface.co
최근 허깅페이스의 코스를 학습 중이다.
허깅페이스는 NLP 문제들을 쉽게 해결할 수 있게 도와주는 API이자 HUB라고 보면 되겠다.
위는 허깅페이스의 코스 링크이다.
그리고 여기서는 코스를 따라서 Finetuning을 하는 Full code 리뷰를 캡쳐와 함께 간략하게 하고자 한다.
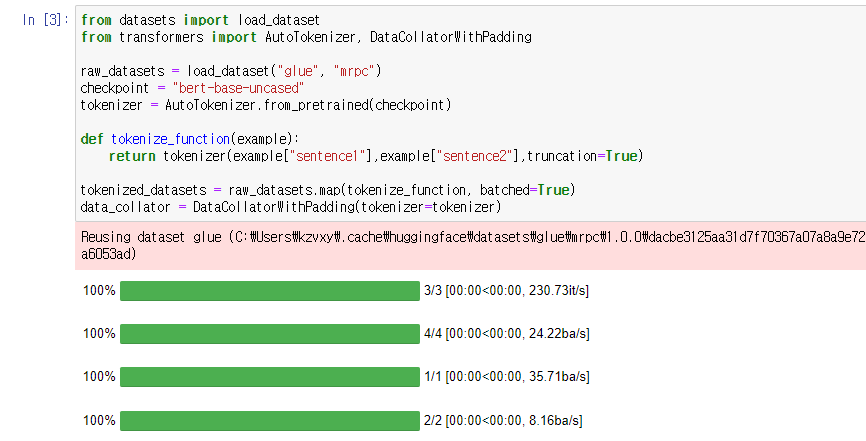
첫 번째 스탭으로 datasets과 transformers 라이브러리를 불러온다.
라이브러리가 없다면 pip install로 설치하면 되겠다.
load_dataset은 허깅페이스의 데이터셋을 불러오는 패키지이며
AutoTokenzier는 checkpoint에 따라 적합한 토크나이징을 수행해주는 패키지이다.
마지막으로 DataCollatorWithPadding은 Dynamic Padding(batch (전?) 단계에서 padding)을 하게 해주는 패키지이다.
glue와 mrpc 데이터셋을 불러오고
bert-base-uncased 체크포인트 기반으로 토크나이져를 설정한 후,
함수 이하의 내용을 함께 처리해주는 map 함수를 사용하여 토크나이징을 한다.
그리고 마지막으로 data_collator를 정의하며 dynamic padding을 준비해준다.
※ 데이터나 아키텍쳐, 체크포인트 등을 허깅페이스 허브에서 찾아서 변경할 수 있다.

Architecture과 checkpoint에 대한 HuggingFace의 설명이다.
아키텍쳐는 모델의 골격이고 체크포인트는 그 골격에 들어갈 weights의 집합이다.
그리고 모델은 아키텍쳐를 의미할 수도 체크포인트를 의미할 수도 있는 편하게 쓰는 용어이다.

배치를 반복하기 전에 형식에 맞게 컬럼을 제거 및 변경해준다. 포멧도 torch로 변경해준다.

학습과 평가를 위한 DataLoader를 정의해준다.
DataLoader는 sample들을 pytorch tensor들로 변환시켜주고 연결시켜주는 함수이다.
아래 코드로 배치를 확인할 수 있다.

모델을 정의하고 준비해준다.
AutoModelForSequenceClassification은 라이브러리 내의 적합한 모델을 불러오는 패키지이며
여기에서는 이전에 정의한 "bert-base-uncased"에 맞게 모델을 불러와준다.
아래 경고는 bert가 짝이 되는 문장을 분류하는 테스크에 pretrained 되지 않아서
pretrained model의 헤드가 버려지고 새로운 헤드가 추가되기 때문에 출력되는 것이다.

위의 14번 라인은 model에 배치를 한 번 던져봐서 test하는 것이고
아래 15번 라인은 AdamW를 optimizer로 사용하겠다는 뜻이다.
그 후 16번 라인에서 scheduler를 정의해주었다.
본격적으로 train에 들어가기 전에 learning rate와 optimizer를 정의해준 것이다.
"linear"는 learning rate를 linear로 쓰겠다는 것을 의미한다.
epochs와 train_dataloader의 곱만큼 training을 돌려줄 것이다.

Gpu 사용을 설정해주었다.

tqdm 패키지를 사용해서 train 진행을 가시화해주었다.
train_dataloader 안의 배치들을 하나씩 돌려주었고
loss.backward()를 통해 loss를 역전파시켜주었다.
※ 손실 함수(loss function)는 (output, target)을 한 쌍(pair)의 입력으로 받아, 출력(output)이 정답(target)으로부터 얼마나 멀리 떨어져있는지 추정하는 값을 계산한다. 또한, 역전파는 입력층에서 출력층으로 향하는 순전파와 반대로 출력층에서 입력층 방향으로 계산하면서 가중치를 업데이트해가는 방법.
optimizer.step()을 통해 backword()로 gradients가 계산된 후 파라미터들을 업데이트해준다.
그리고 정의해둔 스케쥴러를 불러내 learning rate를 업데이트해주고 학습.
마지막으로 optimizer.zero_grad()를 통해 gradient들을 초기화시켜준다. (각 epoch의 gradient들이 누적되지 않기 위해서)
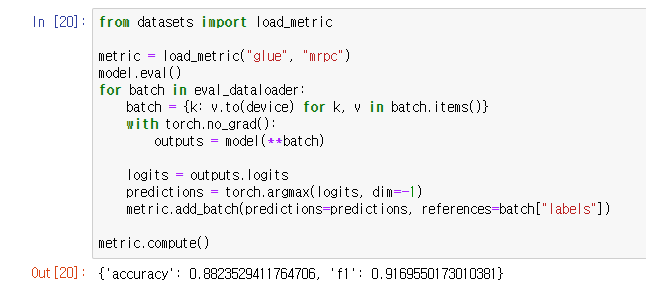
검증 단계에서 glue와 mrpc 데이터셋의 metric을 불러와서 비교해준다.
torch.no_grad()는 gradient 연산을 disable시켜주는 함수.
argmax함수는 최대값의 index를 반환해주는 함수. dim -1은 열의 차원을 제거한다는 의미.
그 후 metric에 predictions를 쌓고 compute()를 통해 평가 지표를 계산해준다.
결과값은 달라질 수 있는데 앞서 설명한 대로 모델의 헤드가 새롭게 초기화되기 때문이다.
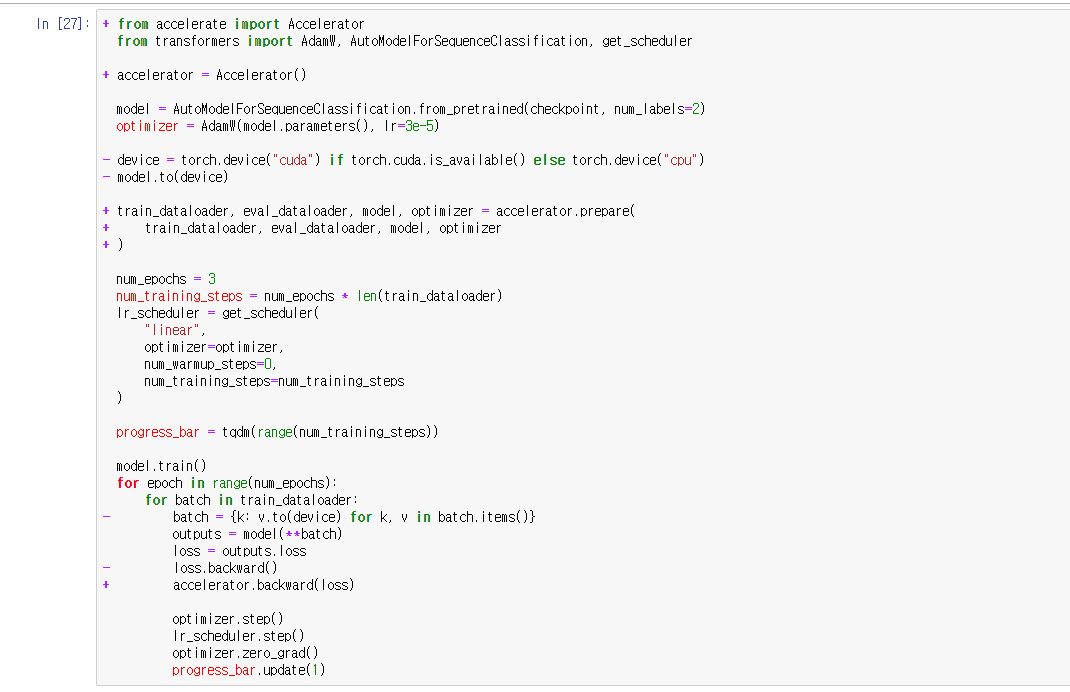
추가로 분산 학습을 도와주는 Accelerator 패키지를 적용한 코드이다.
Accelerator가 디바이스를 다루는 것부터 loss를 다루는 것까지 도와준다.
프롬프트에서 혹은 노트북 내에서 추가적인 코드를 입력하는 부분도 있는데
필요하다면 링크에서 직접 참고하면 좋을 것 같다.
'Data > Information' 카테고리의 다른 글
| Hugging Face, Token classification (0) | 2022.03.16 |
|---|---|
| Huggig Face, Tokenizers (0) | 2022.02.25 |
| Hugging Face, Datasets (0) | 2022.02.24 |
| Hugging Face, Hub와 Repository 활용 (0) | 2022.02.22 |
| Hugging Face, pretrained models 불러오기 (0) | 2022.02.22 |



