Training a causal language model from scratch - Hugging Face Course
Up until now, we’ve mostly been using pretrained models and fine-tuning them for new use cases by reusing the weights from pretraining. As we saw in Chapter 1, this is commonly referred to as transfer learning, and it’s a very successful strategy for a
huggingface.co
Causal language model을 처음부터 학습시켜보는 강의 내용.
여기서 Text generation task에 대해 살펴볼 것인데 해당 내용은
auto-regressive model이나 GPT-2와 같은 causal language model 로 가장 잘 다뤄진다.
사실 causal language model이 auto-regressive model이다.

데이터 준비 단계이다. codeparrot이라는 Githup dump를 사용한다.
any_keyword_in_string 함수와 filter_streaming_dataset 함수를 통해 특정 frameworks의 데이터를 가져와주었다.
filter_streaming_dataset 함수 데이터셋 sample을 돌면서
filters의 단어가 있는지 any_keyword_in_string으로 검사해준다. 그리고 그 후 dictionary 형태로 담아준다.
코드가 3시간 정도 돌고서 갑자기 Dataset이 정의 안됐다고 해서 함께 소개한 다른 방법을 사용했다.

바로 이와 같은 허깅페이스 허브에서 제공하는 데이터셋을 사용하는 방법을 말이다.
그런데 이것도 실행해보니
ds_valid 이하 부분이 split="train"으로 작성되어서인지(원래 문서에서) 오류가 나길래
위와 같이 split="validation"으로 바꿔주었다.
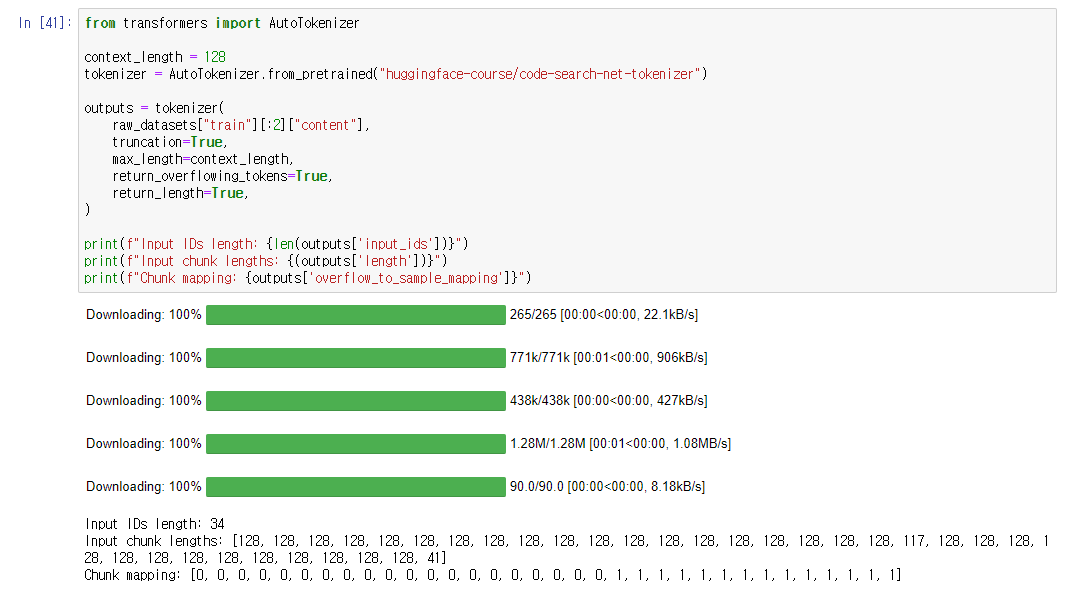
AutoTokenizer를 활용해 tokenizer를 load해주었다.
context_length를 학습과 활용에 유용하도록 128로 작게 설정해주었다.
return_overflowing_tokens를 활용해, max_length 이상의 text chunks를 나누어주었다.
샘플 데이터를 가지고 테스트해보았다.

length == context_length 조건을 추가해, length가 짧은 chunks를 제거해주었다.
map() 함수를 통해 일괄처리하였다.
불필요한 column은 train을 위해 제거해주었다.
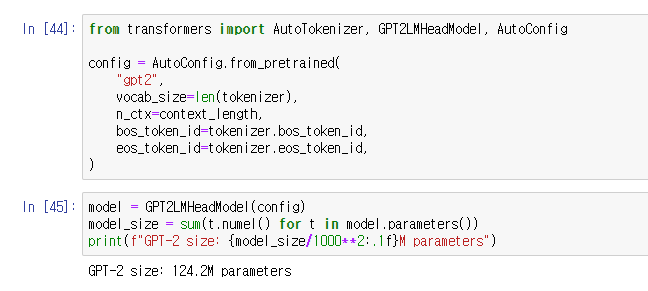
GPT2 모델을 사용하기 위해 모델에서 요구하는 configuration을 설정해주었다.
bos_token과 eos_token은 시퀀의 시작과 끝을 나타내는 토큰들이다. (beginning and end of sequence)
GPT2LMHeadModel로 model을 정의해주었다.
모델을 직접 초기화하기 때문에 from_pretrained() 함수를 사용하지 않은 모습이다.
124.2M 개의 parameters가 존재한다.

배치를 만드는 data_collator 부분이다.
DataCollatorForLanguageModeling()에는 mlm 옵션이 있는데
이를 활용해 Masked Language Model(MLM) 또는
Causal Language Model(CLM)에 맞는 DataCollator를 사용할 수 있다.
여기서는 Causal Language Model을 사용할 것이기 때문에 mlm = False로 해주었다.
그리고 샘플 데이터로 shape를 뽑아보았다.
참고로, tokenized_datasets 도 원래는 tokenized_dataset으로 작성되어 있었다. 오타.

다른 tasks에서와 다르게 cosine learning rate schedule을 사용해주었다.
warmup_steps를 사용해주는 모습도 볼 수 있다.
gradient accumulation은 single batch의 memory 크기가 클 경우 사용하는 옵션으로
작은 batch들을 축적해 큰 batch를 쓸 때의 효과를 내는 방법이다.
역시나 OOM(Out of Memory)으로 학습이 되지 않았다.

파이프라인을 통해 Text-generation task를 수행해보았다.
여기서도 왠지 에러가 나길래,
pipeline() 함수 안의 device=device 옵션을 없애주었고
그덕에 코드가 원활하게 돌아갔다.
파이프라인을 가지고 한번 scatter plot을 작성시켜보았다.

유형을 달리 해가며 실험을 계속해보았다.
dataframe을 생성해보고, mean()을 시켜보고, RandomForest 모델을 작성시켜봤다.
문서에서 나온 것만큼 잘 되지는 않는 모습이다.
length에 제한을 두었기 때문에 output이 짤리는 모습을 볼 수 있다.

이제 accelerator를 활용해서 training loop을 customize해보자.
input sequence에서 keyword가 등장하는지 확인하고
single token일 경우 저장해주는 식을 짰다.
공백도 고려해준 모습이다.

이번에는 loss function을 customize해보자.
inputs와 labels를 정렬해주고 (next token이 current token의 label)
마지막 logit은 제거해주었다. (input sequence 이후의 label이 부재하기 때문에)
이제 sample 별로 loss를 계산할 수 있고
각 sample 내에서 keywords들이 얼마나 자주 등장하는지 세줄 수 있다.
그리고 그 등장 빈도를 weights로 활용해 weigthed average를 계산해줄 수 있다.
keywords가 없는 samples을 버리고 싶지 않기 때문에 weights에 1을 더해주었다.
view()는 tensor shape를 변환하는 데 사용하는 함수이다.

dataloader를 생성해주었다.
tokenized_datasets 부분이 다 tokenized_dataset으로 작성되어 있어서 고쳐주었다.
weight_decay를 설정하고
weight_decay를 적용할 파라미터들과 적용하지 않을 파라미터들을 고르고 나눠주었다.
evaluate() 함수를 작성해
evaluation이 이뤄지는 동안 processes의 losses들이 모이도록 해주었다.
torch.no_grad()는 gradient 계산을 tracking 하지 않는다는 의미이다.
메모리 사용을 줄이고 연산 속도를 높이기 위해 사용한다.
torch.cat()은 tensor를 합치는 함수이며 torch.exp()는 input의 지수 곱을 리턴한다.
loss와 perplexity를 리턴해주었다.
perplexity는 예상 못한 단어의 등장율을 나타내는 score이다.
(Fine-tuning a masked language model 문서에서 다룬 적이 있다.)

모델을 다시 불러와주었고 optimizer를 정의하고 accelerator를 생성해주었다.
train_dataloader가 accelerator.prepare()로 전달되기 때문에
그 length를 활용해서 training steps의 수를 계산할 수 있다.
linear 스케쥴러를 사용해주었다.

train 전에 evaluate()를 먼저 시행해 보았는데,
값이 존재하지 않은 tensor가 있었던 모양이다.

train 코드다. 이 이후에 loss와 perplexity가 줄어들 것을 기대할 수 있다.
결과는 따로 제공되지 않았다.
loss를 계산하고 gradients를 clip하는 부분이 다른 tasks들과는 다른 모습을 보여주고 있다.
앞서 살펴보았던 gradient_accumulation을 적용하기 위해서
gradient_accumulation_steps 와 clip_grad_norm 를 사용하면서 그렇게 된 듯 하다.
'Data > Information' 카테고리의 다른 글
| Sql 문법 빠르게 훑어보기 (0) | 2022.04.01 |
|---|---|
| Hugging Face, Question answering (0) | 2022.04.01 |
| Hugging Face, Summarization (0) | 2022.03.25 |
| Hugging Face, Translation (3) | 2022.03.17 |
| Hugging Face, Fine-tuning a masked language model (2) | 2022.03.16 |



