Main NLP tasks - Hugging Face Course
For many NLP applications involving Transformer models, you can simply take a pretrained model from the Hugging Face Hub and fine-tune it directly on your data for the task at hand. Provided that the corpus used for pretraining is not too different from th
huggingface.co
This process of fine-tuning a pretrained language model on in-domain data is usually called domain adaptation.
Domain adaptation, 도메인 데이터로 학습된 언어 모델을 파인튜닝하는 방법
그냥 학습을 시킬 경우 도메인 언어를 rare tokens로 치환하는 문제가 발생하기 때문에 이와 같은 방법을 취해줌.
MLM은 domain-specific text를 fine-tuning하는데 유용함.
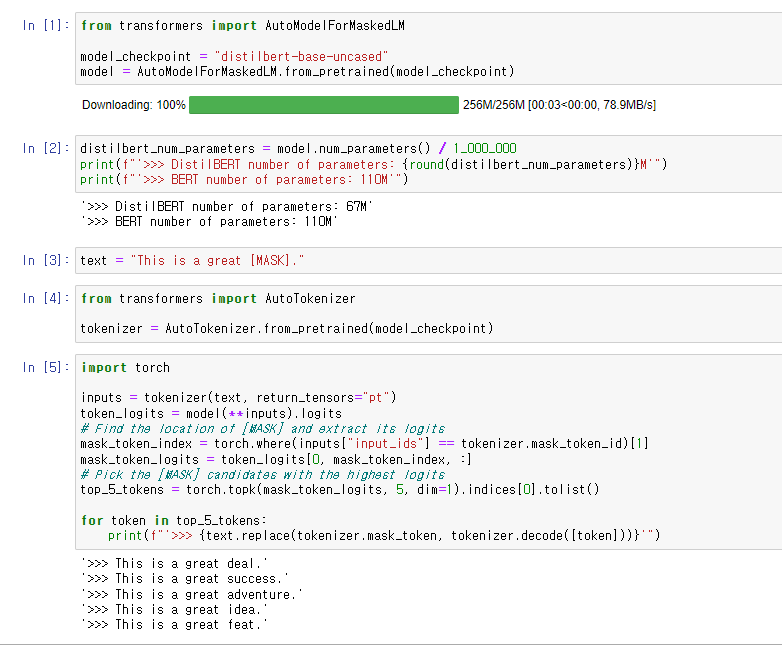
distilbert 모델을 불러왔다.
diltilbert는 "teacher model"인 BERT로 학습이 guide된 "student model"로,
더 적은 파라미터로 더 빠른 성능을 보이는 모델이다.
파라미터 개수의 차이를 위의 예제에서 볼 수 있다.
tokenizer를 load한 후에,
MASK된 token의 id를 찾아 logits을 뽑은 다음,
MASK된 token에 들어갈 5개의 후보군을 뽑아 출력하였다.
MASK된 token을 유추하는 것이 바로 MLM 과제이다.
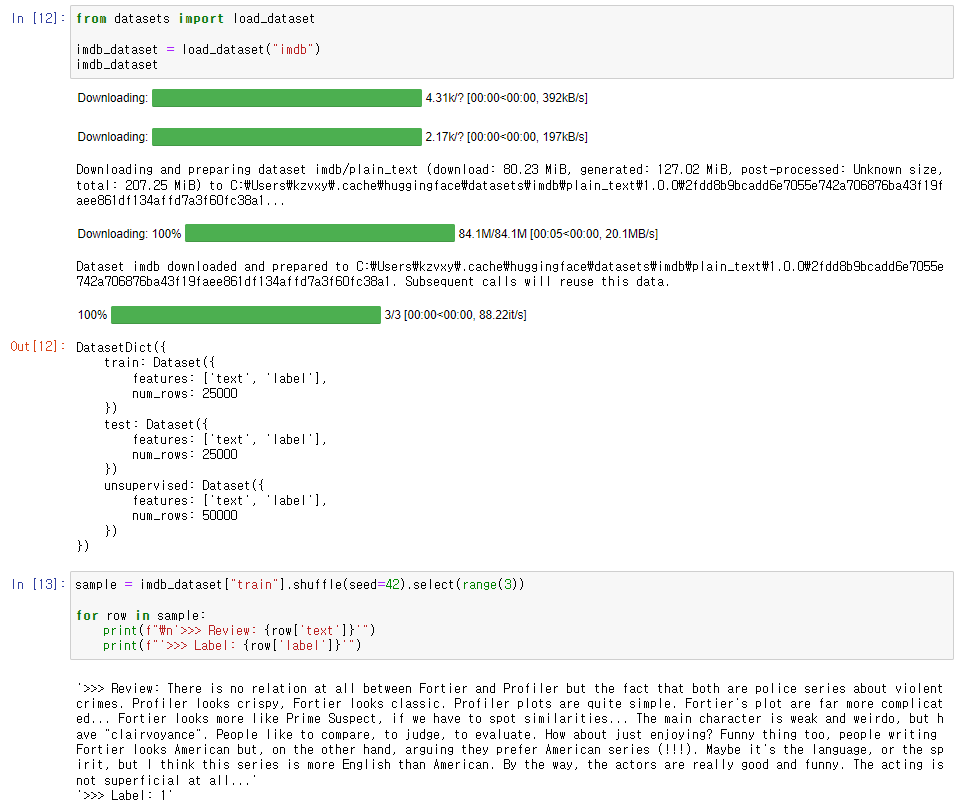
학습을 위해 데이터셋을 불러오고 random case를 뽑아보았다.
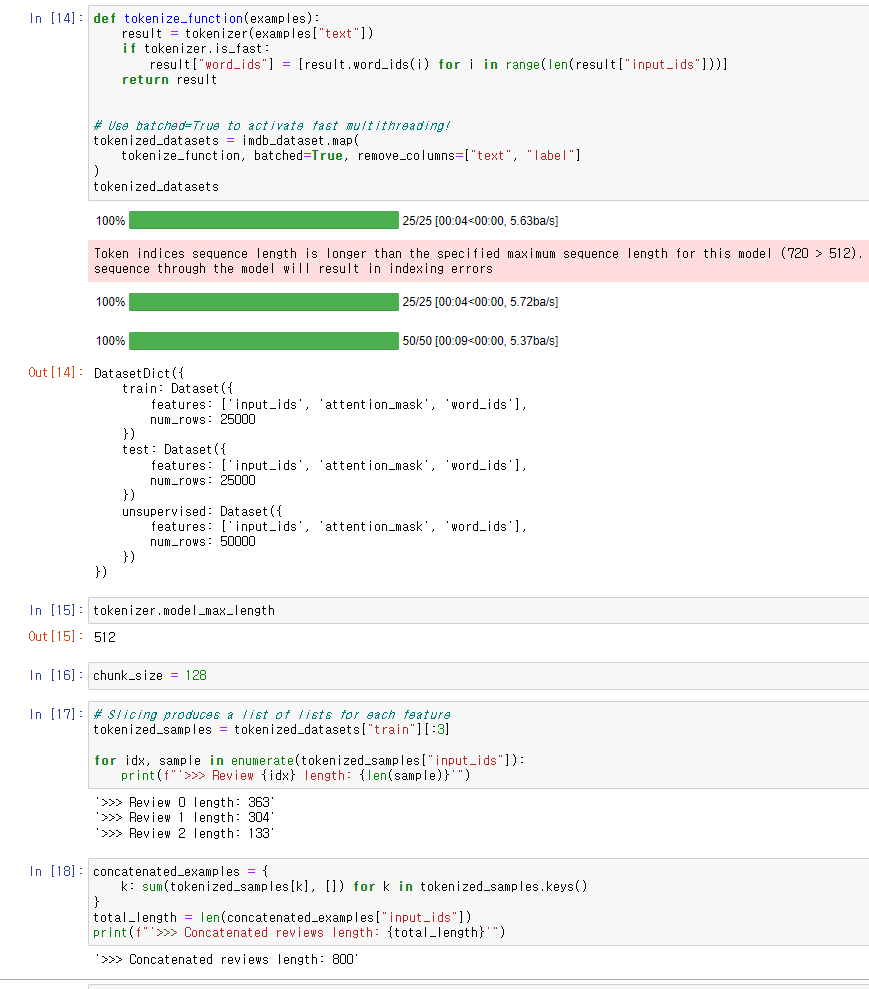
데이터 전처리 단계.
auto-regressive 나 mlm 에서는 보통 모든 examples를 whole corpus로 합친 다음
그것을 equal size의 chunk들로 split해주는 방법을 취한다.
각 example들을 개별 tokenize 해줄 경우, truncate되어 정보가 손실될 수 있기 때문이다.
그래서 truncation=True 옵션을 제외하고 tokenizer를 해주고 필요 없어진 text, label 컬럼을 제거해주었다.
위의 에러는 truncation 옵션이 없기 때문에 sequence length가 달라짐에 대한 경고이다.
model_max_length를 토대로 chunk_size를 정해주었다.
chunk_size는 gpu 등 기기의 연산 능력에 따라 달려 있다.
그리고 sample examples를 뽑아 concatenate 해주었다.
length가 합쳐진 것을 볼 수 있다.
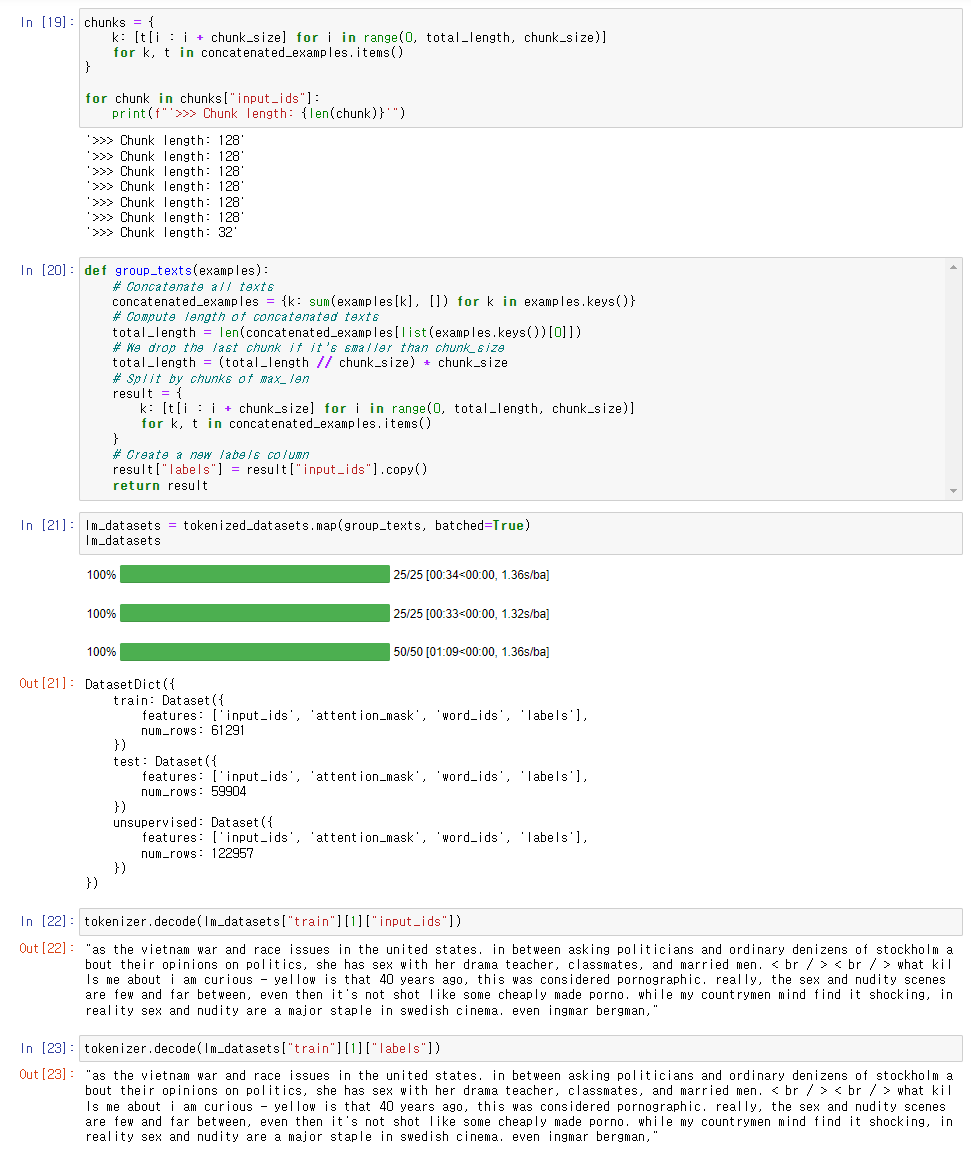
Concatenate 된 text를 chunks로 나누어주었다.
length가 다른 마지막 chunk를 처리하는 방법은
drop 시키거나 pad 해주는 두 가지 방법이 있는데 여기서는 drop시키는 방법을 택했다.
map 함수로 일괄 처리 후에 decode로 원문을 뽑아보았다.
input_ids를 카피해서 labels로 넣어줬기 때문에 두 결과가 같다.
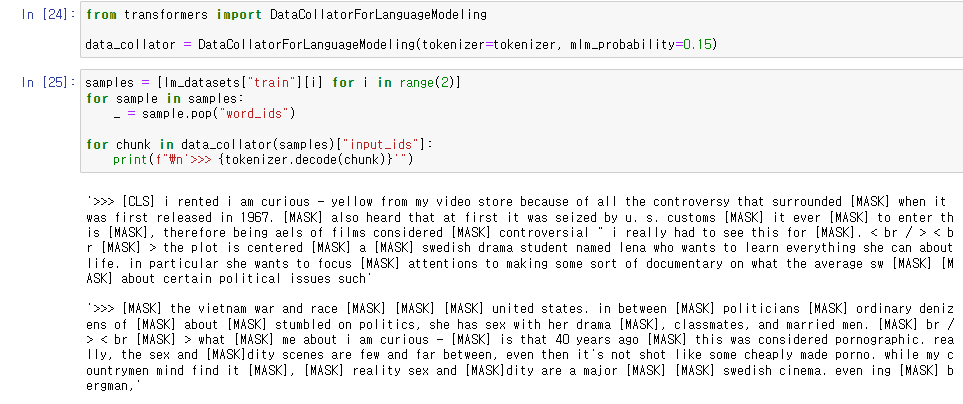
DataCollatorForLanguageModeling() 함수를 사용해서 랜덤하게 MASK 처리를 해주었다.
mlm_probability로 MASK 정도를 조절할 수 있는데 보통 0.15를 사용한다.
word_ids를 사용하지 않기 때문에 pop() 해주었다.
DataCollator가 매 batch마다 랜덤하게 MASK 처리를 해준다고 한다.
그리고 training과 test sets 에서 같은 data collator를 사용하면
evaluation metrics이 deterministic, 고정되지 않는 부작용이 있다.
후에, acclerate를 사용해 randomness를 다루는 법을 다룬다고 한다.
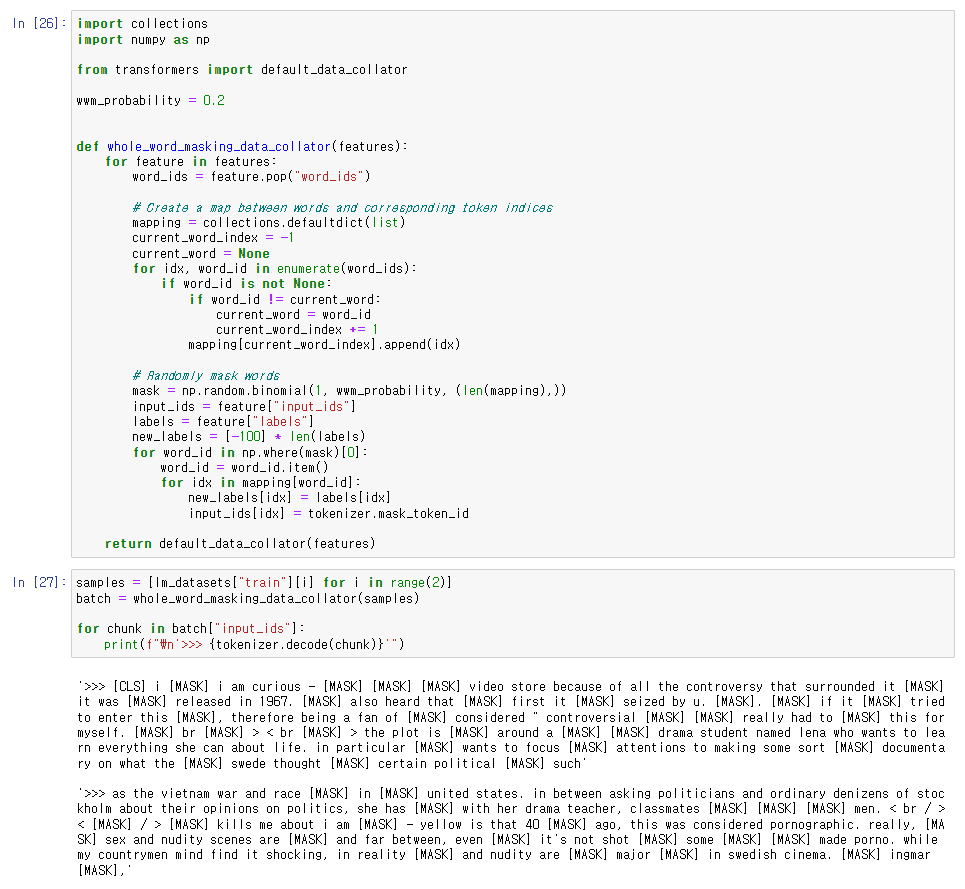
더불어서, 모든 단어들을 통틀어서 MASK 처리해주는 Whole word masking 방법을 소개하고 있다.
그를 위해서 data collator를 따로 작성해주었다.
words와 token indices의 map을 만들고,
mask 작업을 랜덤하게 처리해준 다음, default_data_collator()로 배치를 만들었다.
아래는 2개의 samples을 가지고 와서 batch의 chunk를 뽑아 관찰한 결과이다.
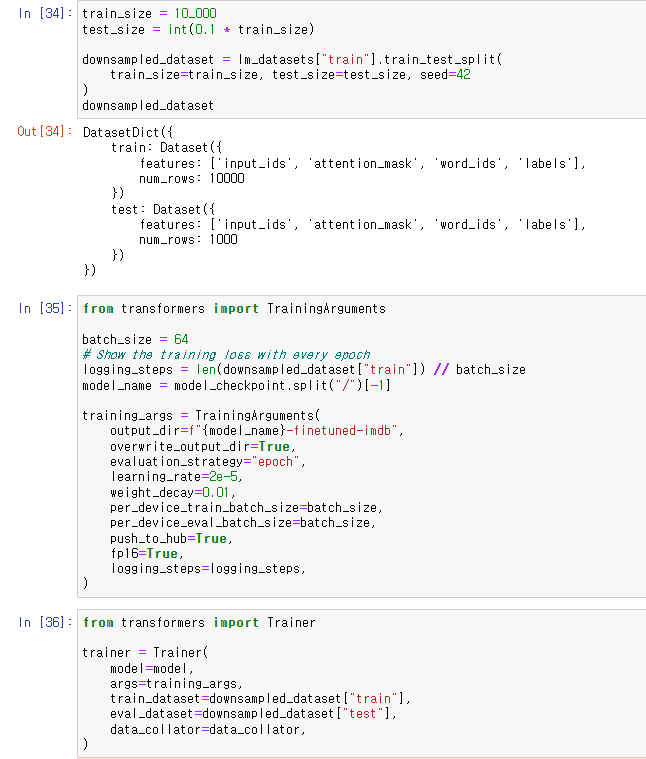
모든 샘플을 다 학습하기에는 환경 제약이 있기 때문에 (여기선 구글 코랩 기준으로 작성)
train_size, test_size를 조절해주었다.
arguments를 조절해주는 finetuning 작업을 수행하였다.
fp16은 mixed precision trainining 옵션으로 속도를 향상시켜주는 옵션이다.
mixed precision training은
weights를 fp32에서 fp16으로 변환한 후 연산을 수행하고
update 과정에서 다시 fp32로 변환해 weight를 업데이트해주는 방법론이다.
필요한 gradients만 잘 살려서 학습 속도를 높이는 방법이다.
data collator로는 whole masking data collator가 아닌 처음에 만든 collator를 사용하였다.

그리고 Perplexity 개념을 설명하는데
이게 낮을 수록 모델의 성능이 좋은 것이다.
next word의 probability를 계산하여 language model의 성능을 측정하는데
Perpleixty가 높다는 것은 다음 단어로 의외의 단어가 자주 등장했다는 뜻이다.
여기서는 cross-entropy loss의 exponential로 perplexity를 계산하였다.
처음에는 perplexity가 21.94 였던 것이
학습 후에는 11.84까지 줄어든 것을 볼 수 있다.
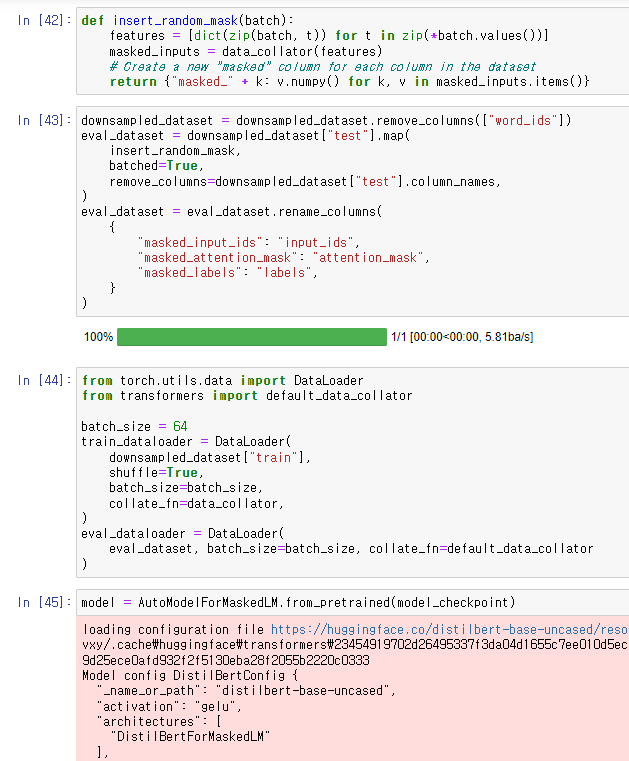
이제 이전에 말했던 Accelerator를 사용해서 Randomness를 Freeze하는 방법에 대해 배워보자.
다시 말하지만, DataCollatorForLanguageModeling의 random masking을 제어하기 위한 것이다.
여기에선, 전체 Dataset에 대해 한번에 masking 해주는 방법으로 randomness를 제거해주고
그 후에 eval_dataloader에서 default data collator를 사용해 batch를 모아주었다.
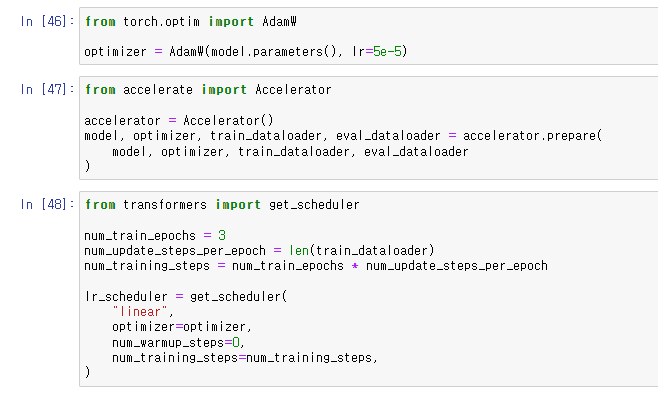
optimizer를 설정하고
Accelerator, scheduler를 세팅해주었다.

그리고 train을 돌려봤는데 이게 꽤 용량이 커서
내 작업 환경에선 돌릴 수가 없었다.

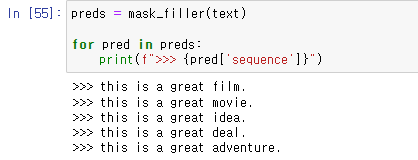
파이프 라인으로 하는 방법을 마지막으로 소개하였다.
'Data > Information' 카테고리의 다른 글
| Hugging Face, Summarization (0) | 2022.03.25 |
|---|---|
| Hugging Face, Translation (3) | 2022.03.17 |
| Hugging Face, Token classification (0) | 2022.03.16 |
| Huggig Face, Tokenizers (0) | 2022.02.25 |
| Hugging Face, Datasets (0) | 2022.02.24 |