논문 링크 :
How Contextual are Contextualized Word Representations? Comparing the Geometry of BERT, ELMo, and GPT-2 Embeddings
Replacing static word embeddings with contextualized word representations has yielded significant improvements on many NLP tasks. However, just how contextual are the contextualized representations produced by models such as ELMo and BERT? Are there infini
arxiv.org

그러나, ELMo와 BERT 같은 모델에 의해 생성되는 맥락적 표현은 얼마나 맥락적입니까?
각 단어에 대한 맥락에 특정된 표현이 무한히 많습니까?
아니면 본질적으로 제한된 수의 단어-의미 표현 중 하나가 단어에 할당됩니까?

우선, 우리는 모든 단어의 맥락적 표현이 맥락화 모델의 어떠한 레이어에서도 등방성(*공간이 방향에 따라 다르지 아니하고 같은 성질)이지 않다는 것을 발견했습니다.
다른 맥락에서의 같은 단어의 표현은 두 다른 단어의 cosine 유사도보다 여전히 더 큰 cosine 유사도를 갖지만, 이 자기-유사도는 상위 레이어에서 훨씬 낮습니다.

이는 맥락화 모델의 상위 레이어들이 맥락-특정적인 표현을 더 많이 생성한다는 것을 시사합니다.


최근의 연구에서, ELMo와 BERT와 같은 심층 신경 언어 모델은 그들이 나타나는 맥락에 민감한 단어 백터인 맥락화된 단어 표현을 생성하였습니다.

맥락화된 언어 표현의 성공은 그것이 Language modeling 과제만으로 학습했음에도 불구하고, 높은 전이성과 언어의 과제-특화적이지 않은 특성을 배웠다는 것을 시사합니다.

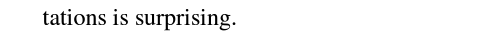
모든 세 모델의 모든 레이어에서, 모든 단어의 맥락화된 단어 표현은 등방성이 아닙니다.
그들은 방향의 측면에서 균일하게 분포되지 않습니다.
대신, 그들은 이방성입니다. 벡터 공간에서 좁은 원뿔을 차지합니다.

같은 단어의 서로 다른 맥락에서의 발생은 동일하지 않은 벡터 표현을 갖습니다. 벡터 유사성이 코사인 유사성으로 정의되는 경우, 이러한 표현은 상위 레이어에서 더욱 서로 유사히지 않습니다.
모델의 상위 계층이 더 많은 맥락-특정적인 표현을 생성함을 시사합니다.

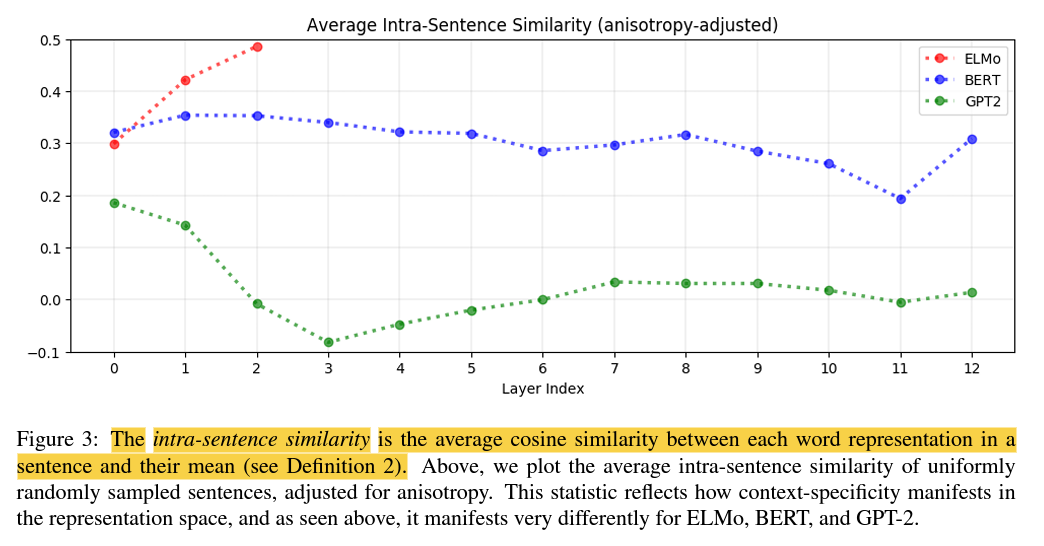
맥락-특정성은 ELMo, BERT, GPT-2에서 매우 다르게 나타납니다.
ELMo에서는, 같은 문장 내의 단어 표현이 상위 레이어에서 맥락-특정성이 증가함에 따라 서로 더 유사해집니다.
BERT에서는, 상위 레이어에서 서로 더 달라지지만 여전히 무작위로 샘플링된 단어들보다는 평균적으로 더 유사합니다.
그러나, GPT-2에서는, 같은 문장의 단어들은 무작위로 선택된 두 단어보다 더 이상 서로 유사하지 않습니다.

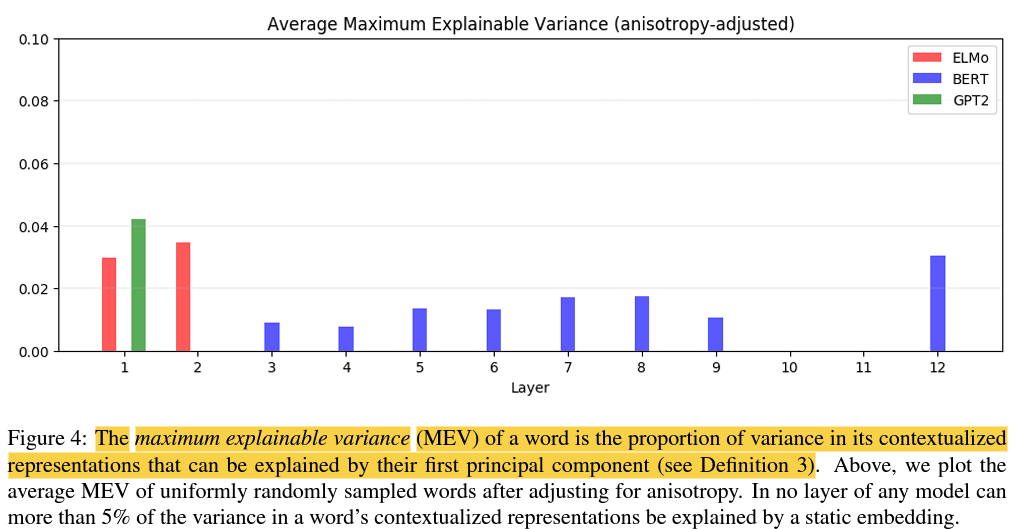
이방성의 효과를 조정한 이후, 평균적으로, 단어의 맥락화된 표현의 분산의 5% 미만 만이 첫 번째 주성분으로 설명될 수 있었습니다.
이는 맥락화된 표현이 한정된 수의 단어-의미 표현에 상응하지 않으며, 가능한 최상의 시나리오에서도 정적 임베딩이 맥락화된 표현을 대체하기에는 부적합하다는 것을 의미합니다.


각 단어에 대해 단일 표현을 생성하기 때문에, 정적 단어 임베딩의 주된 문제는 다의적 단어의 모든 의미가 단일 벡터를 공유해야 한다는 것입니다.

단어의 내부적 표현은 전체 입력 문장의 함수이기 때문에 맥락화된 단어 표현으로 불립니다.

ELMo 양방향 언어 모델링 과제에서 학습된 2-레이어 biLSTM의 내부 state를 연결하여 각 토큰의 맥락화된 표현을 생성합니다.
반대로, BERT와 GPT-2는 각각 양방향 및 단방향 transformer 기반 언어 모델입니다.
12 레이어 BERT 및 12 레이어 GPT-2의 각 transformer 레이어는 입력 문장의 다른 부분에 주의를 기울여 각 토큰의 맥락화된 표현을 생성합니다.


여기에는 단어의 구문적(예, 품사 태그) 및 의미적(예, 단어 관계) 특성을 예측하기 위한 선형 모델 교육이 포함됩니다.
조사 모델은 간단한 선형 모델이 언어 속성을 정확하게 예측하도록 훈련될 수 있는 경우, 표현이 이 정보를 시작부터 암시적으로 인코딩할 수 있다는 전제를 기반으로 합니다.
이러한 분석은 맥락화된 표현이 의미론적 및 구문론적 정보를 인코딩한다는 것을 발견했지만, 이러한 표현이 얼마나 맥락적이며 어느 정도까지 정적인 단어 임베딩으로 대체될 수 있는지에 대해 답변할 수는 없었습니다.


BERT의 base cased version을 선택했습니다.
ELMo, BERT 그리고 GPT-2가 각각 2, 12, 12 개의 히든 레이어를 가지지만, 우리는 각 맥락화 모델의 0번 째 레이어로 입력 레이어를 포함시켰습니다. 0번 째 레이어가 맥락화되지 않았기 때문에, 후속 레이어에서 수행한 맥락화를 비교하는 데 유용한 기준이 됩니다.

만약 모델이 양 문장에서 'dog'에 대한 같은 표현을 생성한다면, 맥락화가 되지 않았다고 추론할 수 있을 것입니다. 반대로, 만약 두 표현이 다르다면, 우리는 어느 정도 맥락화가 되었다고 추론할 수 있을 것입니다.
우리는 분석에서 5개 보다 적은 고유 맥락에서 등장하는 단어들은 고려하지 않았습니다.

우리는 세 개의 다른 metric을 사용하여 단어 표현이 얼마나 맥락적인지 측정하였습니다. 자기 유사도, 문장 내 유사도, 최대 설명 가능 분산.

$w$를 문장 {$s_{1}, \ldots, s_{n}$}과 인덱스 {$i_{1}, \ldots, i_{n}$}에서 등장하는 단어라 했을 때,
$w=s_{1}[i_{1}] = \ldots = s_{n}[i_{n}]$입니다.
$f_{\ell}(s,i)$ 함수는 $s[i]$를 모델 $f$의 레이어 $\ell$ 안의 그것의 표현에 매핑해주는 것이라 하겠습니다.
cos는 코사인 유사도를 의미합니다.
레이어 $\ell$ 안의 단어 $w$의 자기-유사도는 다른 말로하면, n개의 고유한 맥락 사이에서 맥락화된 표현들 사이의 평균 코사인 유사도입니다.
만약, 레이어 $\ell$이 표현을 전혀 맥락화하지 않았다면, $SelfSim_{\ell}(w)=1$ 입니다. (즉, 모든 맥락에서 표현들이 동일)
$w$에 대한 표현이 더 맥락화될 경우, 그 자기-유사도는 더 낮을 것이라 기대됩니다.

$s$는 $n$ 개의 단어들의 $<w_{1},\ldots,w_{n}>$ 시퀀스로 이루어진 문장입니다.
$f_{\ell}(s,i)$는 $s[i]$를 모델 $f$의 레이어 $\ell$에 그 표현을 매핑하는 함수입니다.
문장의 문장-내 유사도는 단어 표현과 벡터의 평균일 뿐인 문장 벡터 간의 평균 코사인 유사도입니다.
이것은 벡터 공간에서 맥락-특정성이 어떻게 나타나는지를 포착합니다.
예를 들어, $IntraSim_{\ell}(s)$와 $SelfSim_{\ell}(w)$가 $s$에 속하는 모든 $w$에 대해 낮다면, 모델은 해당 레이어에서 문장 내의 모든 다른 단어 표현과 꽤나 구별되는 맥락-특정 표현을 각 단어에 제공하여 단어를 맥락화합니다.
$IntraSim_{l}(s)$는 높지만 $SelfSim_{\ell}(w)$가 낮은 경우, 이는 덜 미묘한 맥락화이며, 문장 내의 단어들이 벡터 공간에서 그것의 표현이 수렴되는 방식으로 단순히 맥락화된다는 것을 의미합니다.


$w$를 문장 {$s_{1}, \ldots, s_{n}$}과 인덱스 {$i_{1}, \ldots, i_{n}$}에서 등장하는 단어라 했을 때,
$w=s_{1}[i_{1}] = \ldots = s_{n}[i_{n}]$입니다.
$f_{\ell}(s,i)$는 $s[i]를 모델 $f$의 레이어 $\ell$에 그 표현을 매핑하는 함수입니다.
$[f_{\ell}(s_{1},i_{1}) \ldots f_{\ell}(s_{n},i_{n})]$은 $w$의 발생 행렬이고 $\sigma_{1} \ldots \sigma_{m}$은 이 행렬의 첫 번째 $m$ 특이값이며, 최대 설명 가능 분산은 다음과 같습니다.
$MEV_{\ell}(w)$는 첫 번째 주성분으로 설명할 수 있는 주어진 레이어에 대한 $w$의 맥락화된 표현의 분산 비율입니다.
이것은 정적 임베딩이 단어의 맥락화된 표현을 얼마나 잘 대체할 수 있는지에 대한 상한선을 제공합니다.

단어 벡터들이 완벽하게 등방성일 경우, $SelfSim_{\ell}(w)=0.95$는 $w$의 표현이 형편없게 맥락화되었음을 암시하며
단어 벡터들이 이방성일 경우, $SelfSim_{\ell}(w)=0.95$는 $w$의 표현이 잘 맥락화되었음을 암시합니다.
이는 다른 맥락 속에서의 $w$의 표현이 두 무작위로 선택된 단어들보다 평균적으로 서로 더 유사하지 않기 때문입니다.

이방성의 영향을 조정하기 위해, 우리는 각 맥락 측정에 대해 각 하나씩 세 개의 이방성 baseline을 사용하였습니다.
주어진 레이어에서 단어 표현의 이방성이 클수록 이 baseline은 1에 가까워집니다.


그런 다음 각 측정값에서 해당하는 baseline을 빼서 이방성-조정 맥락성 측정치를 얻었습니다.
여기서 $O$는 모든 단어 발생의 집합이고 $f_{\ell}(\cdot)$는 단어 발생을 모델 $f$의 레이어 $\ell$의 표현에 매핑합니다.
달리 명시되지 않는 한, 나머지 페이퍼의 맥락성 측정에 대한 참조는 이방성-조정 측정을 참조하며, 여기서 원시 측정과 baseline은 모두 1K의 균일하게 무작위 샘플링된 단어 표현으로 추정됩니다.

맥락화된 표현은 모든 비입력 레이어에서 이방성입니다.
이방성의 기하학적 해석은 단어 표현이 모든 방향에서 동일하지 않고 벡터 공간에서 모두 좁은 원뿔을 차지한다는 것입니다. 이방성이 클 수록 이 원뿔은 더 좁아집니다.
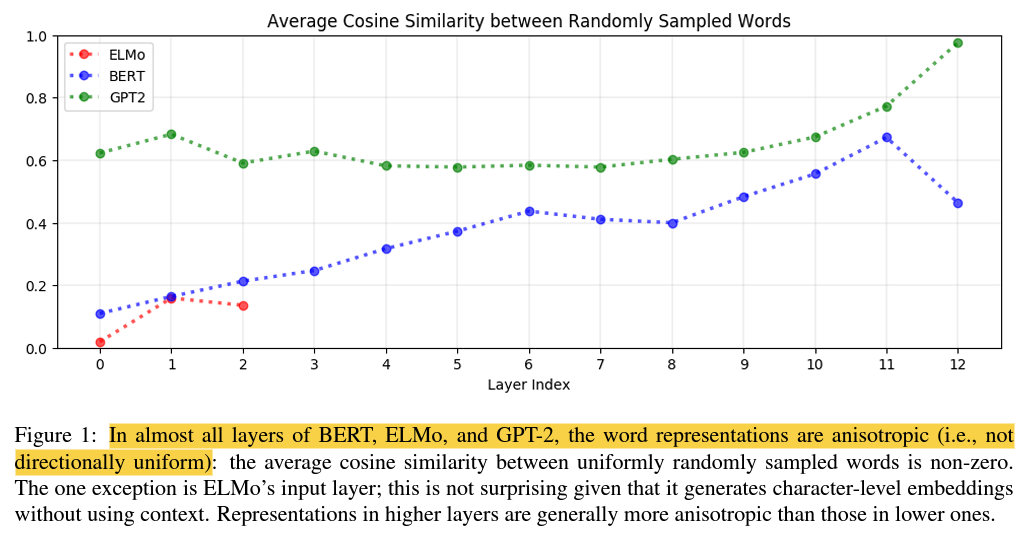


맥락확된 레이어는 일반적으로 상위 레이어에서 더 이방성을 띕니다.
이는 높은 이방성이 맥락화 과정에 내재되어 있거나 적어도 그것의 부산물임을 의미합니다.


맥락화된 단어 표현은 상위 레이어에서 더욱 맥락-특정적입니다.

세 가지 모델 모두에서 레이어가 더 높을 수록, 평균적으로 자기 유사도는 더 낮아집니다.
즉, 레이어가 더 높을 수록 맥락화된 표현이 더 맥락에 특정적인 표현이 됩니다.
따라서, 신경 언어 모델의 상위 레이어는 주어진 맥락에 대한 다음 단어를 더 정확하게 예측하기 위해 더 많은 맥락 특정적인 표현을 학습합니다.
세 가지 모델 중 GPT-2의 표현이 가장 맥락-특정적이며, GPT-2의 마지막 레이어에 있는 표현은 거의 최대로 맥락-특정적입니다.
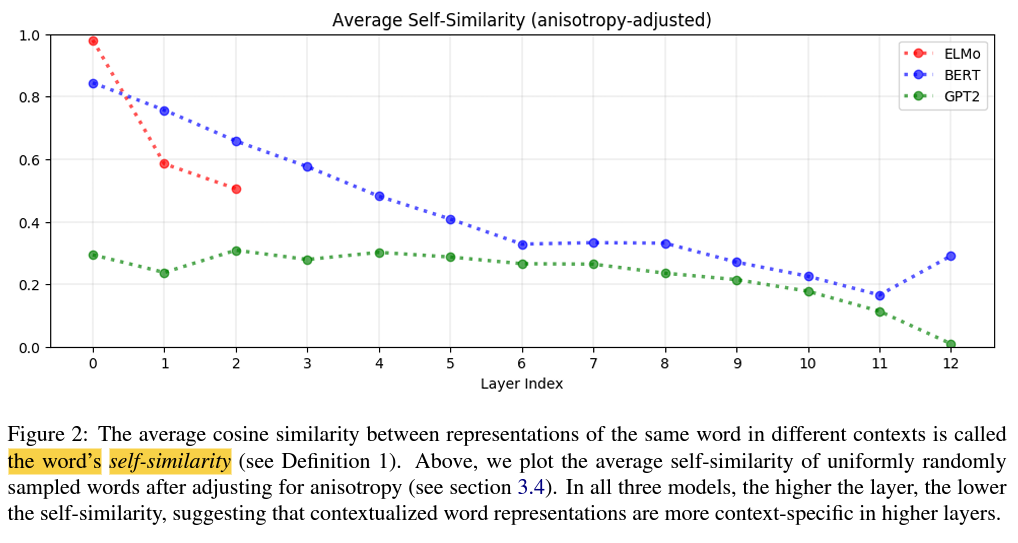


불용어(예를 들어, 'the', 'of', 'to')는 가장 맥락-특정적인 표현에 속했습니다.
이 발견은 단어의 고유한 다의성이 아니라 단어가 나타나는 다양한 맥락이 맥락화된 표현의 변화를 주도한다는 것을 의미합니다.
ELMo, BERT 및 GPT-2는 각 단어에 한정된 수의 단어 의미 표현 중 하나를 단순하게 할당하는 것이 아니었습니다. 그렇지 않다면, 단어의 의미가 거의 없는 단어의 표현에 그다지 많은 변화가 있지 않았을 것입니다.

맥락-특정성은 ELMo, BERT, GPT-2에서 매우 다르게 나타납니다.
동일한 문장의 단어 표현이 단일 지점으로 수렴합니까, 아니면 다른 맥락에서의 그것의 표현과 여전히 구별되면서 서로 구별되는 것입니까?


ELMo에서, 동일 문장의 단어들은 상위 레이어에서 서로 더 비슷해집니다.

BERT에서, 동일 문장의 단어들은 상위 레이어에서 서로 더 달라집니다.
이것은 주변 문장이 단어의 의미를 알려주지만, 두 단어가 같은 맥락을 공유하기 때문에 반드시 비슷한 의미를 가질 필요는 없다는 것을 인식하는 BERT가 ELMo에서 보다 더 미묘하게 맥락화되었음을 의미합니다.

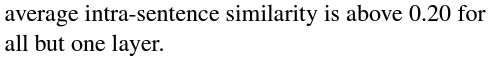
GPT-2에서, 동일한 문장의 단어 표현들은 더 이상 무작위로 샘플링된 단어들보다도 더 서로 유사하지 않습니다.

GPT-2의 성공은 세 가지 모델 모두에서 맥락-특정성을 수반하는 이방성과는 달리 높은 문장-내 유사성이 맥락화에 내재되지 않았다는 것을 의미합니다.
동일한 문장의 단어는 두 개의 무작위 단어 표현보다 서로 더 유사하지 않은 표현 없이 고도로 맥락화된 표현을 가질 수 있습니다.


평균적으로 단어의 맥락화된 표현의 분산 중 5% 미만이 정적 임베딩으로 설명될 수 있습니다.

그림 4에는 표시되지 않지만 많은 단어의 원시 MEV는 실제로 이방성 baseline 아래에 있습니다. 즉, 단일 단어의 모든 표현에 걸친 분산보다 더 큰 비율의 모든 단어에 대한 분산이 단일 벡터로 설명될 수 있습니다.
이것은 맥락화 모델이 각 단어에 한정된 수의 단어 의미 표현 중 하나를 단순하게 할당하는 것이 아님을 의미합니다. 그렇지 않으면 설명된 분산의 비율이 훨씬 더 높아질 것입니다.


하위 레이어에 있는 맥락화된 표현의 주요 구성 성분은 많은 벤치마크에서 GloVe 및 FastText를 능가합니다.
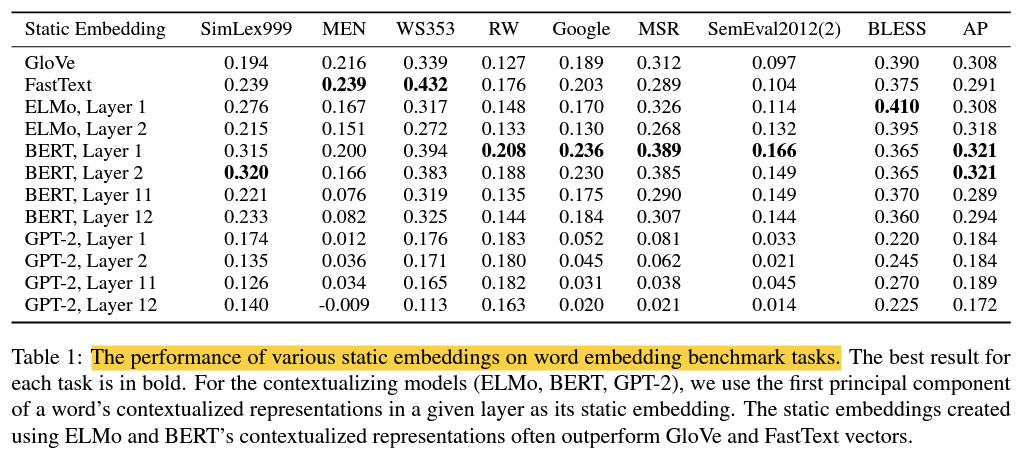


성능이 가장 좋은 PC 정적 임베딩은 BERT의 첫 번째 레이어에 속하지만 BERT 및 ELMo의 다른 레이어에서 가져온 것들도 대부분의 벤치마크에서 GloVe 및 Fast Text 보다 성능이 뛰어납니다.
고도로 상황-특정적인 표현의 PC는 기존 벤치마크에 덜 효과적입니다.

언어 모델링 목표에 이방성 페널티를 추가하여 맥락화된 표현이 더 등방성이 되도록 장려하면 더 나은 결과를 얻을 수도 있습니다.

