The 🤗 Tokenizers library - Hugging Face Course
Introduction In Chapter 3, we looked at how to fine-tune a model on a given task. When we do that, we use the same tokenizer that the model was pretrained with — but what do we do when we want to train a model from scratch? In these cases, using a tokeni
huggingface.co
코스 6에 해당하는 내용
1. 기존 토크나이저로 새 토크나이저 학습시키기
데이터셋을 불러오고 사용할 데이터를 확인.
generator를 활용해 토크나이저를 학습시킬 말뭉치(corpus)를 만들었다.
맨 위의 주석 처리된 라인은 리스트로 만들지 말라는 거고
아래의 보기와 같이 generator("( )")로 만들라는 것이다.
메모리를 잡아먹지 않고 효율적으로 쓸 수 있기 때문.
코스에서 yield 구문을 활용한 함수도 따로 작성해주었다.
아래는 generator에 관해 설명해놓은 블로그 글
python generator(제너레이터) 란 무엇인가
Python Generator 먼저 python docs 의 generator 에 대한 정의를 보자. generator A function which returns an iterator. It looks like a normal function except that it contains yield statements for pr..
bluese05.tistory.com
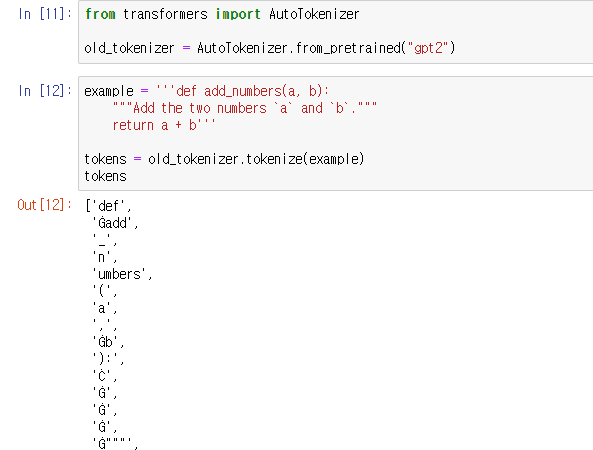
기존의 토크나이저를 통한 토크나이징.
문자들이 개별적으로 처리된 것을 볼 수 있다.
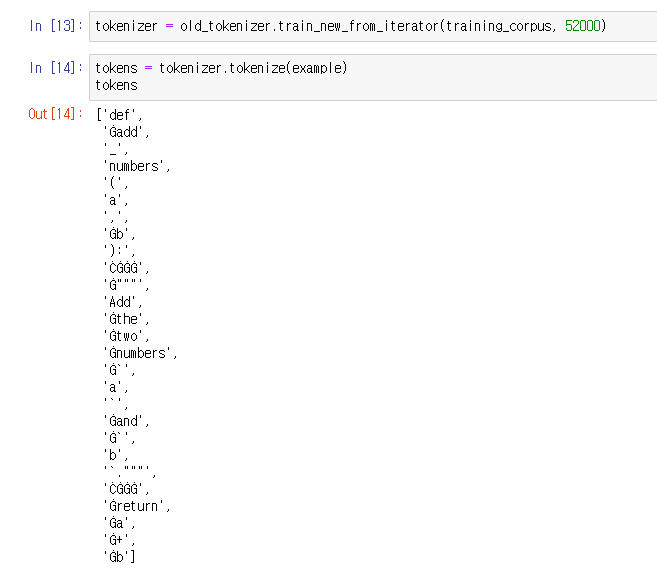
train_new_from_iterator() 를 통해 만든 토크나이저로 예제 문장을 처리한 결과
학습한 corpus에 맞게 토크나이저가 처리된 것을 볼 수 있다.
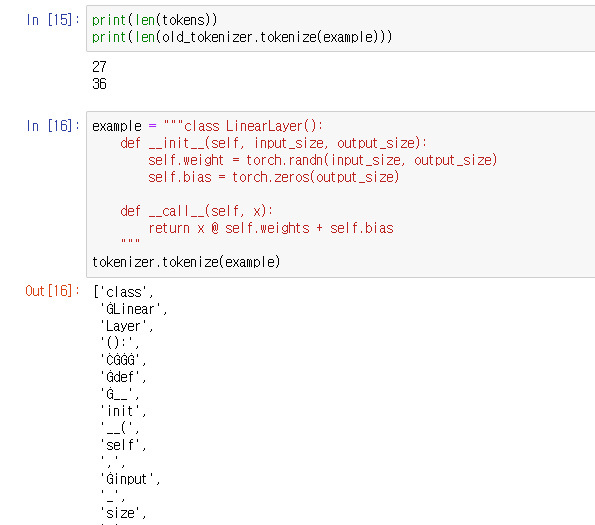
기존 토크나이저와 차이가 있음을 다시 한번 확인하였다.

그리고 새롭게 만든 토크나이저를 가볍게 저장.
2. Fast tokenizer의 사용
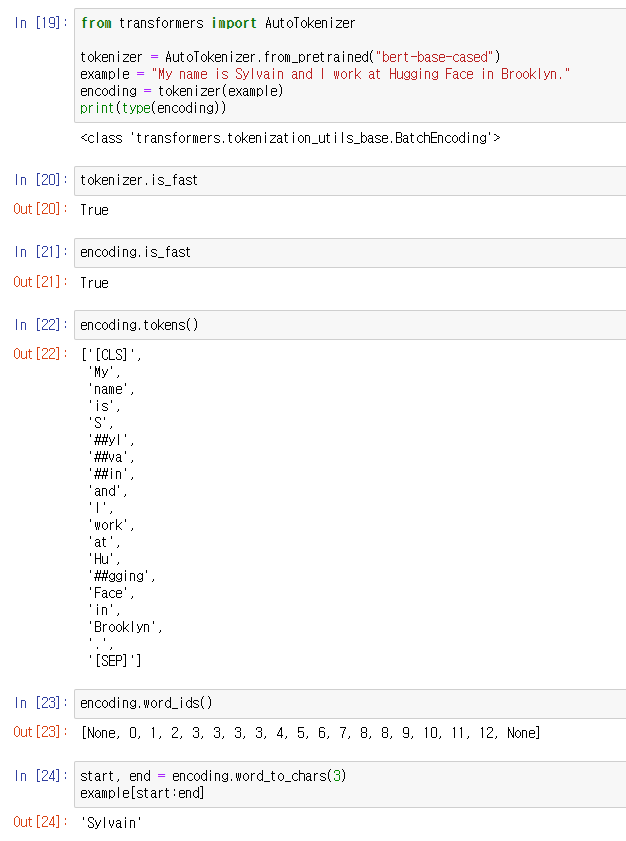
fast tokenizer의 개념에 대한 설명
idx를 가져오는 offset mapping 기능이 있어서
아래와 같이 단어를 idx로 불러올 수 있다.
빈칸이 많거나 특수문자 등이 있는 문장의 토크나이징에 효과적이다.
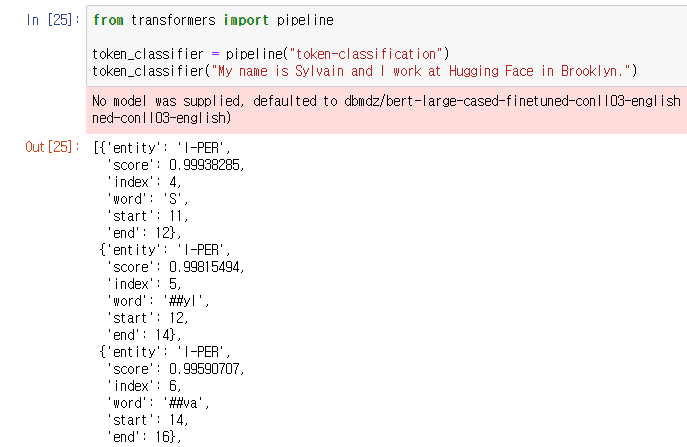
transformer 라이브러리로 pipeline을 사용해 token-classification을 수행하여
NER로 토큰을 분류해주었다.
NER은 Named entity recognition로 사람, 장소, 조직 등의 entity를 찾아
Beginning, In, Out으로 라벨의 시작과 사이 그리고 라벨 외의 것으로 분류해준다.
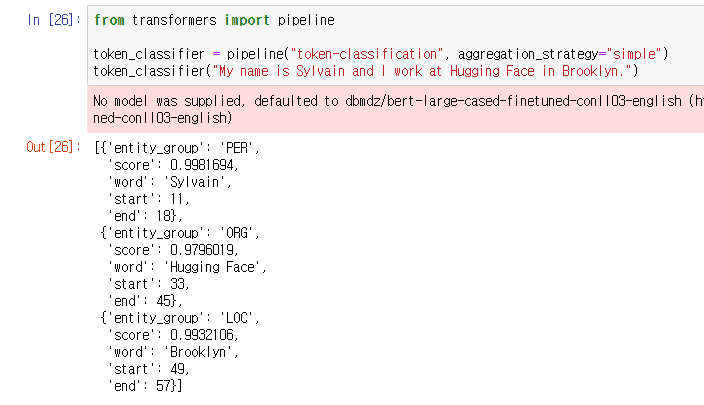
simple 옵션을 통해 평균값으로 entity만을 분류해줄 수 있다.
first(첫 번째 토큰의 score), max(각 entity 내 토큰들 사이의 최고 score) 등의 옵션이 더 있다.
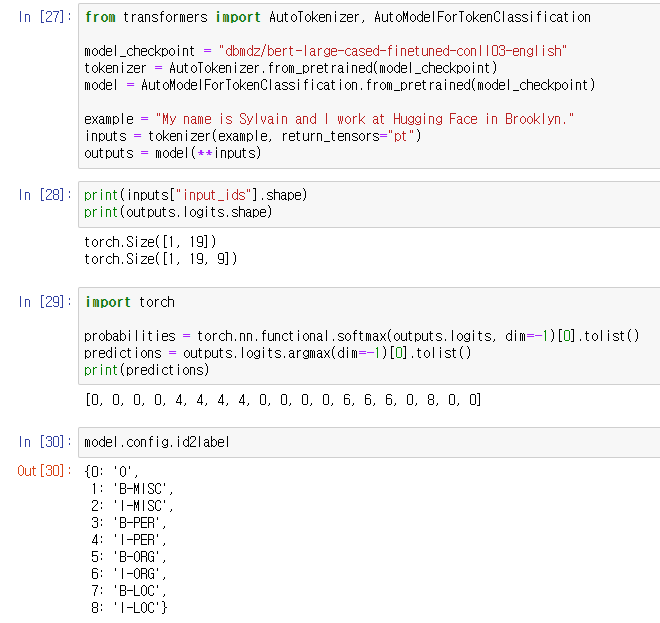
파이프라인이 아니라 모델을 빌드하는 방법으로 작업을 수행하였다.
AutoModelForTokenClassification 패키지가 token 기반의 classification 작업을 처리해준다.
19개의 토큰으로 이루어진 1개의 시퀀스 배치에 모델이 9개의 다른 라벨들을 가지고 있으니,
output 텐서는 1,19,9가 된다.
softmax로 logit들을 확률값(probabilities)로 바꿔주고
argmax로 예측값을 가져왔다.
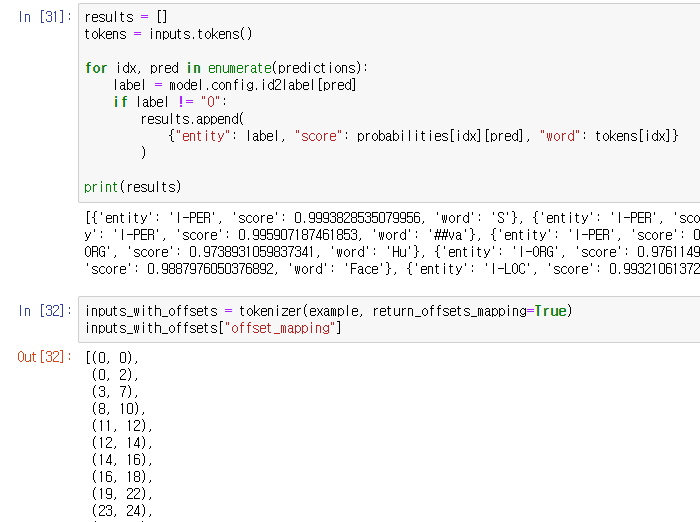
위는 NER 처리된 기반으로 entity와 score, 해당 word를 출력한 것이고
아래는 entity기반의 idx를 가져온 것이다.
NER 방식에는 IOB1과 IOB2가 있어
B와 I 라벨이 방법에 따라 다를 수 있다.
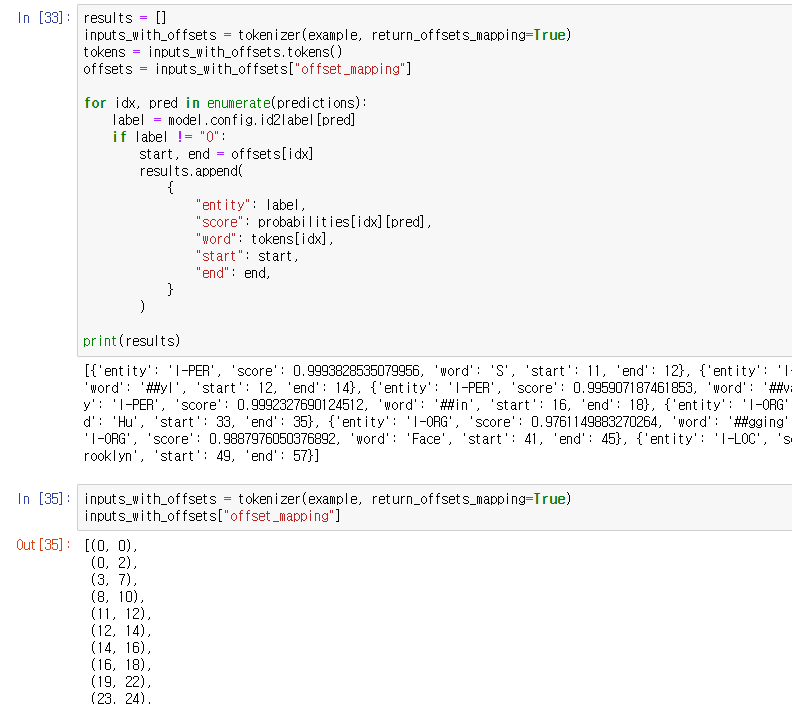
tokenizer에 return_offsets_mapping 옵션을 줘서 idx를 함께 출력한 것.
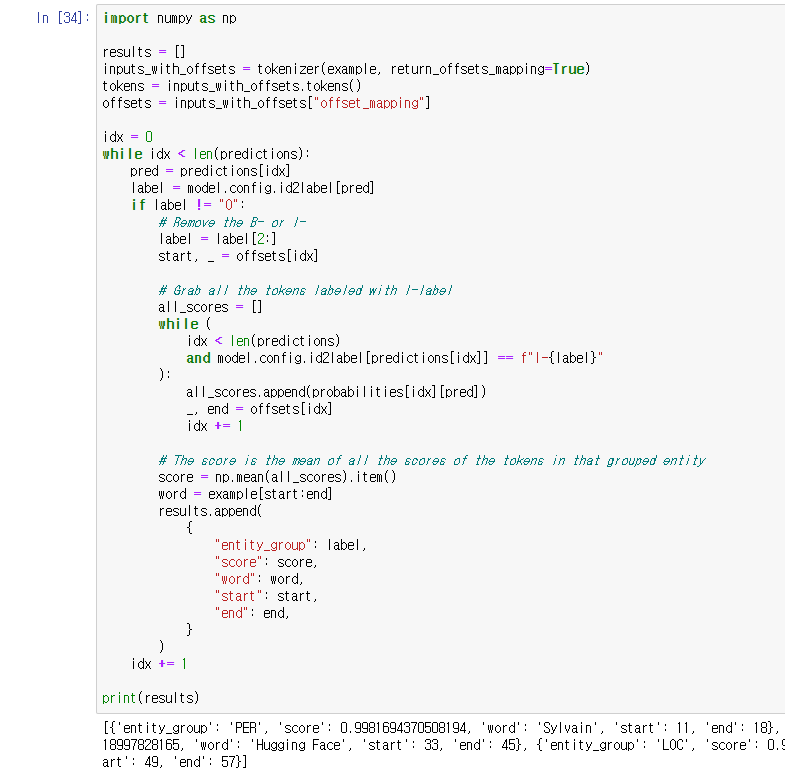
위에서 한 바와 같이 entities를 그룹화한 것.
label을 판별해서 평균값으로 score를 구하고 리턴해주는 방식.
3. Question Answering Pipeline
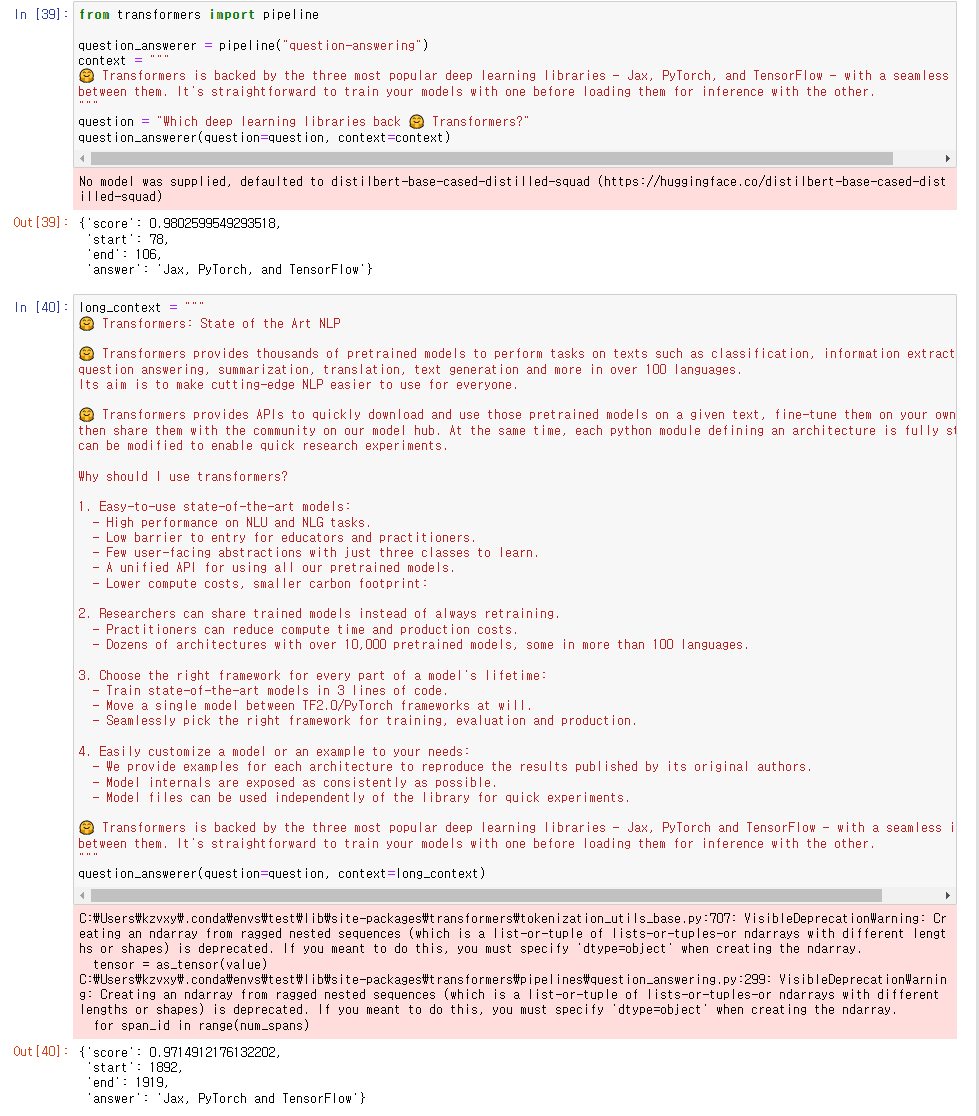
model maximum length 보다 긴 텍스트에서도 잘 작동하는
Question Answering Pipeline에 대해 알아보자.
checkpoint는 QuestingAnswering에 default로 사용되는
distilbert-base-cased-distilled-squad 체크포인트.
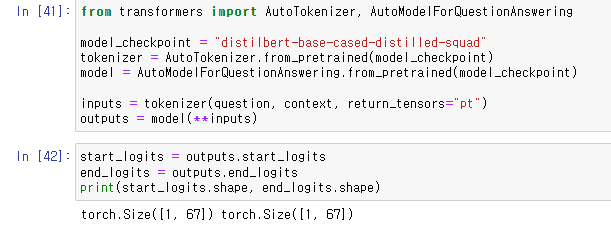
다른 모델들과 다르게
이 모델은 answer의 첫 토큰과 마지막 토큰을 계산하는, 총 두 개의 tensor of logits를 리턴해준다.
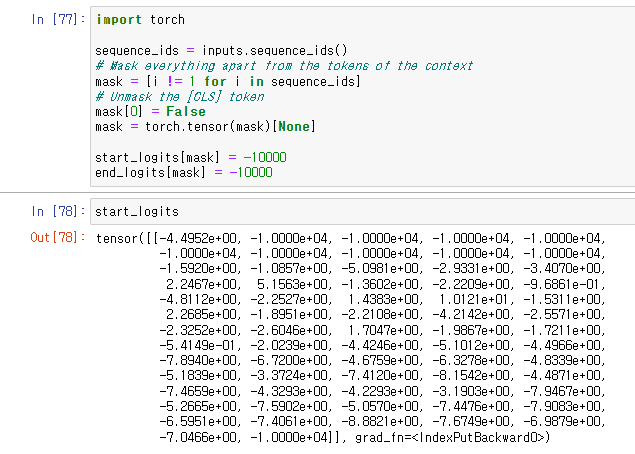
context에 포함되지 않는 indices들을 mask해주기 위해 mask tensor를 만들고
mask할 logit들에 큰 값의 negative 값을 부여했다.
CLS 토큰은 사용하기 때문에 unmask해줬다.
아래는 그 이유, 어떤 모델들에서는 cls토큰이 context 안에 answer가 없음을 나타내는데 사용하기 때문.

mask 후에 softmax를 사용해 확률값을 계산해주었다.
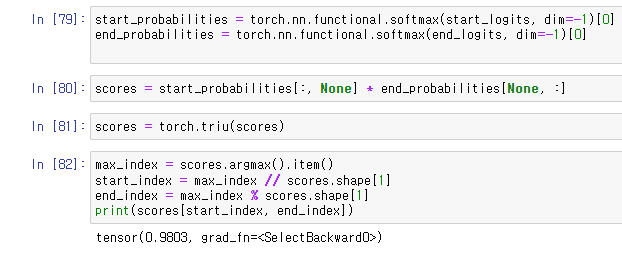
softmax로 확률값을 계산하는데
start_index가 end_index보다 높을 경우를 mask하기 위해서
torch.triu()를 사용해 위쪽의 tensor만 가져오도록 해주었다.

그리고 index값을 도출하는데 tensor가 flattened되었기 때문에
floor division // 과 modulus % operations를 사용해주었다.
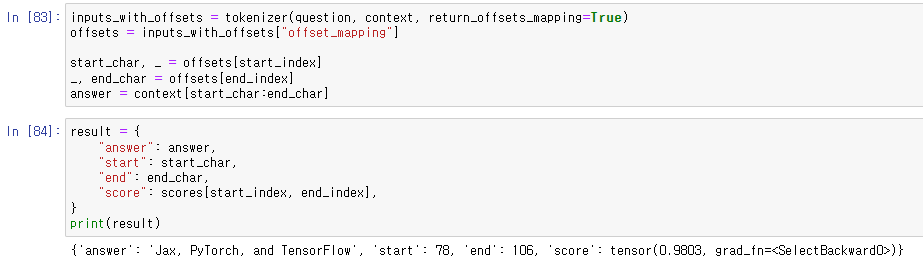
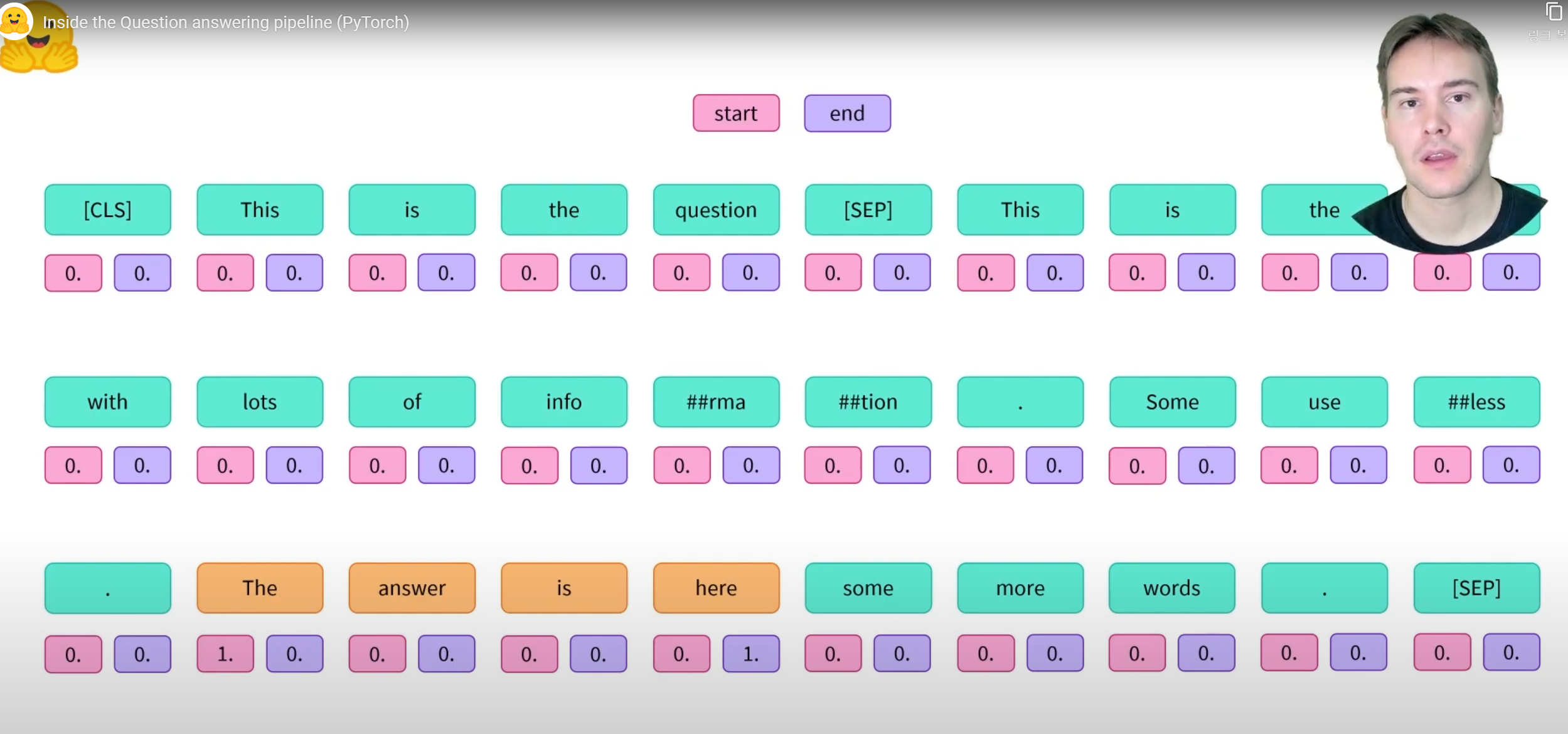
이전에 했던 것과 마찬가지로 시각화.
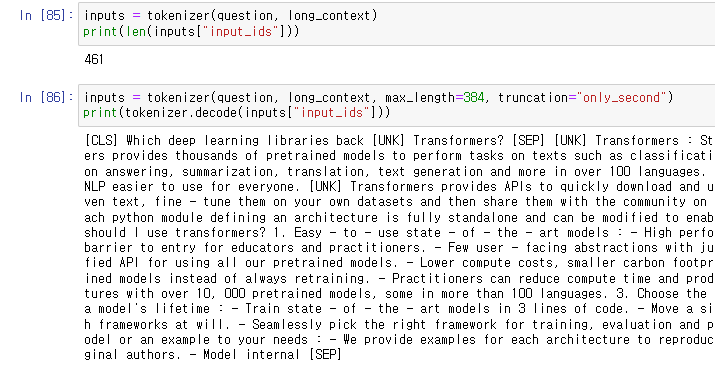
이번엔 text가 길어서 자르게 되는 경우를 생각해보자.
only_second 옵션은 question 뒤에 잇따라 오는 context만 truncate하는 옵션인데
이를 사용한다 해도 answer이 소실될 위험이 존재한다. (context 끝에 answer이 존재할 경우 등)
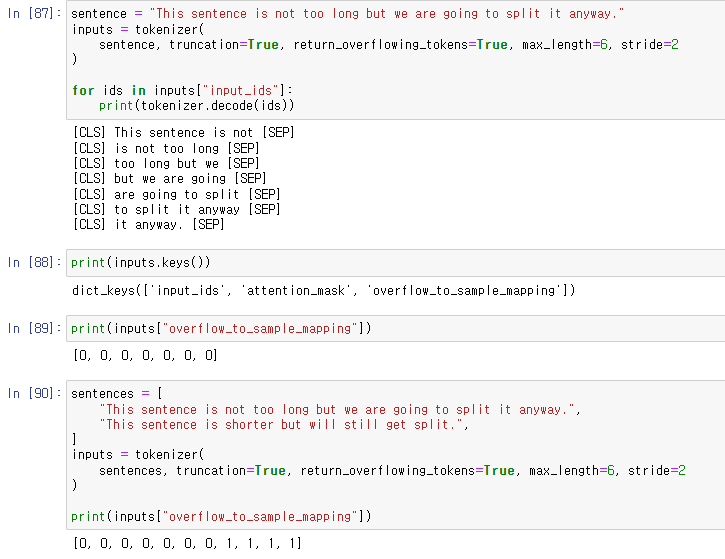
위의 문제를 해결하기 위해 이와 같이 overlap 되는 부분이 있게 chunk들을 나눠주는 방법이 있다.
return_overflowing_tokens와 stride 옵션이 해당 작업을 수행해준다.
overflow_to_sample_mapping은 각 결과값이 어떤 문장과 대응하는지 보여준다.
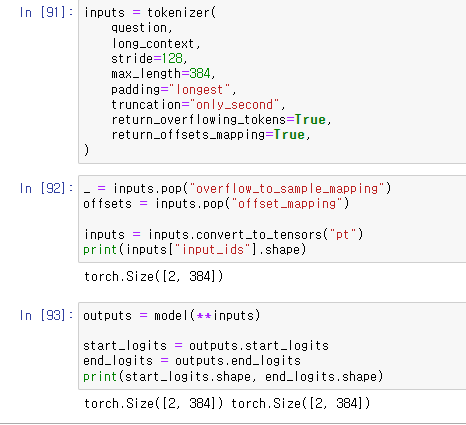
tokenizer를 초기화해주었다.
max_length와 stride를 설정하고
return_overflowing_tokens, return_offsets_mapping 옵션을 주었다.
뒤의 두 파라미터는 모델에 쓰이지 않기 때문에 tensor로 변환하기 전에 빼주었다.
context가 둘로 나뉘었기 때문에 tensor의 첫 번째 차원이 2로 나왔다.
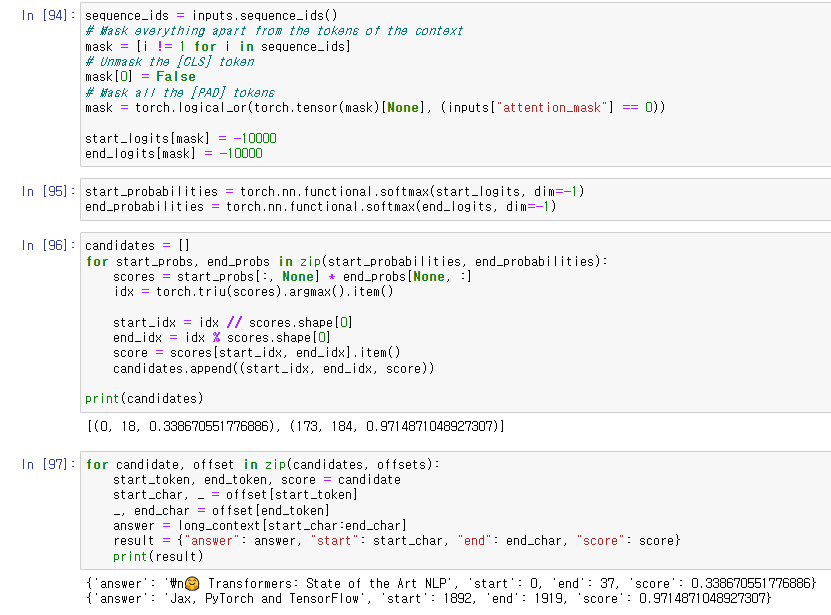
이전에 했던 mask 작업을 하고 결과를 시각화하였다.
나누어진 context에 따라 결과가 각각 나왔다. 두 번째 결과의 score가 더 높다.
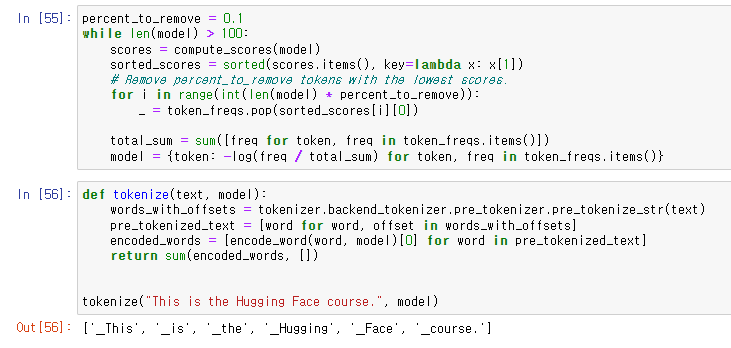
4. Normalization and pre-tokenization
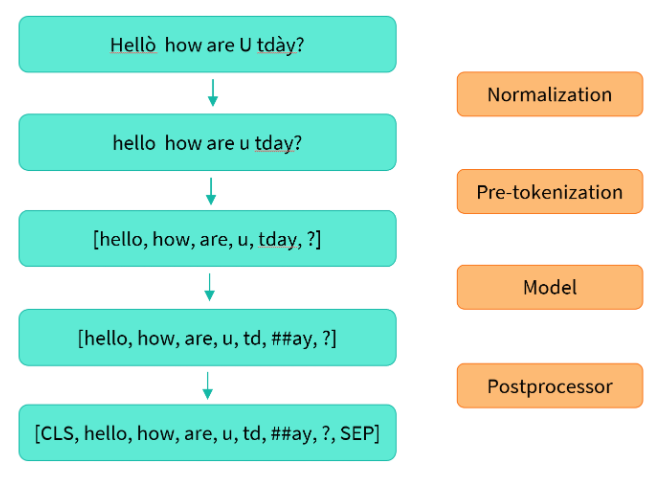
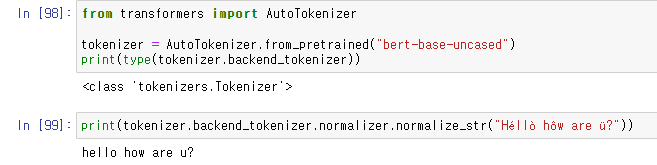
backend_tokenizer를 통해 tokenizer에 접근할 수 있다.
normalizer.normalize_str()을 사용하여 text를 따로 normalize 해줄 수 있다.
accent나 기호를 없애기도 하기 때문에 corpus에 맞는 normalization을 해주어야 한다.

맨 위의 라인은 Bert tokenizer,
are과 you 사이의 두 개의 space가 하나의 space로 replace되었고
are과 you의 offset에서 이를 확인할 수 있다.
두 번째 라인은 gpt2 tokenizer,
space를 Ġ 심볼과 함께 유지하였다.
세 번째 라인은 t5 tokenizer,
Sentencepiece 방법으로 여백만을 기준으로 문장을 나눴다.
reversible tokenization이라고 한다.
5. Tokenization 방법론들
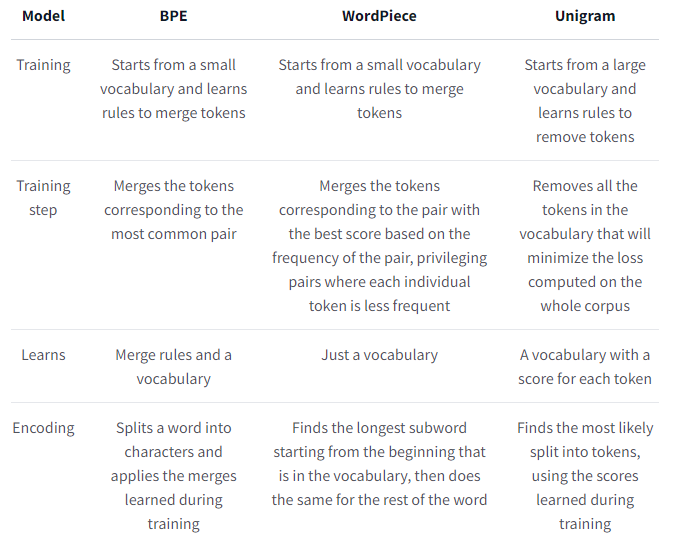
앞으로 살펴볼 방법론들에 대한 Overview이다.
차이점을 기준으로 살펴보면 이해하기 좋다.
이제 방법론들을 각각 살펴보자.
1. BPE(Byte-Pair Encoding) tokenization
words를 characters가 아닌 bytes로 보는 방법
빈번한 인접 요소들을 결합하여 merge rule을 만들고
그를 토대로 vocabulary와 corpus를 만드는 방식.
그 후, 만들어진 merge rule을 기반으로 tokenization.
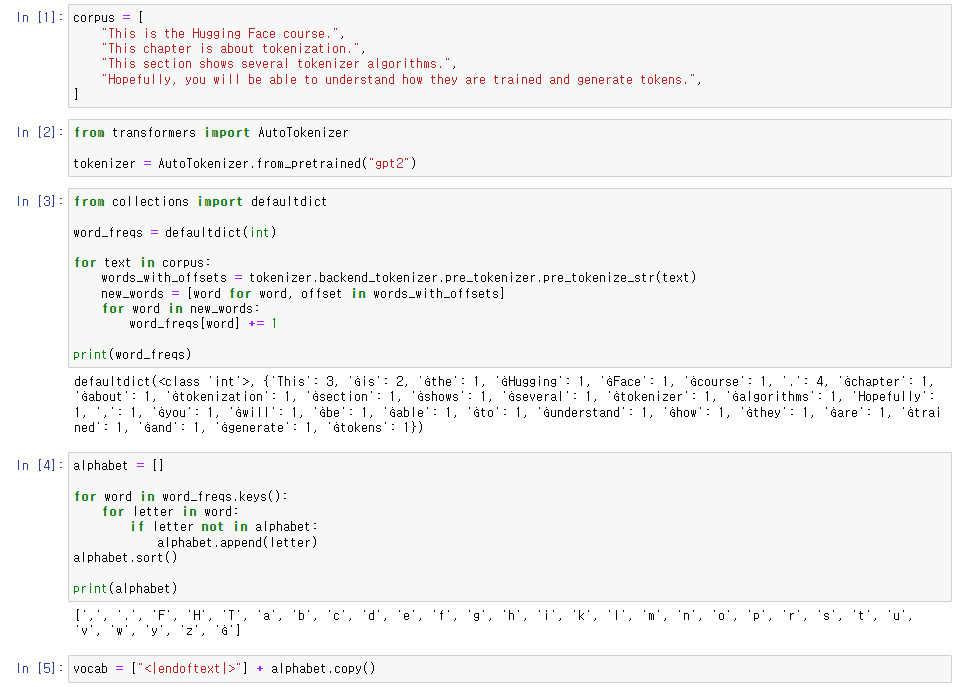
corpus를 만들고 gpt2 토크나이저(bpe)를 부른 후,
단어의 빈도수를 구해주었다.
또한 base vocabulary set를 만들고 endoftext라는 특수 토큰을 추가해 주었다.

training을 위해 단어 dictionary를 만들고
인접 요소들의 빈도수를 구하는 함수를 짠 다음, 예시 5개를 프린트했다.

가장 최빈의 pair는 ('Ġ', 't') 이고 그 둘을 결합시켜서 vocabulary에 추가해주었다.
그리고 함수를 작성해 결합된 pair를 split dictionary(corpus)에 반영시켜주었다.
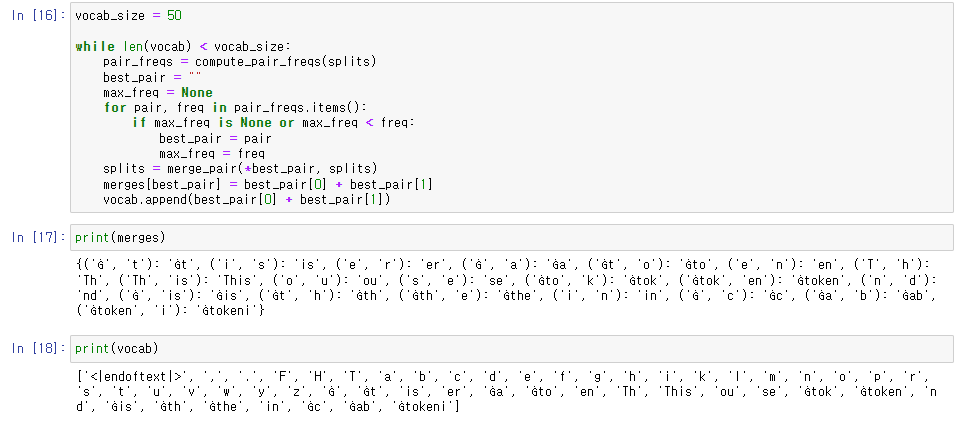
vocabulary size를 50으로 지정하고
위의 작업을 반복해주었다.
결과로 나온 단어 짝(merge rule)과 vocabulary.
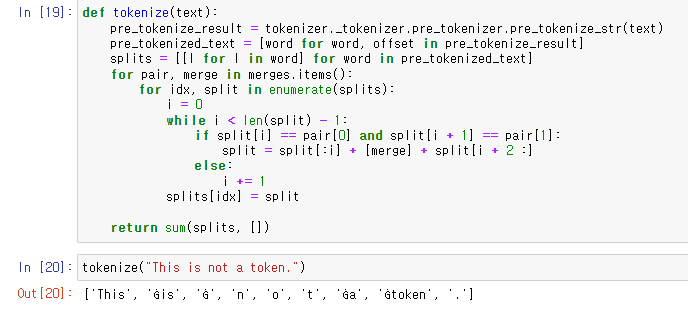
새로운 단어를 merge rule에서 찾아서 tokenize해주는 함수를 작성하고
예제 문장을 넣어 결과를 확인하였다.
2. WordPiece tokenization
인접 요소들의 score를 구한 후 score를 토대로
vocabulary를 만든 다음,
text의 window를 좁혀가며 tokenize 하는 방식.
initial vocabulary를 만들 때 subwords 앞에는 ##라는 prefix가 붙으며,
bpe와 달리 merge rule을 저장하지 않고 최종 vocabulary만 저장한다.
bpe와 달리 vocabulary에 단어가 없을 경우 전체를 [UNK](unknown)으로 지정한다.
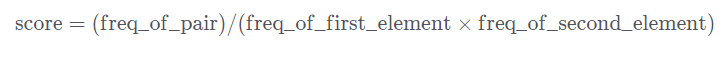
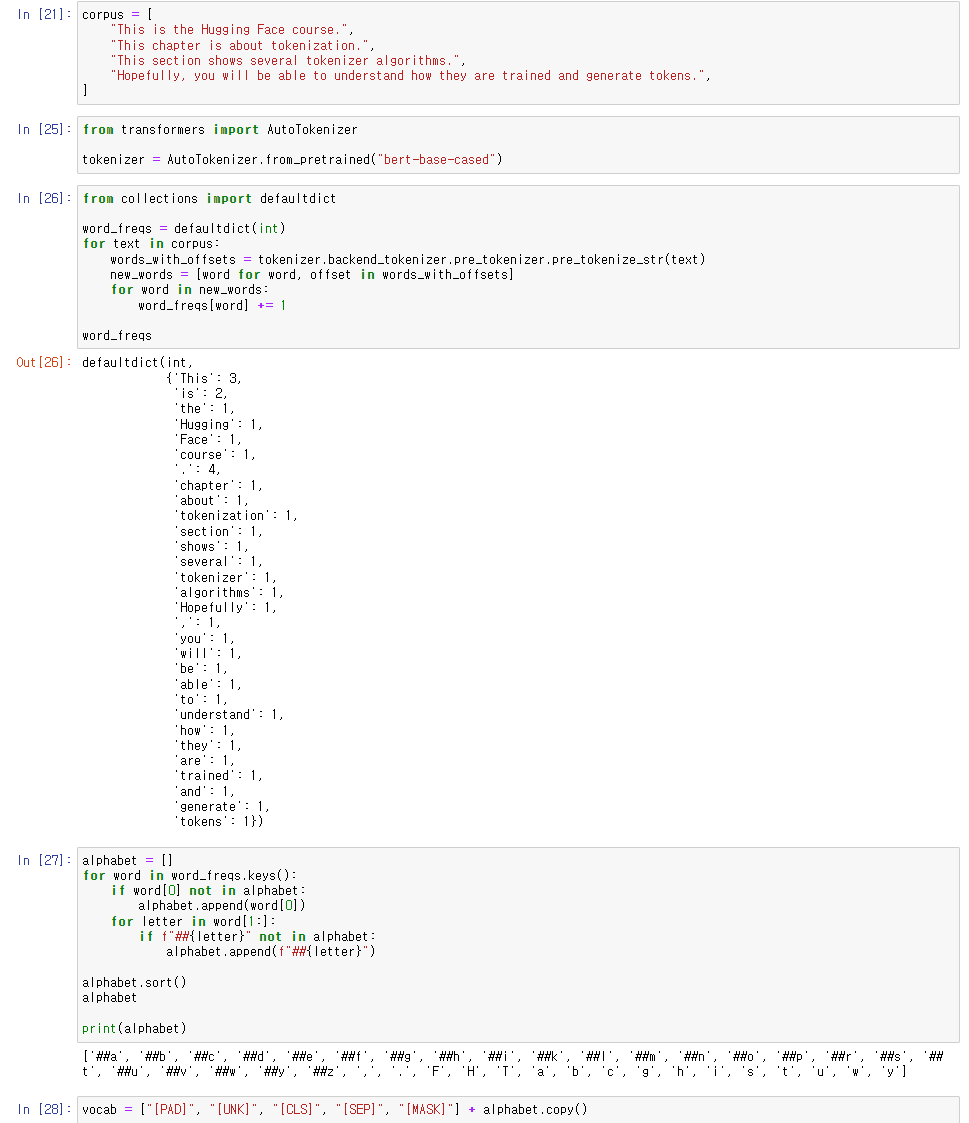
corpus를 pre-tokenization 후, vocabulary를 만들어 주었다.
word의 빈도수는 그 안에서의 element의 빈도수.
BERT에서 쓰이는 특수 토큰들을 추가해주었다.
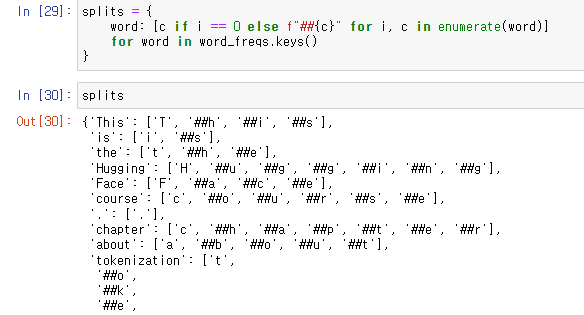
word dicitonary의 형태.
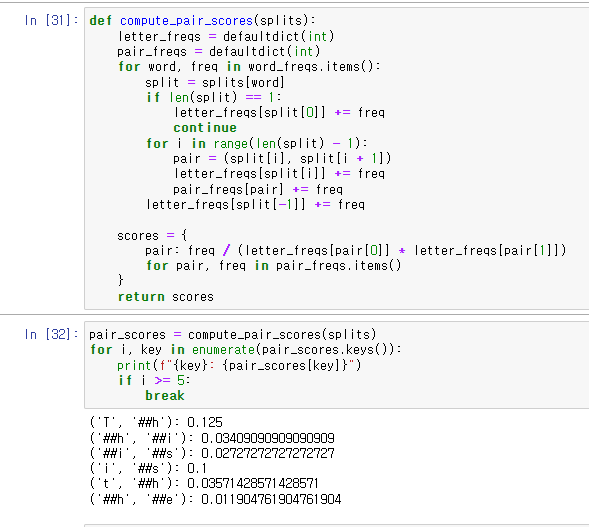
공식에 따라 요소들의 score를 구해주었다.

score가 가장 높은 pair를 찾고 merge해주는 과정
subword의 prefix인 ##을 고려해서 merge.
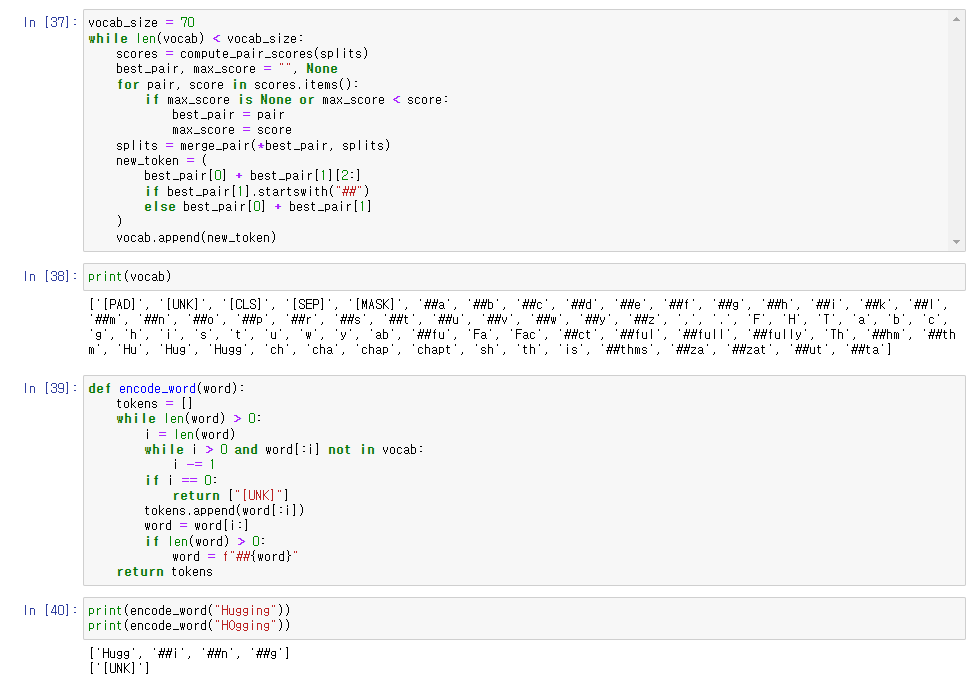
vocab_size를 지정하고 그에 따라서 vocabulary를 만들어준 모습.
vocabulary에 존재하지 않으면 [UNK]로 tokenize.
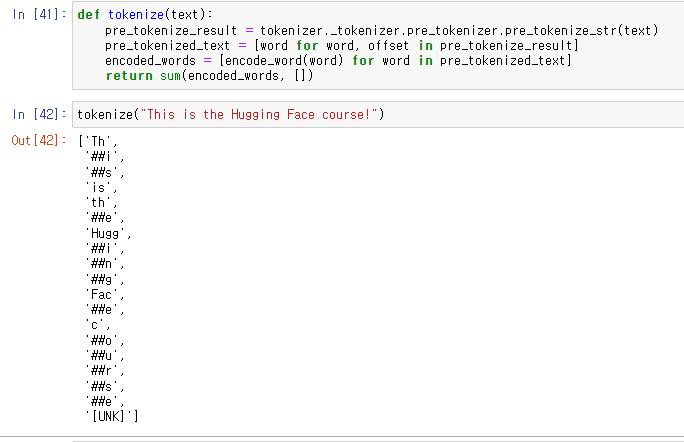
최종적으로 만들어진 tokenization 예시.
3. Unigram tokenization
각 token들이 이전의 token들에 대해 독립적이라고 고려하는 방법
전체 가능한 vocabulary에서 출발해서
제거했을 때, loss를 영향을 덜 주는 symbol들을 제거해나가는 방식
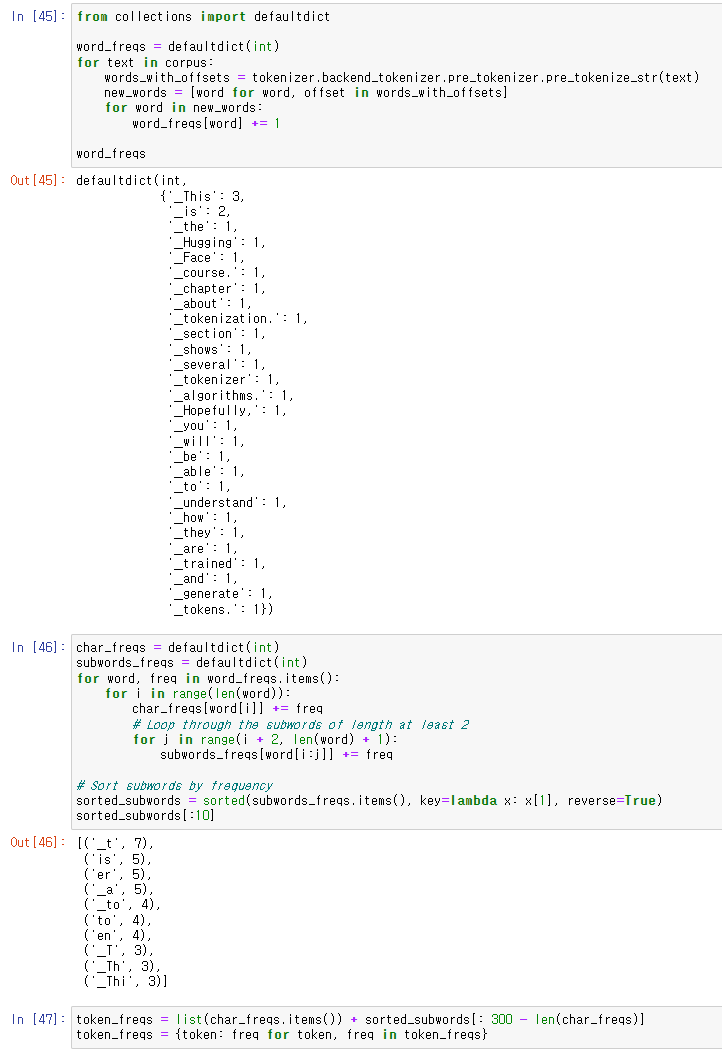
corpus를 만들고 빈도수를 가지고 dictionary를 만들어주었다.
문자의 빈도수와 subword의 빈도수를 체크하고
vocabulary size를 300으로 설정하고 token 기반의 빈도수 사전을 만들어주었다.
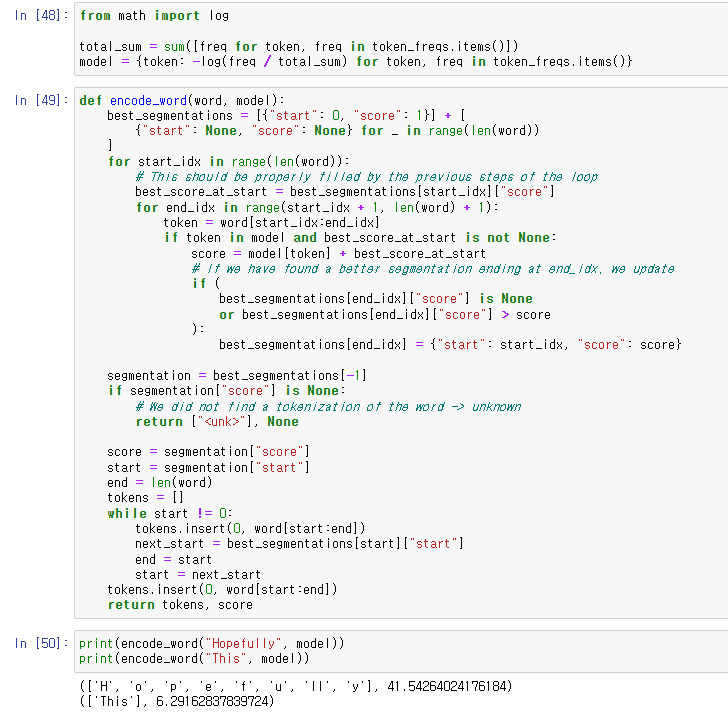
log 함수를 기반으로 probability를 계산해주고
best_segmentation을 구해 return.
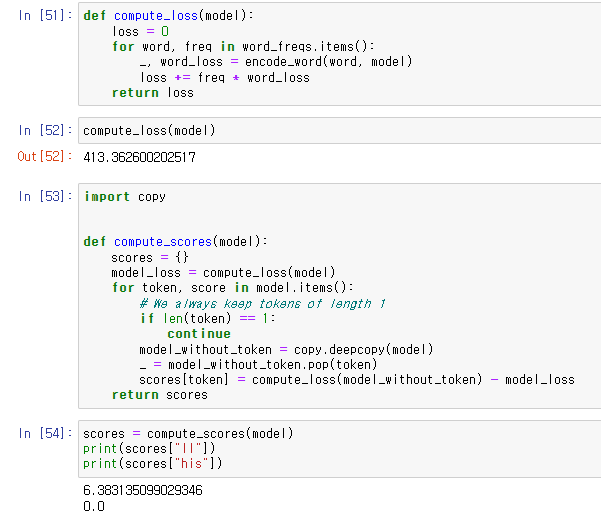
모델의 총 loss를 구하고
token을 지웠을 때 증가하는 loss값을 계산하는 함수를 짬.
special token을 추가하고 loss score 기준으로 제거하고자 하는 percent 만큼 token들을 제거
전체 과정을 함수로 만들고 결과를 산출.
4. Building a tokenizer
dataset 불러오기, dataset을 local에 저장하기.
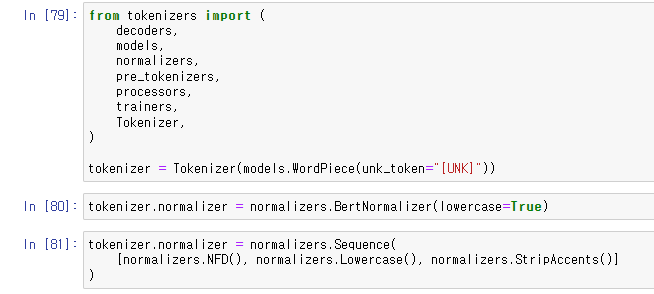
tokenizer 라이브러리의 패키지들 불러오기,
WordPiece tokenizer 생성하기, UNK 토큰 지정하기.
BertNormalizer를 사용하여 Normalizer 만들기,
Sequence()를 활용하여 Normalizer 직접 build하기.
NFD()는 StripAccents()가 accented characters를 인식할 수 있게 먼저 처리해주는 함수.

PreTokenizer로 BertPreTokenizer를 사용하기.
PreTokenizer 직접 만들기.
여기에서도 Sequence()를 활용하여 여러 pre-tokenizer들을 합성해서 사용할 수 있다.

special_tokens를 지정해주고 trainer instantiating.
train_from_iterator()를 활용해 train.
세 번째 라인 처럼 txt 파일을 사용해서 훈련시킬 수도 있다. (모델 다시 초기화시켜주었다.)
마지막은 tokenizer 테스트한 것.
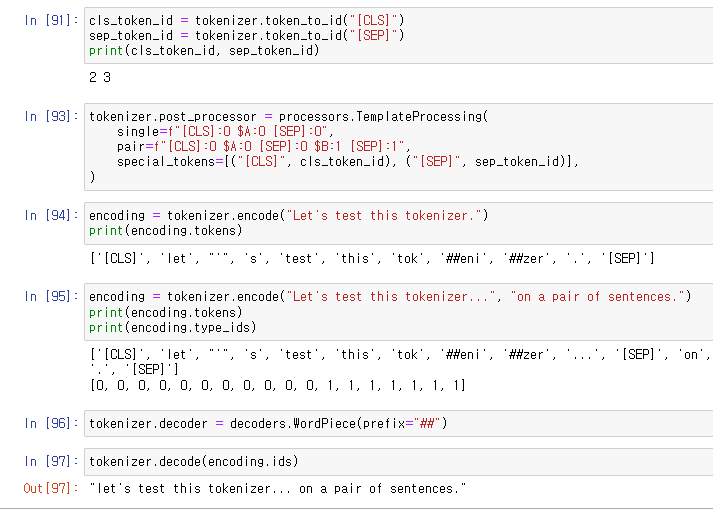
CLS, SEP 특수 토큰의 index를 확인.
단일 문장과 짝을 이룬 문장의 탬플렛을 만들어줌.
encoding 테스트.
decoder 테스트.
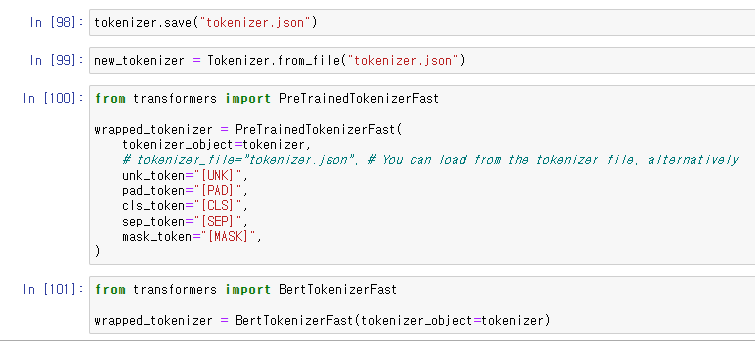
tokenizer 저장하기.
tokenizer 불러오기.
PretrainedTokenizerFast()에 기존 tokenizer를 합치고 싶다면,
special token들을 설정해주어야 한다.
만약 특정한 tokenizer(여기선 BertTokenizerFast)를 사용한다면,
default와 다른 special token만 설정해주면 된다.
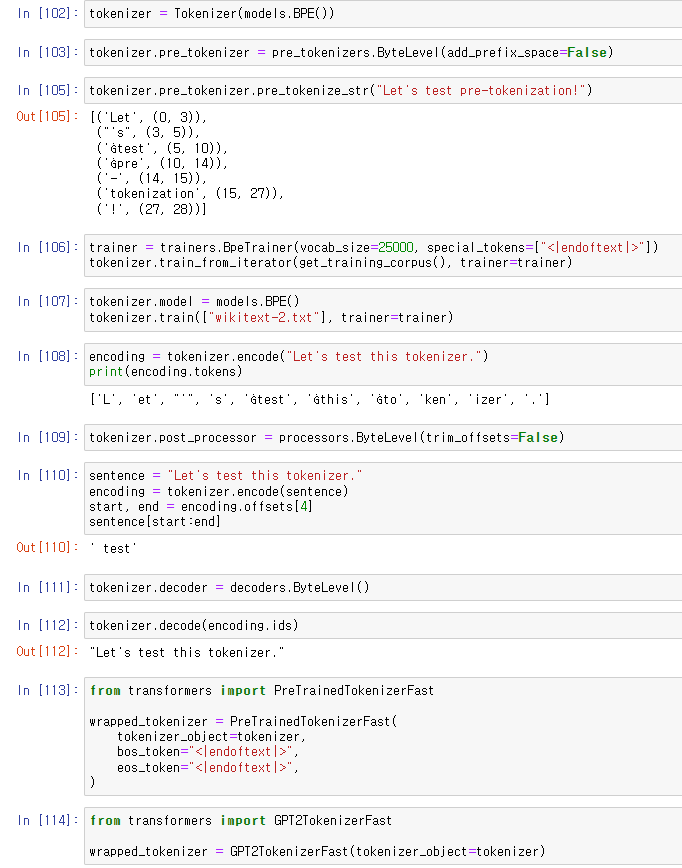
BPE로 토크나이저 만들어보기.
add_prefix_space는 문장 시작에 space를 추가하느냐를 묻는 옵션.
trim_offsets는 Ġ로 시작하는 토큰 시작점을 남길 것이냐를 묻는 옵션.
물론 시작점은 character가 아니라 space를 가리킨다.
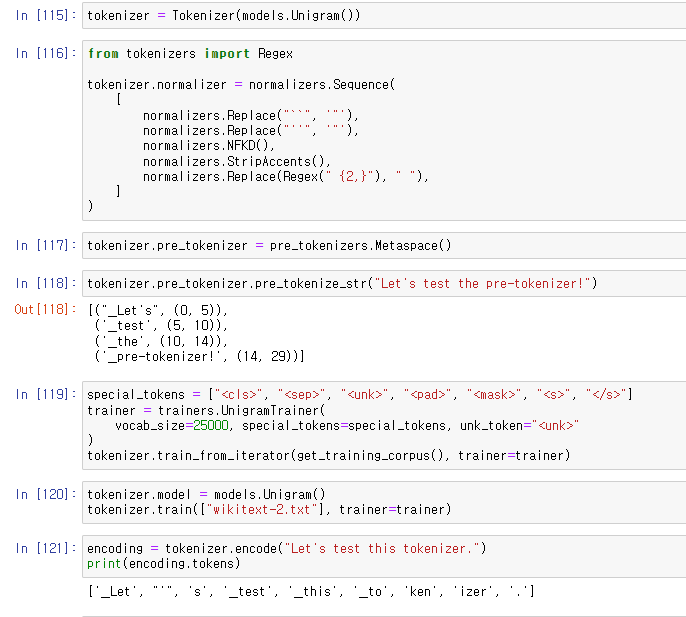
Unigram으로 토크나이저 만들어보기.
SentencePiece 토크나이저의 pre-tokenizer로 Metaspace()를 사용한다.
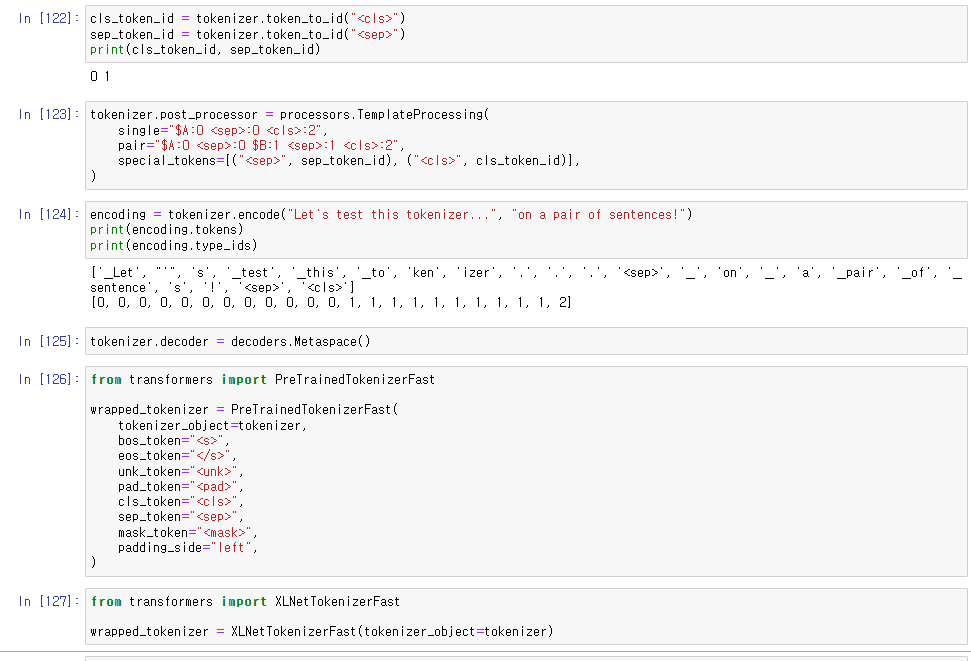
WordPiece에서 처럼 탬플릿을 만들어주었다.
cls 토큰이 문장 끝에 위치한다.
'Data > Information' 카테고리의 다른 글
| Hugging Face, Fine-tuning a masked language model (2) | 2022.03.16 |
|---|---|
| Hugging Face, Token classification (0) | 2022.03.16 |
| Hugging Face, Datasets (0) | 2022.02.24 |
| Hugging Face, Hub와 Repository 활용 (0) | 2022.02.22 |
| Hugging Face, pretrained models 불러오기 (0) | 2022.02.22 |



