논문 링크 :
Should We Rely on Entity Mentions for Relation Extraction? Debiasing Relation Extraction with Counterfactual Analysis
Recent literature focuses on utilizing the entity information in the sentence-level relation extraction (RE), but this risks leaking superficial and spurious clues of relations. As a result, RE still suffers from unintended entity bias, i.e., the spurious
arxiv.org
Github 링크 :
GitHub - vanoracai/CoRE
Contribute to vanoracai/CoRE development by creating an account on GitHub.
github.com
아래 내용은 논문의 구절들을 가져와 번역하고 정리한 것입니다.
prior knowledge
RE (Relation Extraction, 관계 추출)
- 문장 수준 관계 추출(RE)은 textual context에서 entity mentions(names) 간의 관계를 추출하여 비정형 텍스트의 구조적 인식을 얻는 중요한 단계입니다.
- 기계와 인간 모두에게 RE는 textual context와 entity mentions에 대한 결합된 이해가 필요합니다.
- 예를 들어, 모델이 학습 중 객체 entity가 스위스 일때 "국가 거주"라는 관계를 다른 관계보다 많이 본다면, 모델은 이 관계가 텍스트에 존재하지 않더라도 추론하는 동안 이 관계를 스위스와 연관시킬 수 있습니다.
- 인간 : 인과관계 기반 / RE 모델 : 우도(likelihood) 기반
Entity Bias
- Entity mentions(names)와 관계 사이의 가짜 상관관계
- 텍스트에 존재하지 않는 관계를 추출하도록 RE 모델을 오도할 수 있음 (편향된 관계 예측)
- entity mentions를 마스킹하는 것 -> entity의 의미론적 정보 손실
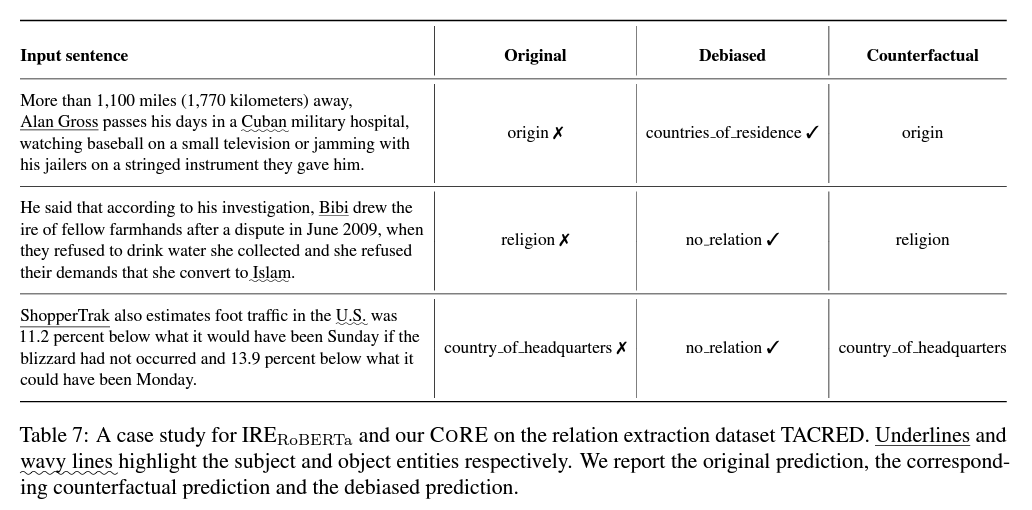
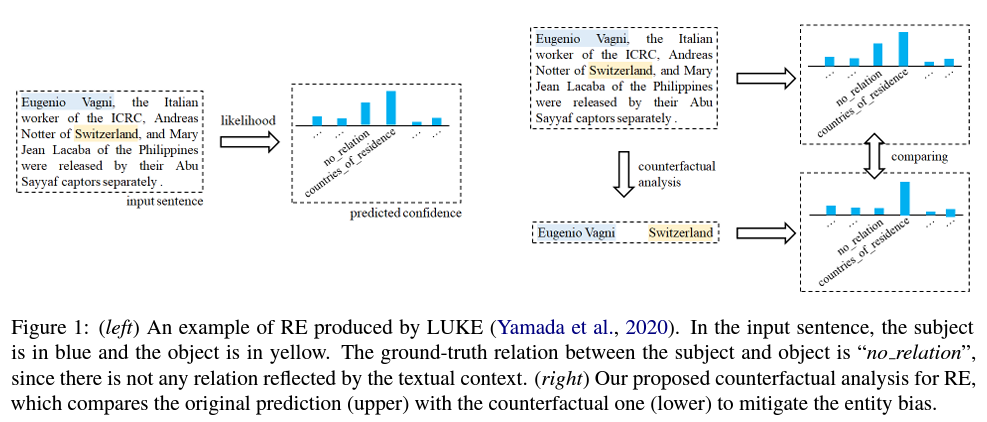
Counterfactual analysis
- 반사실적 사고는 "사실에 반하는 것"입니다. 이러한 생각은 상황이 어떻게 달라졌을 수 있었는지 생각할 때 발생하는 "만약?"과 "만약 ...만 했더라면 ..."으로 구성됩니다.
- textual context를 보지 못했더라면 그럼에도 불구하고 여전히 동일한 관계를 추론할 수 있습니까?
- 구체적으로, 우리는 본질적으로 원래 인스턴스와 반사실 인스턴스를 비교합니다. 즉, entity mentions는 그대로 유지하면서 textual context만 지워버립니다. 그렇게 함으로써 entity 정보를 잃지 않고 textual context의 주요 영향에 집중할 수 있습니다.
CoRE (Counterfactual Analysis based Relation Extraction)
- 편향 제거 방법
- 학습 프로세스를 변경하지 않고 추론 중에 기존 RE 시스템의 편향을 없애는 모델에 구애받지 않는 방법
- entity 정보를 잃지 않고 textual context의 주요 영향에 초점을 맞추도록 RE 모델을 안내
Steps
1. 모델이 원래 학습 세트의 편향에 노출되도록 합니다.
2. RE에 대한 인과관계 그래프를 구성합니다.
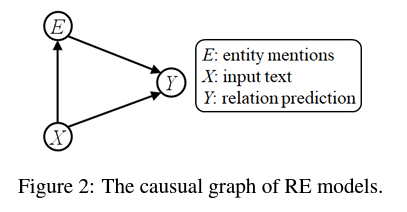
예를 들어, 앞서 언급한 $X$ = "Mary과 Jerry를 낳았다." 라는 문장에서, entity는 $E$=['Mary', 'Jerry"] 입니다.
3. 각 인스턴스에서 특정 entity mentions의 인과 영향을 포착하는 entity 편향을 추출하고 완화하기 위해 인과 관계 그래프에 대한 반사실 분석을 수행합니다.
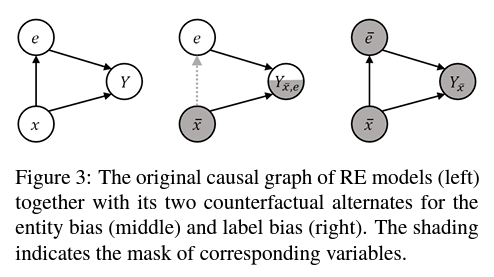
우리는 interventions과 그 유도된 반사실로 entity 편향을 제거합니다. 반사실은 "사실에 반하는 것"을 의미하며 변수에 값의 가상의 조합을 추가로 할당하는 한 단계를 수행합니다.
예를 들어, $X$를 마스킹하여 입력 textual context를 제거할 수 있지만 원래 entity mentions로서 $E$를 유지할 수있습니다. 마치 $X$가 여전히 존재하는 것처럼요.
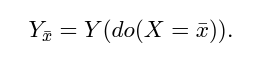
원래 예측 $Y_{x}$와 entity 편향에 대한 반사실적 $Y_{\bar{x},e}$, 그리고 Label 편향에 대한 $Y_{\bar{x}}$의 인과 관계 그래프가 그림 3에 시각화되어 있습니다.
$Y_{\bar{x}}$는 textual context와 entity mentions가 모두 제거된 반사실적 입력에 해당합니다.
4. 적응형 가중치로 편향 완화 작업을 수행하여 RE에 대한 편향이 제거된 결정을 생성합니다.
최종 목표는 편향되지 않은 예측을 위해 $X$에서 $Y$로의 textual context의 직접적인 영향을 사용해 예측에서 label 편향과 entity 편향을 완화하는 것입니다. $Y_{x}$, $Y_{\bar{x},e}$, $Y_{\bar{x}}$, 학습에서 추론으로의 편향 확산을 차단하기 위해.
편향 완화를 통한 편향이 제거된 예측은 개념적으로 단순하지만 실험적으로 효과적인 요소-별 뺄셈 연산을 통해 공식화할 수 있습니다.
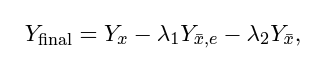
$\lambda1$과 $\lambda2$는 각각 entity 편향과 label 편향을 완화하기 위한 term의 균형을 맞추는 두 개의 독립적인 하이퍼파라미터입니다.
(* entity 타입은 후보 관계를 제한할 수 있기 때문에, 가능한 경우 entity 타입 정보를 사용하여 추론에 대한 후보 관계를 제한합니다. 그리고 이는 관계 추출을 위한 entity 타입의 영향을 강화합니다.)
Experimental
DataSets
TACRED / SemEval / TACRED-Revisit / Re-TACRED
Models
G-SGC / SpanBERT / CP / RECENT / KnowPrompt / LUKE / IRE
Compared debiasing techniques
Focal / Resample / Entity Mask / CFIE
Other Settings
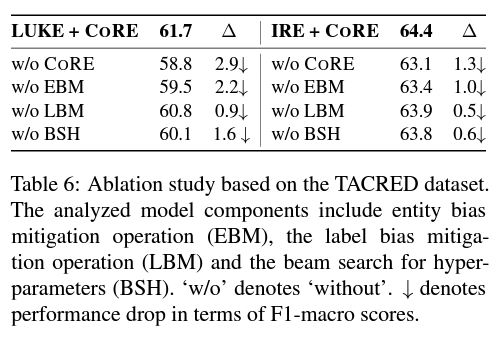
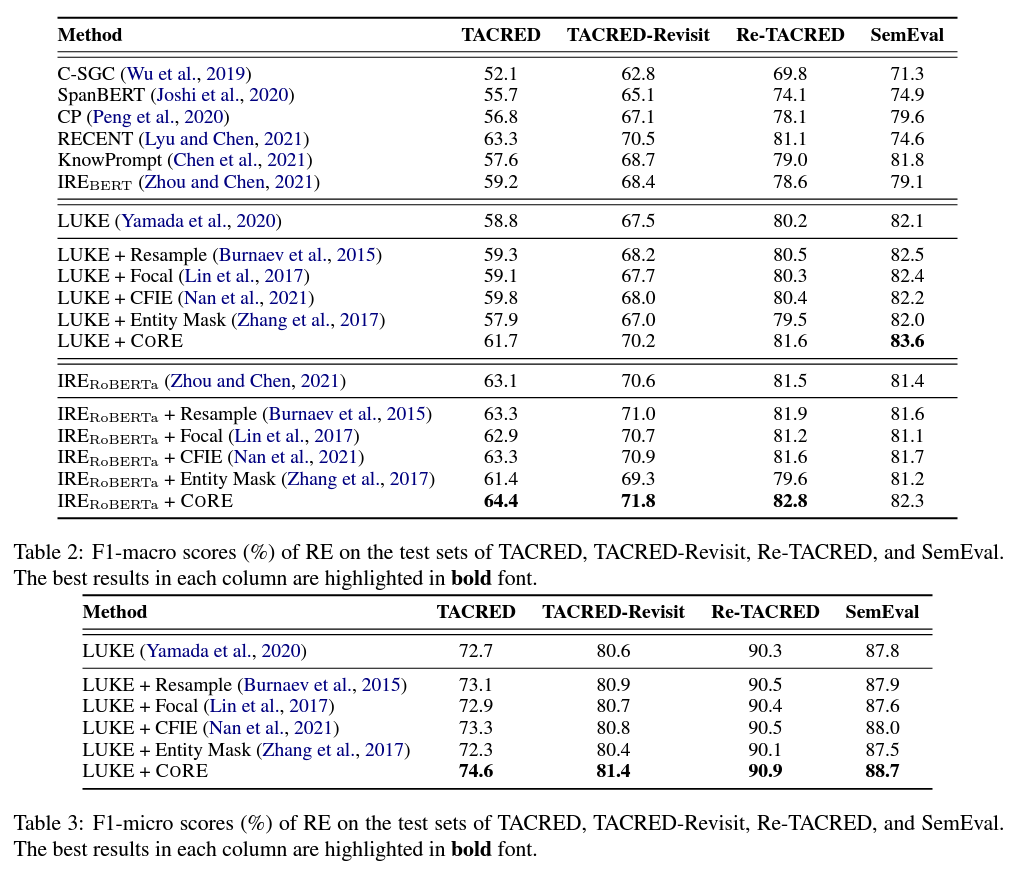
* F1-macro는 편향 정도를 반영하는 데 F1-micro보다 더 적합합니다. 특히 왜곡이 심한 경우에는 F1-macro가 각 카테고리의 성능에 고르게 영향을 받기 때문입니다. 즉, 카테고리에 민감합니다. 하지만 F1-micro는 단순히 모든 인스턴스에 동일한 가중치를 줍니다.
CORE 방법의 하이퍼파라미터에 대해, 방정식 3에서 하이퍼미터의 검색 범위를 [-2,2]로 검색 단계는 0.1로 설정하였습니다. 모든 실험에 대해, 서로 다른 무작위 시드를 사용하여 5회 훈련 실행의 중앙값 F1 점수를 보고하였습니다.
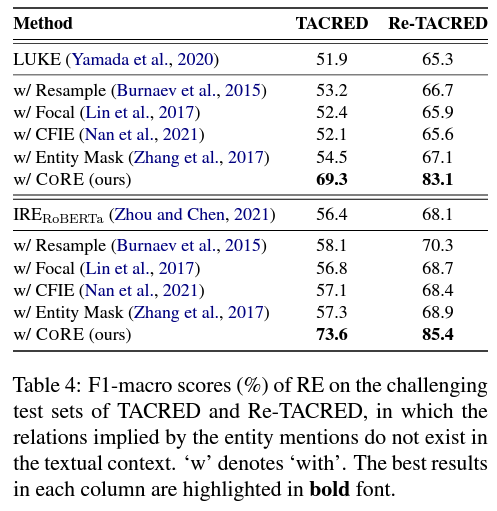
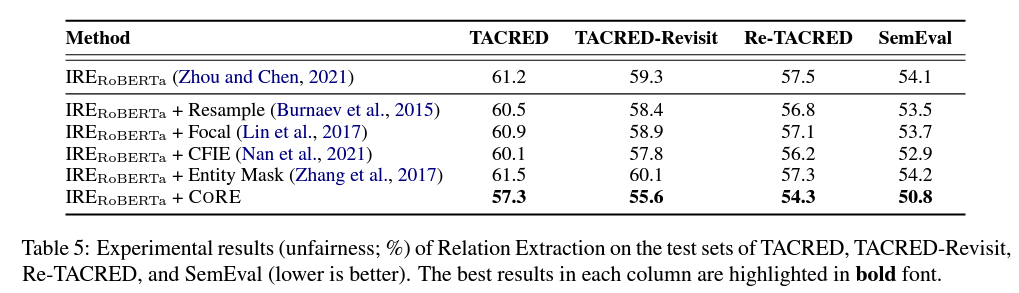
학습된 모델에 의해 생성된 예측이 더 불균형할수록/비뚤어질수록 미리 정의된 범주에 대해 더 많은 불공평한 기회가 제공되고 학습된 모델이 더 불공평하게 차별적이 됩니다.