논문 링크 :
EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
We present EDA: easy data augmentation techniques for boosting performance on text classification tasks. EDA consists of four simple but powerful operations: synonym replacement, random insertion, random swap, and random deletion. On five text classificati
arxiv.org
코드 링크 :
GitHub - jasonwei20/eda_nlp: Data augmentation for NLP, presented at EMNLP 2019
Data augmentation for NLP, presented at EMNLP 2019 - GitHub - jasonwei20/eda_nlp: Data augmentation for NLP, presented at EMNLP 2019
github.com
한국어 구현 코드 링크 :
GitHub - catSirup/KorEDA: EDA를 한국어 데이터에서도 사용할 수 있도록 WordNet을 추가
EDA를 한국어 데이터에서도 사용할 수 있도록 WordNet을 추가. Contribute to catSirup/KorEDA development by creating an account on GitHub.
github.com
내용 요약 :

구현 방식 소개
- SR : stop words가 아닌 n개의 단어를 무작위로 선택, 랜덤한 유의어로 교체
- RI : stop word가 아닌 문장 내 무작위 단어의 무작위 유의어를 찾고 문장 내 무작위 위치에 삽입, n번 반복
- RS : 문장 내 두 단어를 무작위로 선택하고 그 위치를 뒤바꿈, n번 반복
- RD : p 확률로 문장 내의 각 단어를 무작위로 제거

구현 예시
- SR, RI, RS, RD

EDA(Easy data augmentation) 유무에 따른 성능 차이
- full datasets에 대해 0.8의 평균 성능 향상치, N=500 일 때 3.0%.

original 문장과 augmented 문장의 Latent space 시각화
- 증간된 문장이 원본 문장에 매우 근접해 있음을 확인할 수 있음


alpha 값에 따른 성능 변화
- alpha =0.1 이 sweet spot
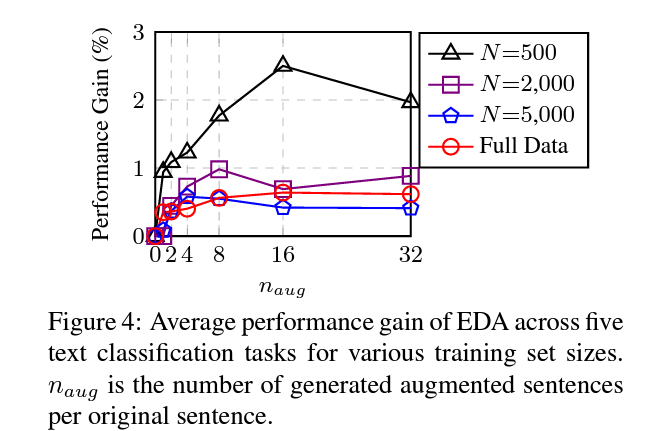
n (증강 문장 수)에 다른 성능 변화
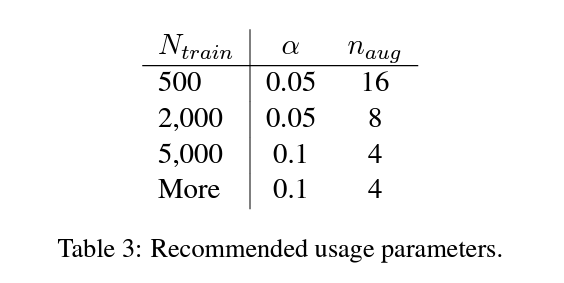
- table 3의 파라미터를 추천

EDA의 한계
- 데이터가 충분할 때 성능 향상은 크지 않다.
- pre-trained 모델 사용 시에 의미 있는 성능 향상을 가지지 못한다.
- 관련 작업과의 공정한 비교는 중요하지 않다.