Main NLP tasks - Hugging Face Course
In this section we’ll take a look at how Transformer models can be used to condense long documents into summaries, a task known as text summarization. This is one of the most challenging NLP tasks as it requires a range of abilities, such as understandin
huggingface.co
문서를 요약하는 text summarization에 대해 알아보자.

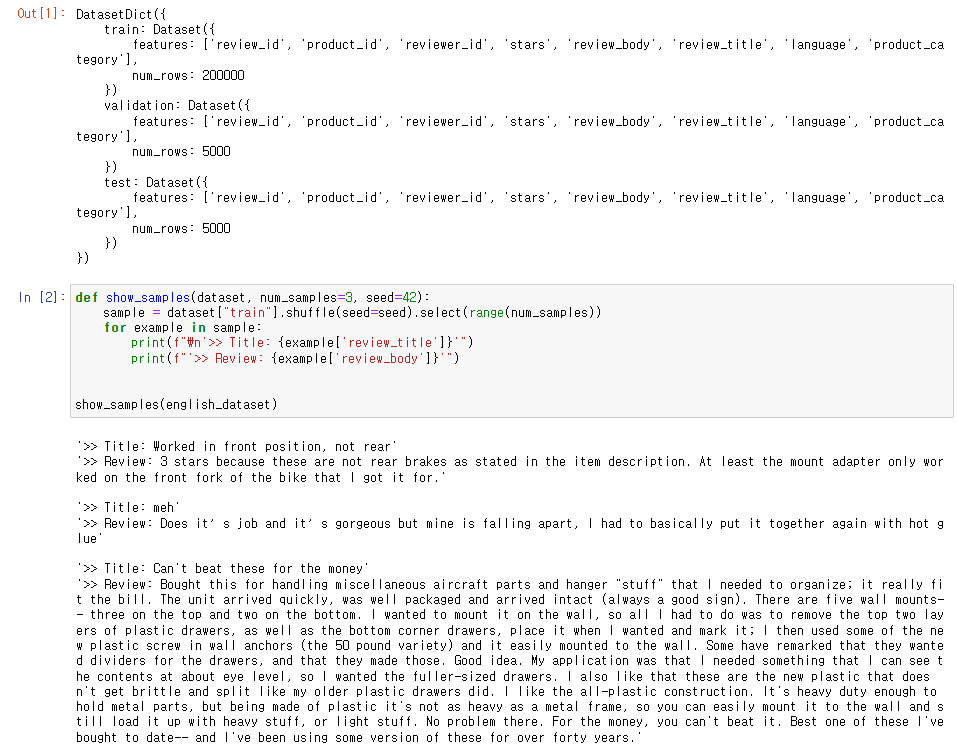
필요한 데이터를 load하고 랜덤 샘플을 뽑아 출력해보았다.
English와 Spanish의 bilingual model을 만들 것이기 때문에 두 언어의 데이터셋을 불러와주었다.
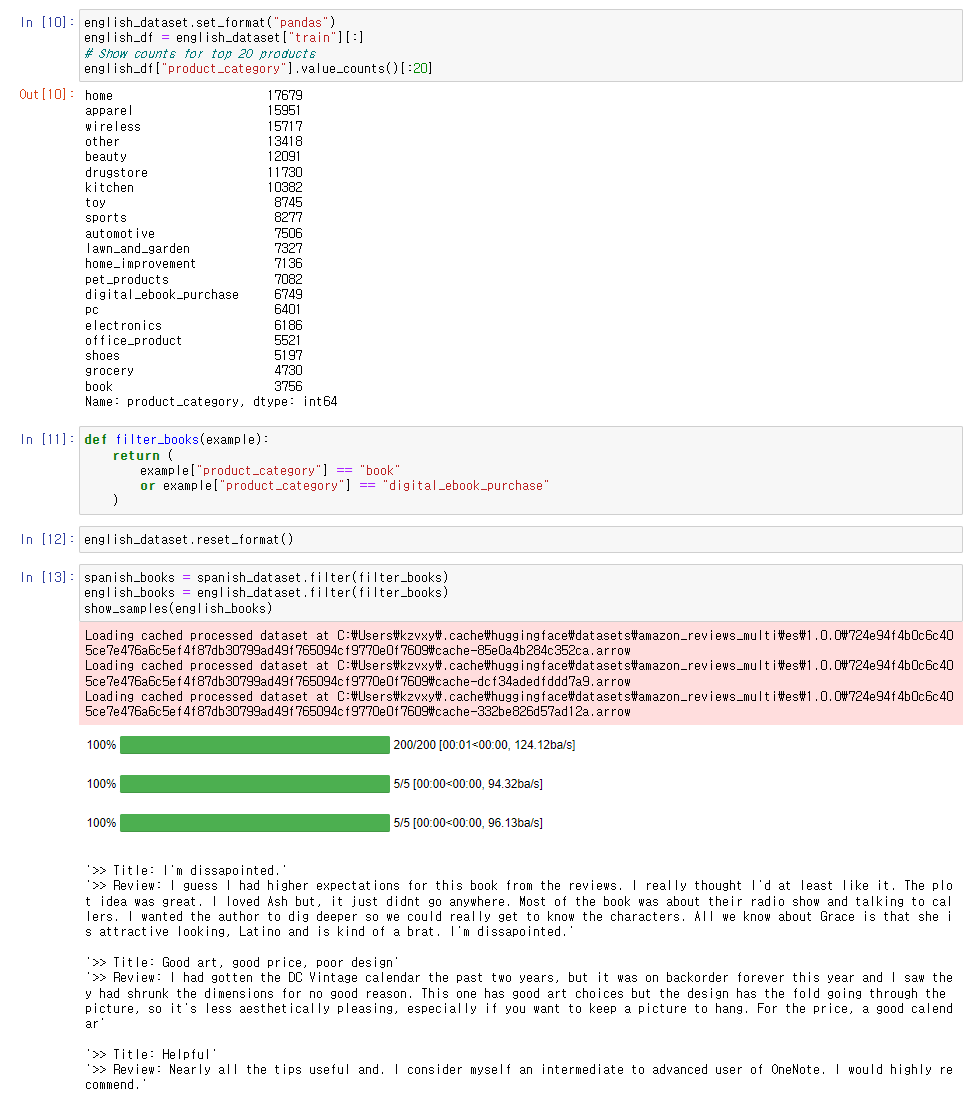
데이터를 pandas 데이터프레임 형식으로 만들고 그 안의 카테고리를 살펴보았다.
그 후, 데이터의 format을 다시 pandas에서 arrow로 변환해주었다.
그리고 filter()함수를 활용해 필요 카테고리의 데이터를 뽑아주었다.
filter()함수는 map()함수와 유사한데 데이터셋에서 데이터를 뽑을 때 사용한다.
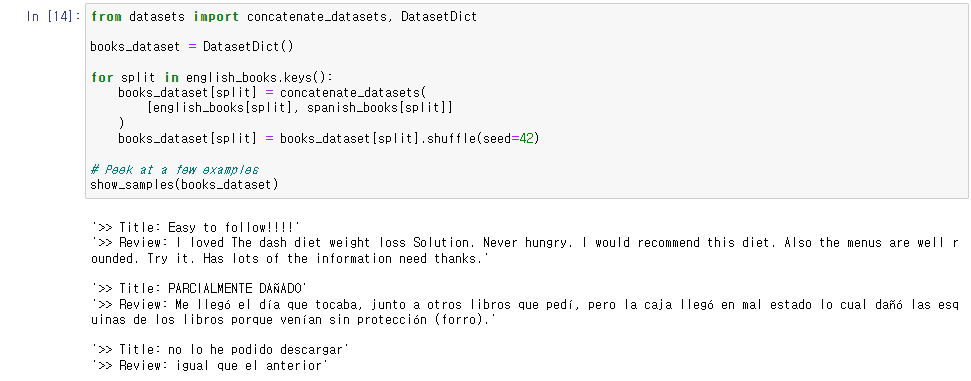
English, Spanish의 Bilingual 데이터셋을 만들기 위해 english_books의 key 값을 따라가면서 두 데이터를 합쳐주었다.
그리고 한 쪽 언어에 과적합되지 않도록 데이터를 랜덤하게 셔플해주었다.
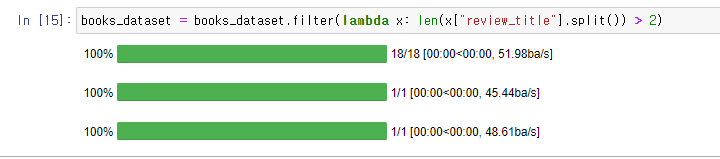
데이터를 살펴보니 Title 데이터가 1~2 단어 사이로 매우 치우쳐짐을 관측했다.
요약 결과가 과도하게 짧게 나오는 것을 방지하기 위해서 필터링을 해주었다.
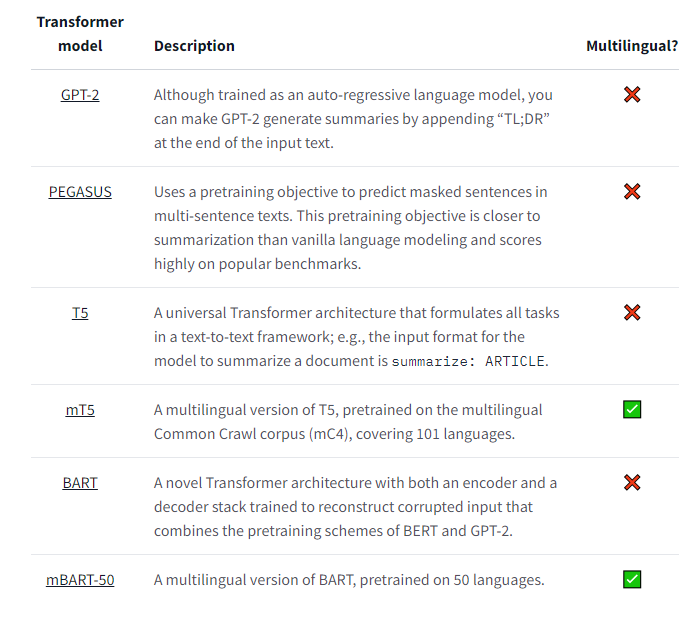
모델 선정하는 부분이 나오는데 대부분은 monolingual 한 것을 볼 수 있다.
이번 학습에서는 mT5를 사용한다고 한다.
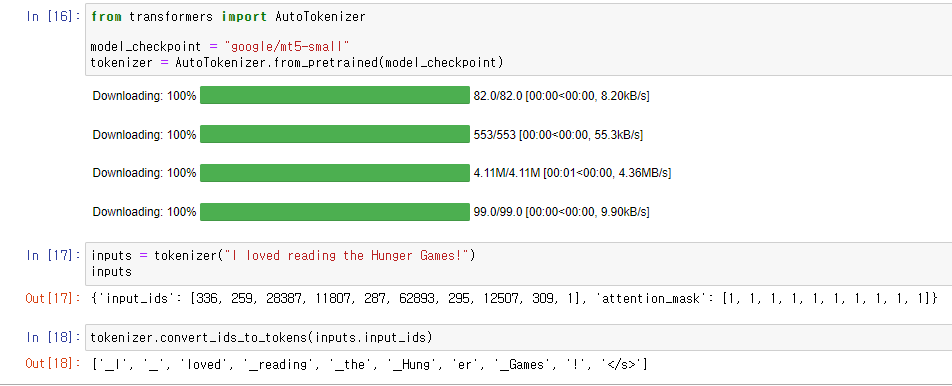
Model checkpoint를 정의하고 그에 따라 Tokenizer를 load해주었다.
아래는 Tokenizer를 적용한 예제이다.
'_' 토큰과 '/s' 토큰을 보아 SentencePiece tokenizer를 사용함을 알 수 있다.
SentencePiece tokenizer는 Unigram segementation 알고리즘을 사용하며 다중 언어 corpora를 다루는 데 유용하다.
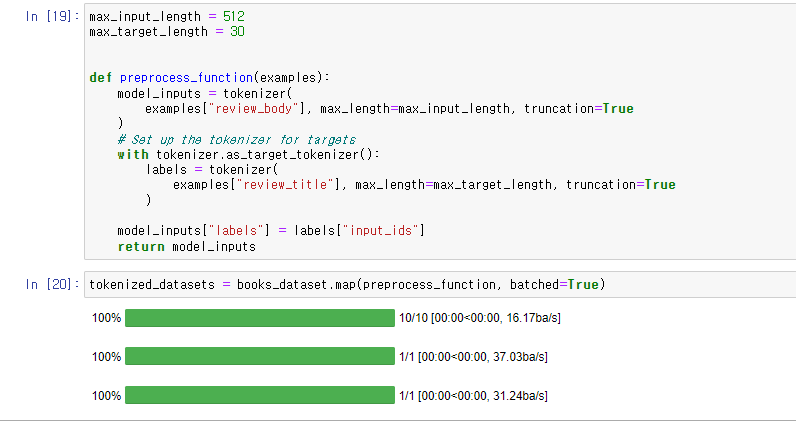
input_length와 target_length를 정의하고
as_target_tokenizer()를 with 구문과 함께 사용하여
labels의 tokenize가 inputs와 평행하게 처리되도록 해주었음.
map() 함수를 통해 데이터셋에 대해 일괄 처리.
review_title이 review_body에 대한 target data가 되었고
그 input_ids가 model_inputs의 labels로 들어간 것을 볼 수 있다.
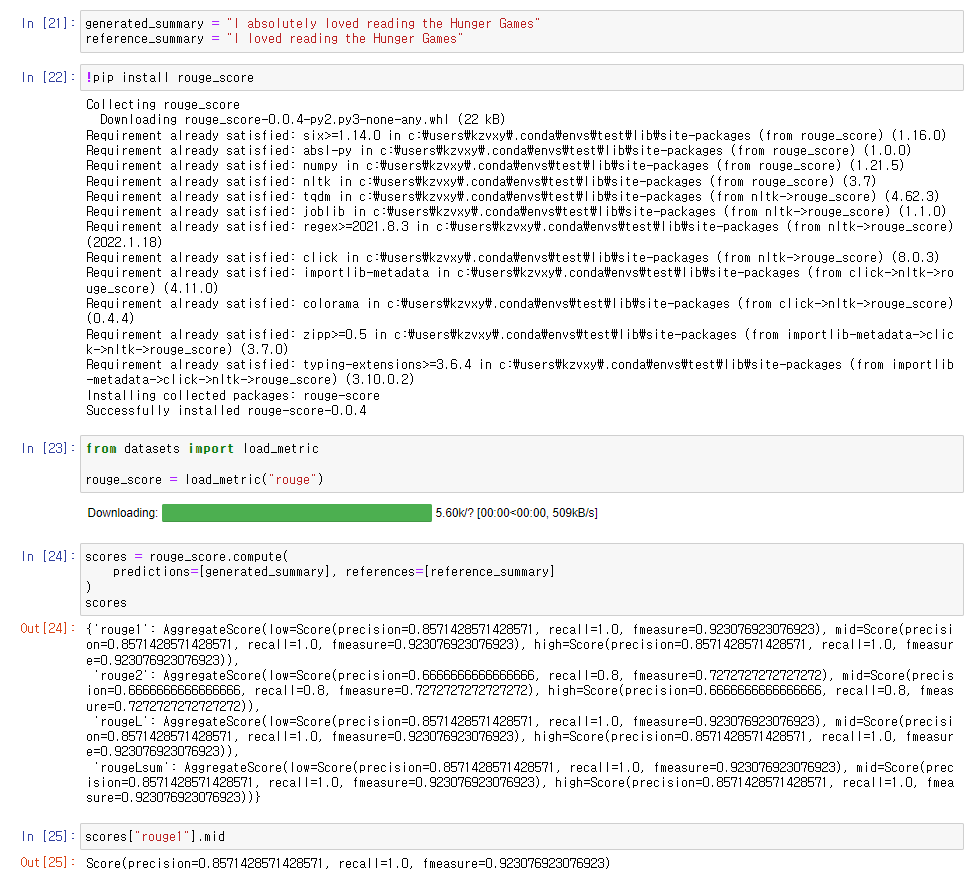
Summarization의 평가에 사용될 Rouge Score에 대해 살펴보았다.
Rouge Score는 간략하게 말하자면 n-gram 및 LCS(Longest Common Subsequence)를 적용한
F-1 Score(Precision과 Recall의 조화평균)이며
generated summary 와 reference summary를 비교하여 도출하는 Score이다.
Recall-Oriented Understudy for Gisting Evaluation의 약자이기도 하다.
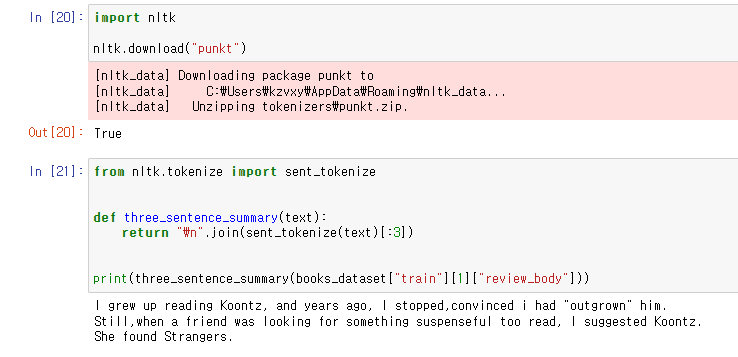
다시 돌아와서 nltk 패키지의 punkt(punctuation)를 다운로드.
article의 첫 세 문장을 취하는 lead-3 baseline을 구현하고자 하는데
U.S. 나 U.N. 같은 경우처럼
마침표를 기준으로 문장을 나누면 처리가 어려운 케이스가 있어서 nltk 패키지를 사용해주었다.
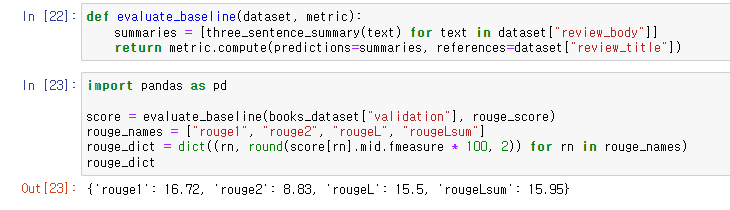
validation 데이터셋을 가지고 lead-3 baseline의 rouge score를 뽑고 결과를 확인.
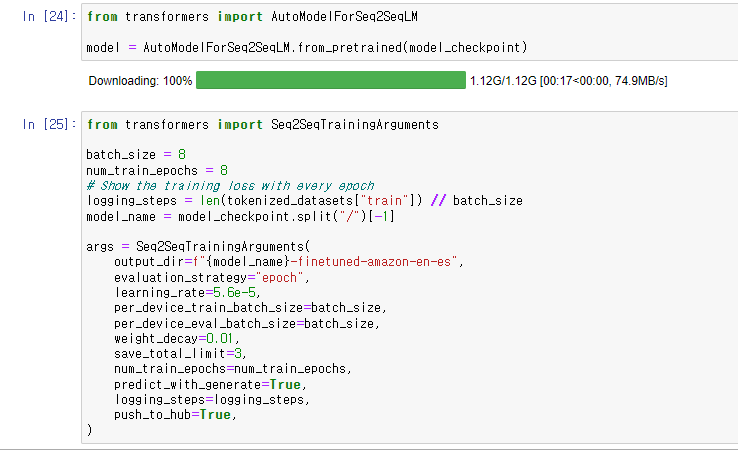
pretrained model을 호출한 후,
hyperparameters 및 arguments 정의.
predict_with_generate 옵션을 통해 매 epoch 마다 metric을 계산
(토큰을 하나씩 예측해가며 추론하는 decoder의 작업이 모델의 generate() 함수에서 실행됨)
save_total_limit은 체크포인트의 최대 저장 개수를 지정해주는 옵션.
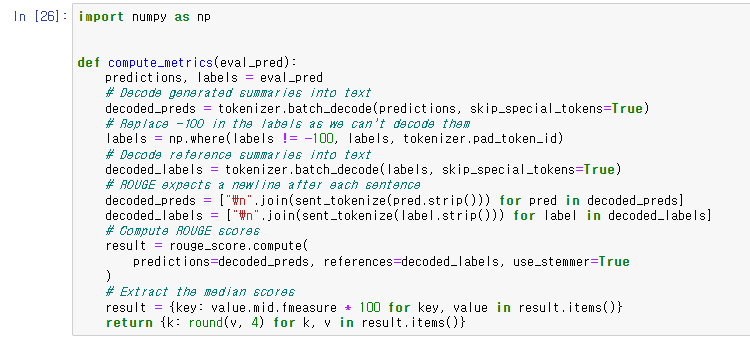
ROUGE scores를 계산하기 전에 outputs와 labels를 decode해야 하기 때문에 위와 같은 함수를 작성해주었다.
preds와 labels를 batch_decode() 함수로 decode 해주었는데
labels의 경우에는 padding된 부분을 고려해준 것을 볼 수 있다.
그리고 sent_tokenize를 사용해서 마침표 문제를 해결해주었다.
나머지는 scores를 계산하고 반환해주는 내용의 코드이다.
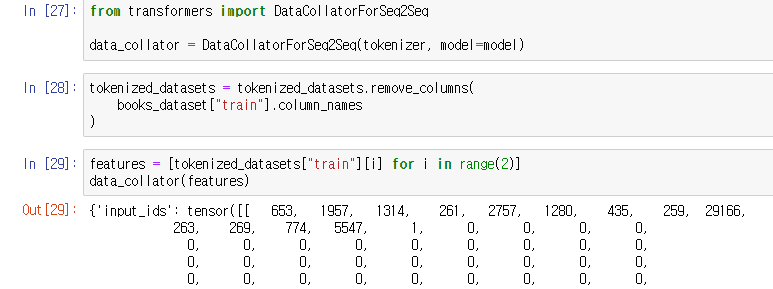
Data_collator를 load 후, 불필요한 (문자열) 칼럼을 제거.
원래 encoder-decoder Transformer 모델을 사용할 때에는 decoding할 때 labels을 각각 맞게 조정해줘야 하는데
DataCollatorForSeq2Seq collator를 통해서 inputs와 lables를 dinamically하게 pad해준다. 한 줄로 해결!

그리고 이처럼, decoder_input_ids에서 labels가 오른쪽으로 밀린 것을 확인할 수 있다.
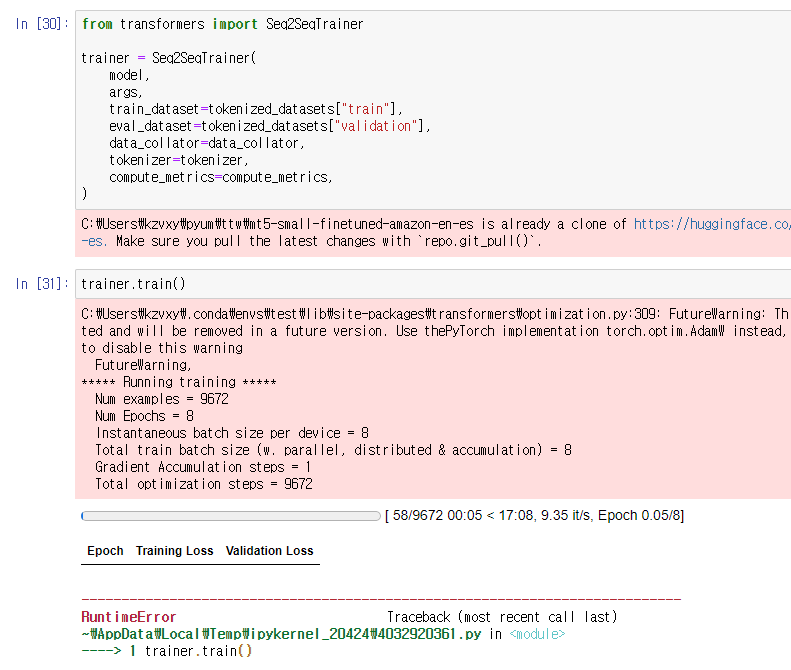
Trainer의 parameter를 맞춰주고, train()을 하는데,
이것도 터져버렸어요. ㅠㅠ
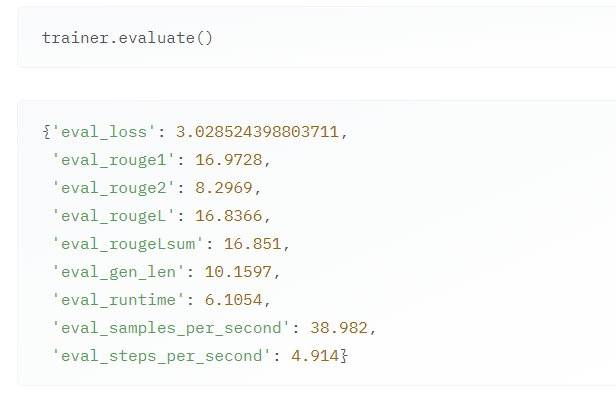
사이트에선 이와 같은 결과가 나왔다고 한다...
이번엔 Accelerate를 활용해서 Fine-tuning 하는 방법!
PyTorch dataloader가 tensors를 요구하기 때문에 torch로 포맷 변환.
모델을 다시 load하고
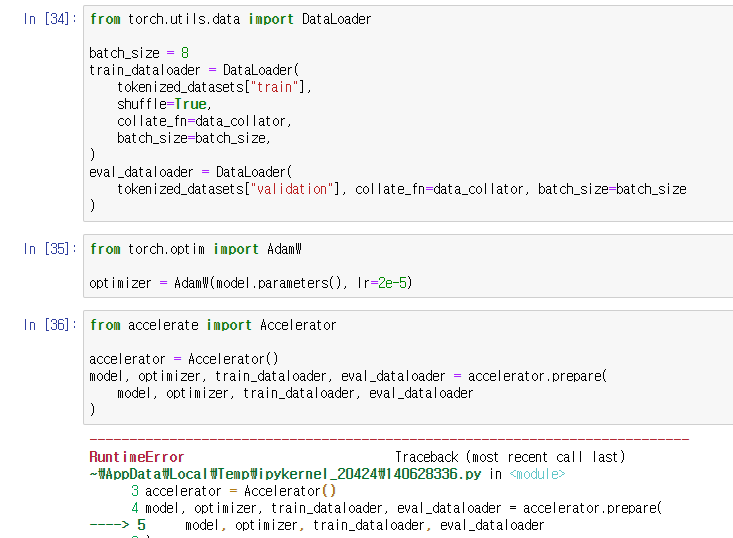
DataLoader()를 정의해주고 Optimizer 또한 설정해준 다음,
Accelerator()를 정의해줬는데, 여기서 또 OOM으로 터져버렸다.
train() 전부터 이미 GPU 메모리가 거의 차 있었는데 Corpus나 모델이 너무 컸던 것 같다.
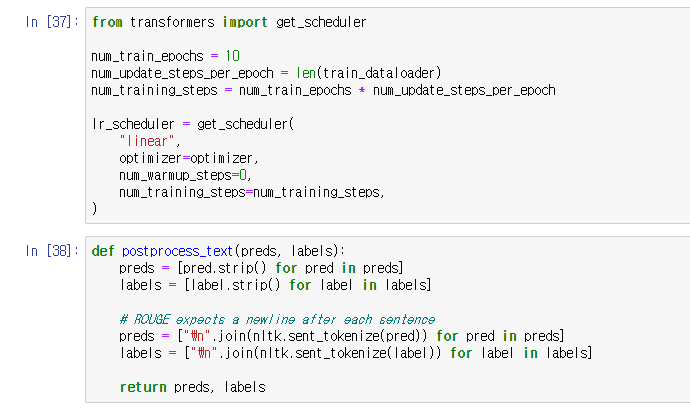
scheduler 조정 후에 postprocess_text(후처리)
ROUGE metric이 sentences가 라인 별로 나뉘어지는 것을 요구하기 때문에.

Training 부분은 이전의 다른 예제에서와 크게 다른 부분이 없다.
epoch 마다 model.train()을 모델을 학습한 후
batch를 돌며 loss를 줄여가며 outputs을 계산해준다.
Evaluation 부분을 보면, Translation task 때 사용했던,
unwrap_model()을 사용했는데, 모델이 저장되기 전에 unwrap해서 outputs을 뽑아주는 용도이다.
여기서는 batch의 input_ids와 attention_mask에 해당하고
그 후에 pad_across_processes에서 dynamic padding을 해주었다.
labels도 같은 방식으로 dynamic padding을 해준 다음 gather()로 concatenate 해주었다.
labels에서 -100을 지니는 값들을 tokenzier.pad_token_id로 대체해주었다. (decode 안됨)
그리고 batch_decode() 함수로 preds와 labels를 받은 뒤
postprocess_text에서 sentence를 띄어준 다음, rouge_score에 해당 batch를 더해주었다.

위쪽은 이미 봤던 ROUGE scores를 계산하고 그것을 출력하는 코드이고
아래는 모델을 저장하고 허브에 올리는 코드이다.

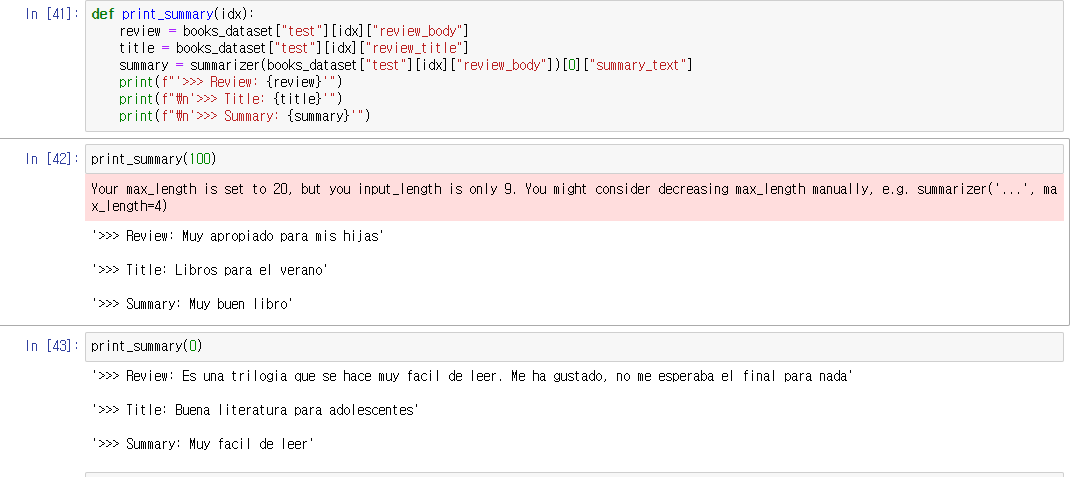
마지막으로 파이프라인을 사용해서 간단하게 summarize 해보았다. 이상이다. 땡큐!
'Data > Information' 카테고리의 다른 글
| Hugging Face, Question answering (0) | 2022.04.01 |
|---|---|
| Hugging Face, Training a causal language model from scratch (0) | 2022.04.01 |
| Hugging Face, Translation (3) | 2022.03.17 |
| Hugging Face, Fine-tuning a masked language model (2) | 2022.03.16 |
| Hugging Face, Token classification (0) | 2022.03.16 |