오늘은 아침 루틴인 영어 쉐도잉 + 코딩 테스트 문제 풀이를
오랜만에 아침 시간에 다 완료하고
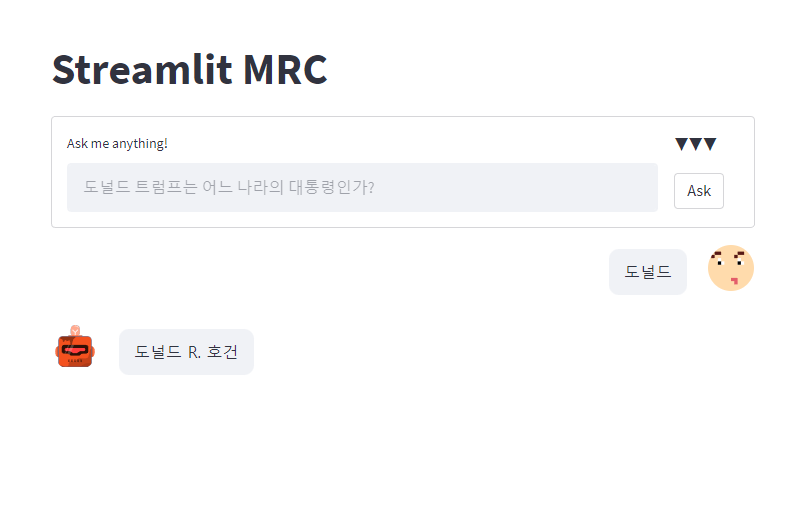
streamlit 스페셜 미션에 곧바로 뛰어들었다.
나는 사실 다른 스페셜 미션을 할 생각도 못했는데
다른 분들은 다른 스페셜 미션까지도 수행하고
또 팀 피어세션 때 그 내용을 공유하기도 했다고 하더라
정말 대단하다라는 생각이 들었다.
나도 Docker 까지는 해보려했지만 지금 시간에 되서야
streamlit 스페셜 미션을 완료했기 때문에
아마 못해보지 않을까 주말까지 일정이 차있다.
따흑흑 아쉽지만 어쩔 수 없지...
일단 뒤로 넘기고 나중에 생각하자.
오늘 오후 시간에는 Level 2 프로젝트에 대한
조사 내용 공유 + 회의를 진행하였다.
2시간 정도 얘기를 하였고
프로젝트에 대한 사항 뿐만 아니라
팀을 어떻게 운영해 나갈 것인가에 대한 의견 또한 주고 받았다.
유익한 시간이었다.
Level 1에서 스스로 아쉽게 행동했던 부분들을
되짚어 보고 보완 방향을 생각해 볼 수 있었다.
(사실 아쉬운 점은 저녁에 산책하면서 많이 생각했었다.)
이후에는 바로 러셀 님의 취업 특강을 들었다.
길게 보고 꾸준히 노력해야 한다 등
자세와 태도에 대한 얘기를 많이 하신 것 같다.
취업에 대해서도 단기적인 안목 보다는 장기적인 안목을 중요하다는 말씀을 해주셨다.
깊이 있는 말씀을 많이 해주셔서 공감 됐고 또 좋았던 것 같다.
특강과 피어세션이 끝난 후,
회의록 정리까지 끝난 다음부터는 본격적인 삽질이 시작되었다.
아래는 슬랙 채널에 적은 시행착오를 옮겨온 거라 말투가 조금 다르게 느껴질 수 있다.
진퇴양난의 상황...
[1] requirements.txt의 라이브러리를 설치한 후,
protobuf dependency가 맞지 않다고 해서
스크린샷 1의 protobuf==3.9.2로 설치했지만

스크린샷 2에서 나온 것처럼 protobuf에 internal_create_key라는 속성이 없다고 함

[2] 그래서 스크린샷 3처럼 protobuf를 그냥 업그레이드 해줬더니

tensorboard와 sagemaker의 dependency 오류가 다시 뜨면서
스크린샷 4의 오류, protobuf의 버젼을 낮춰보라고 함-> 3.20.x 버젼 한번 설치해봐야겠네요.
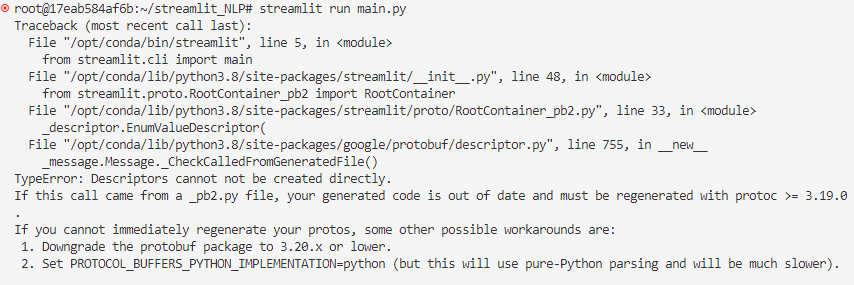
-> 그런데 이거 NLP 예시 코드 run은 원래 되는 건가요? 해보신 분 있을까요?
-> 좀 더 시도해보고 기록 남기겠습니다
참고로 aistages 서버에서 작업하고 있습니다.
앗... 3.20.0 설치하니 되네요. 그런데 tensorboard는 같이 못 쓰는 건가... 나중에 gpu 같이 사용하려면 그거 맞추는 것이 험난할 것 같네요
아 연결 안되네요;;
부스트 캠프 실습 파일도 안되는 군요. 로컬에서는 되는데 tensorboard가 안되니 gpu가 안 돌아가서 그런 건가 싶네요 ㅠ
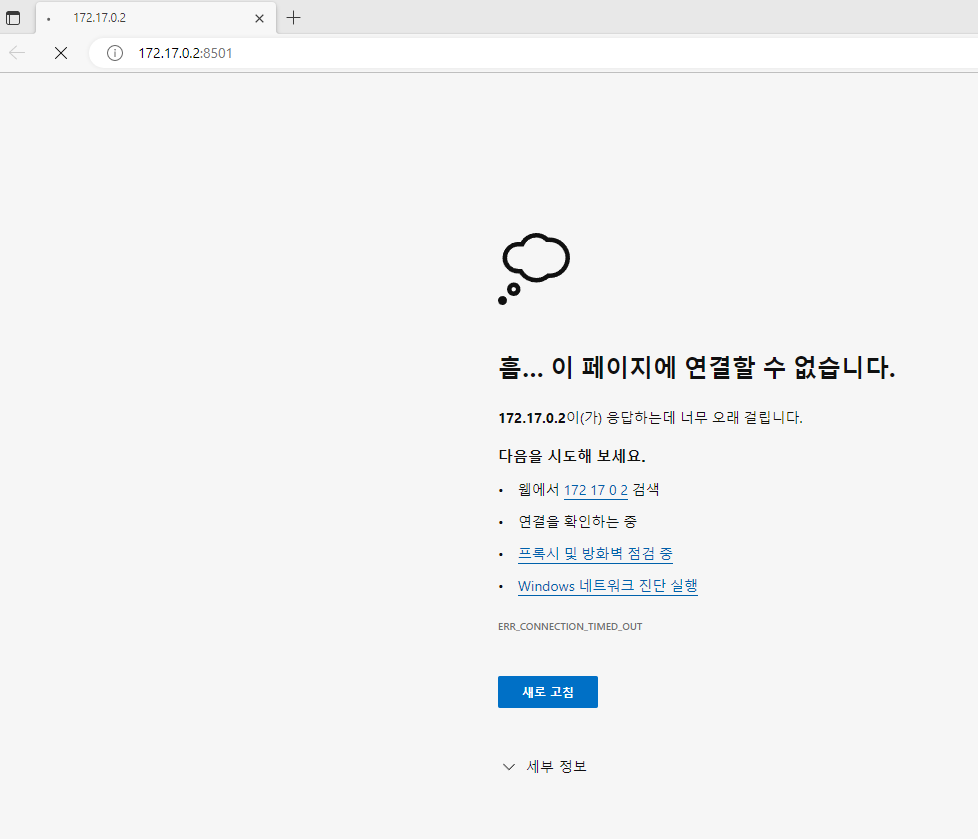
로컬에서 연결이 되긴 하는데 새로운 에러가 뜨네요. 하나씩 기록해가면서 과제를 해봐야겠다...
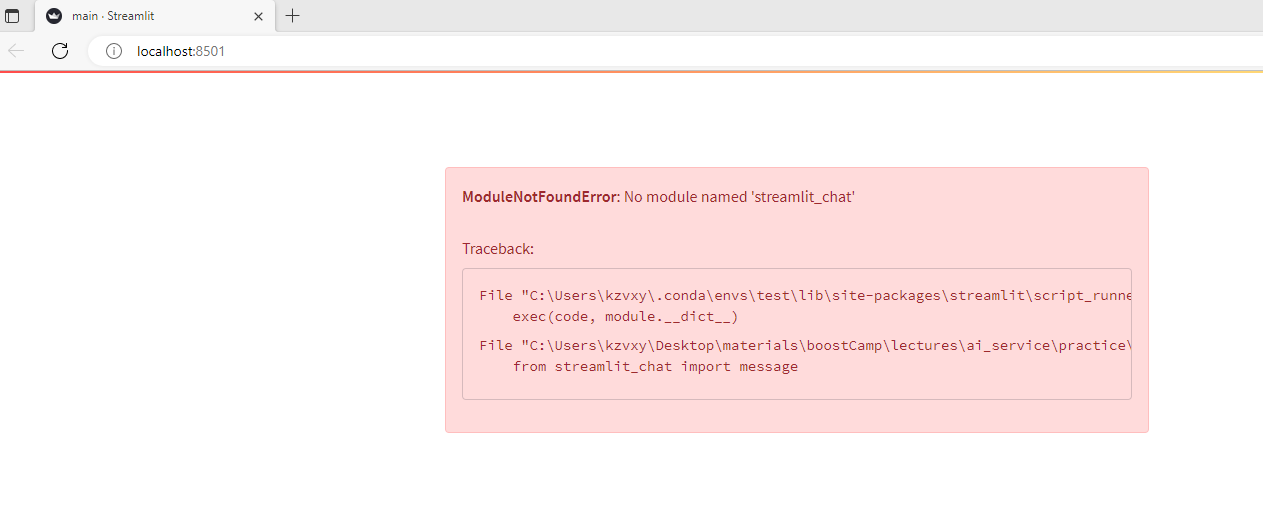
재밌네... 까도 까도 에러가 나오는 느낌. 참고로 그제 실습 파일 돌려 보면서 로컬의 dependency 문제는 어느 정도 해결했습니다.

typing Literal 문제는 typing_extensions를 설치한 후 거기서 Literal을 부르는 방식으로 해결.
아래 링크를 참고했습니다.
https://stackoverflow.com/questions/61206437/importerror-cannot-import-name-literal-from-typing

그런데 palceholder 라는 이상한 argument를 받았다고 또 에러... 이건 이따 보기로
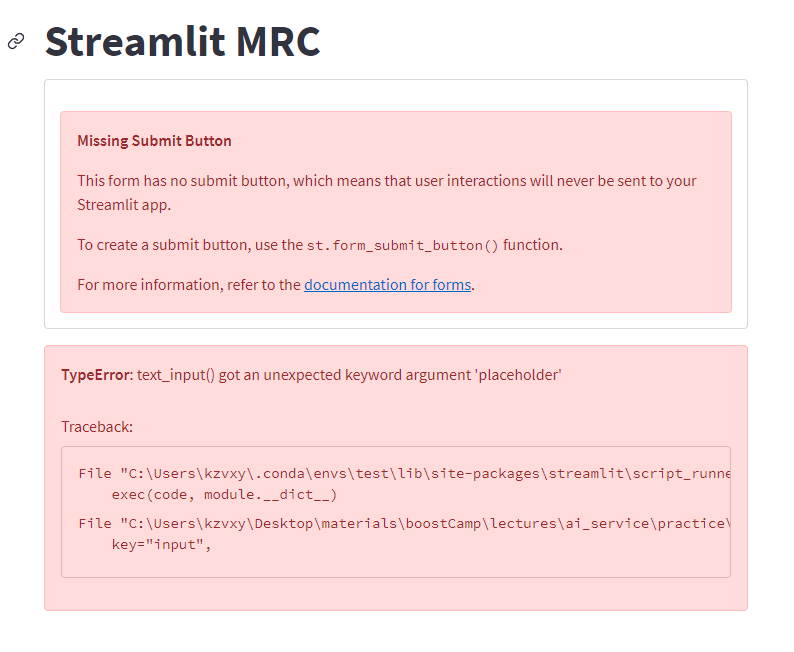
위의 문제는 streamlit이 1.1.0 버젼이라 발생한 문제였네요. 그런데 streamlit을 1.14.0으로 version upgrade 해주니 또 이런 문제가 ㅠ

는 다시 streamlit을 requirements에 나온 1.9.0으로 다운그레이드 해주니 일단 해결된 것처럼 보이네요.

이거 돌려보니
ModuleNotFoundError: No module named 'scipy.sparse._csr' 라는 에러가 또 뜨네요 ㅠ

위의 에러가 python 버젼이 3.7이라 발생한 거 같아서 python 버젼 3.8의 가상 환경을 만들어서 requirements 깔고 실행해보았습니다. 문제 없이 돌아가네요. 이제 STS 만들어 보러 가겠습니다...
여러 번의 삽질과 시행착오를 거쳤지만 결국엔 python 3.8의 가상환경에서 라이브러리를 설치해주니 해결이 됐었다.
더군다나 cuda gpu도 이후에 따로 설치해주니 호환성 문제 없이 잘 돌아갔다.
여기서 얻을 수 있었던 것에 대해 생각해보면
에러 메시지를 보고 문제 코드와 그 parent 모듈들을 확인해보며 문제를 해결할 수 있게 됐다는 것이고
때에 따라서는 그 내부 코드를 수정하는 것까지도 가능하다는 것을 알게 되었다는 것이다.
아쉬운 것은 디버깅? 이후에 모델 만지면서도 느낀 건데 디버깅 방법을 잘 모르고 있다.
print로 찍어 보는 것은 이제 그만...
다음 번에는 디버깅을 확실히 적용해서 문제를 해결해보자!
그런데 아쉽게도 삽질은 여기서 끝나지 않았다.
STS 모듈을 만들기 위해 또 삽질을 하였다.
첫 번째 삽질은 다시 돌아온 dependency 문제였다.
새로 만든 가상환경을 사용하지 않고
기존의 가상환경을 계속 써서 (컴퓨터 다시 시작했음...)
또 각종 모듈의 dependency 문제가 발생해
모듈을 수정했다가 말았다를 반복하다가
가상환경이 변경되지 않은 것을 나중에 알아채고 바꿔주었다.
두 번째 삽질은 모듈을 불러오고 사용하는 데서 발생한 것이었다.
코드를 수정하면서 pytorch-lightning의 Trainer를 사용했는데
Dataloader는 torch.utils.data.DataLoader를 써서 parent가 없다는 오류가 떴다.
이게 원래 class Dataloader(pl.LightningDataModule) 와 같은 식으로
데이터 로더 클래스 안에 pl.LightningDataModule이 들어가야 하는 건데
Dataloader 클래스를 불러오지 않고 이것을 재구성해서 사용하다 보니
torch 문법으로 썼고 이게 Trainer에서 오류를 일으킨 것이었다.
결국 Dataloader를 사용하지 않는 것으로 해결하였다.
또 세 번째는 tokenizer output에 대한 몰이해에서 나온 문제였다.
input_ids의 size가 없다고 에러가 떴는데
이것은 알고 보니 tokenizer의 embedding 결과물이 pt로 전달되지 않은 문제였고
슬랙의 다른 분의 코드를 보고 tokenizer에 return_tensors='pt'를 써서 해결하였다.
마지막 네 번째는 model output의 몰이해에서 비롯된 삽질이었다.
model output의 Json 형식이 맞지 않다고 그래서 살펴보니
output이 Tensor로 나와서 그랬던 거고
그냥 output을 float 함수로 변환해주고 round로 잘라주어 해결하였다.

그래서 결국 모듈을 완성했는데 이거 잘 되는 건가?
사실 잘 모르겠다.
모델링 input, output에 대한 이해가 부족하다.
스스로 구상하고 짤 수 있는 능력이 또 부족하다.
밑바닥부터 시작하는 딥러닝 책 공부 열심히 해야지...
많이 아쉽다.
하지만 어쩔 수 없지.
일단 오늘은 이렇게 마무리해야겠다. 내일은 논문 읽고 자료 만들어야지.
밑바닥 딥러닝도 내일 해야겠다.
오늘도 수고했다. 내일은 더 나아져보자!
'느린 일지 > 부스트캠프 AI Tech 4기' 카테고리의 다른 글
| [학습 일지 / day 38] 삶의 균형 (0) | 2022.11.16 |
|---|---|
| [학습 일지 / day 37] 피로 (4) | 2022.11.12 |
| [학습 일지 / day 35] 정리 (1) | 2022.11.10 |
| [학습 일지 / day 34] 조금의 나태함 (2) | 2022.11.09 |
| [학습 일지 / day 33] 다시 조금씩 (6) | 2022.11.07 |