Language Models are Few-Shot Learners
Recent work has demonstrated substantial gains on many NLP tasks and benchmarks by pre-training on a large corpus of text followed by fine-tuning on a specific task. While typically task-agnostic in architecture, this method still requires task-specific fi
arxiv.org
Abstract
- Language model의 사이즈를 키우는 것(scaling up)이 과제에 유연한 few-shot 성능을 크게 상승시킴
- gradient update나 fine-tuning없이 모델과의 상호 작용으로 모든 과제에 대응 가능
- 인간 평가자가 분간하기 어려울 정도의 news articles를 생성할 수 있음
1. Introduction
- 기존 패러다임의 문제점 : 과제 특정적인 데이터셋과 과제 특정 fine-tuning이 필요
- 새로운 과제를 위해 큰 규모의 라벨된 데이터셋이 필요하다는 것은 모델의 적용성을 제한하는 것, 데이터셋 수집에도 어려움 존재
- 학습 데이터셋에서 의심스러운 상관 관계를 도출할 가능성이 존재 (with the expressiveness of the model and the narrowness of the training distribution), 학습 데이터셋 분포에 과도하게 특정될 가능성, 일반화 역량이 떨어짐
- 인간의 경우, 새로운 언어 과제를 위해 큰 규모의 지도 데이터셋이 필요하지 않음, 그러한 유동성과 일반성이 필요
- meta-learning
- 학습 시에는 다양한 스킬과 패턴 인지 능력을 발달시키고, 추론 시에는 요구되는 과제를 파악하고 바로 적응하는 것
- in-context learning
- 과제를 특정하는 지시나 묘사 등을 입력에 포함시켜 다음에 무엇이 올지를 예측하는 방식으로 이후 과제를 완성하는 것

- meta-learning
- zero-shot, one-shot, few-shot
- 추론 시에 얼마나 많은 묘사가 주어지느냐에 따라 다름
- zero-shot, one-shot, few-shot

- meta-learning
- 175B parameter 자기 회귀 모델(autoregressive moel)을 학습
- prompt가 주어졌을 때 더 빠르게 적응
- 모델 크기가 클 수록, in-context 예제의 수가 많을 수록 성능 우수
- 다양한 테스크에 적용 가능
- 보다 큰 모델이 meta-learning을 잘 수행
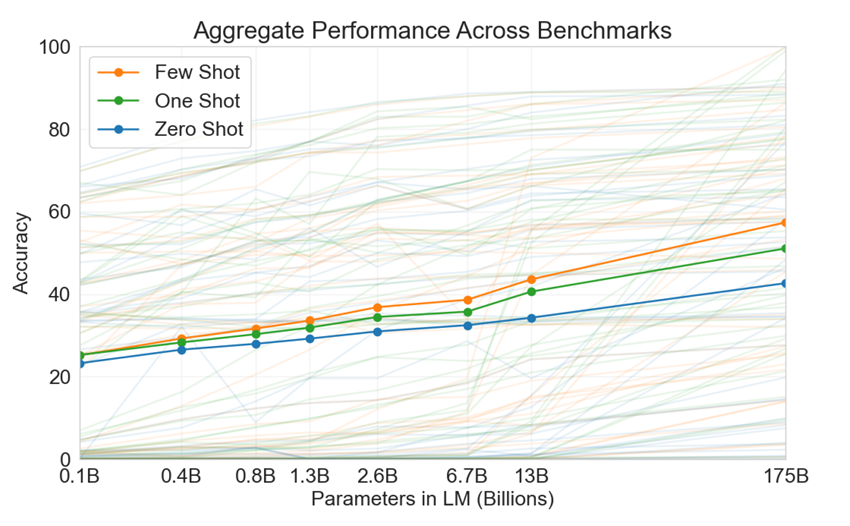
2. Approach
- Fine-Tuning (FT)
- 사전 학습 모델의 가중치를 주어진 과제에 특정된 지도 학습 데이터셋으로 업데이트하는 방식
- 장점 : 성능 우수
- 단점 : 과제에 대해 큰 규모의 새로운 데이터셋이 필요, 분포를 넘어서는 것에 대해 열악한 일반화 능력을 가질 가능성 존재, 학습 데이터셋에 대해 의심스러운 관계를 설정할 수 있음, 인간과 비교하기 어려움
- Few-Shot (FS)
- 추론 시에 과제에 대한 여러 개의 묘사를 주는 방식
- 장점 : 과제 특정적인 데이터에 대한 필요 감소, 과도하게 영역이 좁은 fine-tuning 데이터셋을 학습하지 않아도 됨
- 단점 : 성능이 아직 뒤처짐, 과제 특정적인 데이터가 아직 작은 양이나마 필요
- One-Shot (1S)
- 추론 시에 과제에 대한 1 개의 묘사를 주는 방식
- 과제에 대한 인간과의 의사 소통 방식과 유사함
- Zero-Shot (0S)
- 추론 시에 과제에 대한 묘사를 주지 않는 방식
- 장점 : 극한의 편리함, 잠재적 강건성, 의심스러운 관계 회피
- 단점 : 매우 어려운 방식

2.1 Model and Architecture
- GPT-2와 같은 모델 및 아키텍쳐
- 수정된 초기화 방식, 사전 정규화, 뒤집을 수 있는 토큰화
- +) alternating dense and locally banded sparse attention patterns in the layers of the transformer (similar to the Sparse Transformer)

2.2 Training Dataset
- Common Crawl dataset
- 고품질의 참조 corpora와 유사도를 비교하여 filtering
- 어렴풋한 중복제거
- 고품질 참조 corpora 추가
- WebText dataset
- two internet-based books copora
- English-language Wikipedia

Contamination(오염, development set이나 test set에 train data가 포함되는 것)을 막기 위해 모든 벤치마크에서 중복값들을 제거
2.3 Training Process
- larger models can typically use a larger batch size, but require a smaller learning rate.
2.4 Evaluation
- multiple choice (여러 개의 옵션 중에서 맞는 것을 고르는 것) : 각 completion의 LM likelihood를 뽑아 비교, 데이터셋이 작을 경우 정규화함
- 2진 분류 과제 : 옵션을 의미 있는 명명으로 변환 후 multiple choice와 같이 처리
- free-form completion : beam search 사용, F1 유사도 점수, BLEU, EM 등을 활용
3. Results
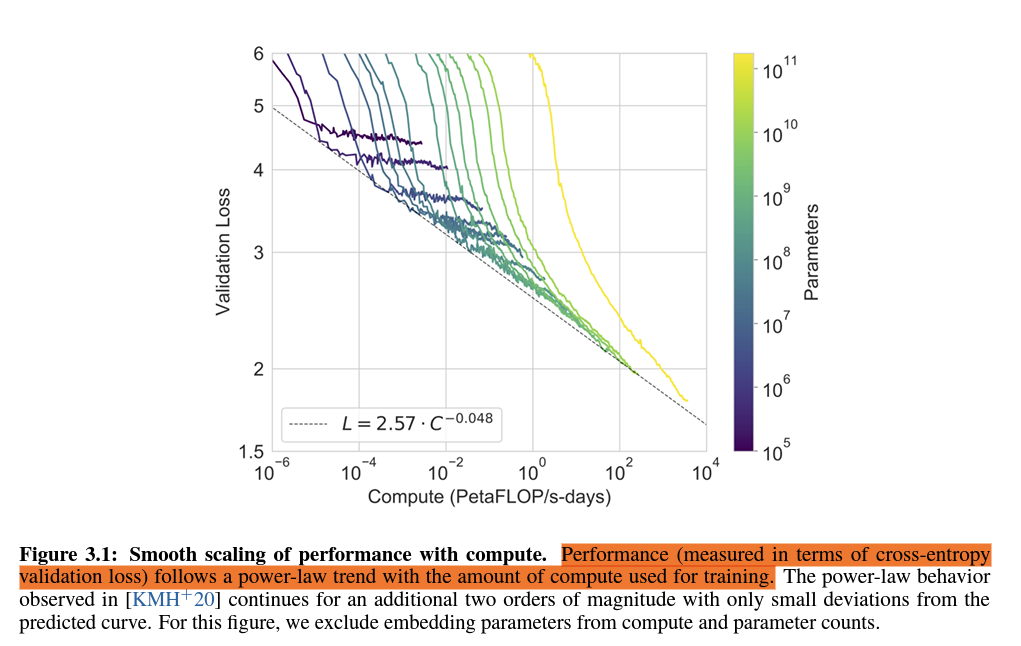
3.1 Language Modeling, Cloze, and Completion Tasks
- 언어 모델링 성능, 관심 있는 단일 단어 예측, 문장 또는 단락 완성, 텍스트의 가능한 완성 선택 등을 시험

Details
3.1.1 Language Modeling
- Penn Tree Bank의 새로운 소타 모델을 사용, 15 points의 substantial margin, perplexity 20.50
- zero-shot만 실험
3.1.2 LAMBADA
- text의 장범위 의존성 모델링을 시험하는 데이터셋
- 모델은 context 내 단락을 읽고 문장의 마지막 단어를 예측하도록 지시받음
- 문장의 마지막 단어를 예측하는 과제는 기존 언어 모델으로서는 불가능한 일이었음
- 정확한 끝맞침과 문맥에 대한 유효한 연속이 가능해야 했기 때문
- 떄문에 stop-word filters를 사용
- few-shot setting은 cloze-task로 과제를 “frame”하도록 해주었음(filll-in-the blank format)

3.1.3 HellaSwag
- 이야기의 최고의 엔딩을 뽑거나 지시 사항 셋을 뽑는 데이터셋
3.1.4 StoryCloze
- 5문장 길이의 이야기에서 적절한 엔딩을 선택하는 데이터셋
3.2 Closed Book Question Answering

- 광범위한 사실 기반 지식에 대한 질의에 답하는 능력을 시험
- 엄청난 양의 가능한 쿼리로 인해, 보통 관련 text를 찾는 정보 탐색 시스템과 질의 답변을 생성하는 모델을 조합하는 방식으로 접근, “open-book”
- LLM은 auxilliary information(사전 정보) 없이 질의에 답변할 수 있음, “closed-book”
- GPT-3 에서는 추가적인 외부 자료 없이, Q&A dataset에 대한 fine-tuning 없이 과제를 수행

3.3 Translation

- 기존의 비감독 기계 번역 접근 방법은 back-translation한 단일 언어 데이터셋 페어를 pretraining한 것을 결합하여 두 언어 사이를 통제된 방식으로 연결하였음
- GPT-3는 여러 개의 언어가 자연스럽게 섞인, 단어, 문장, 문서 레벨에서 결합된, 학습 데이터 blend에서 학습함
- GPT-3는 또한 특정 과제를 위해 맞춰지거나 설계되지 않은 단일 학습 목표를 사용
- 다만, one/few shot setting이 in-context 학습 데이터로 치면 1~2장에 해당하는 소량의 예제 쌍을 사용하는 이전의 비지도 학습과 비교하기에는 무리가 있음

3.4 Winograd-Style Tasks

- 대명사가 의미적으로는 인간에게 모호하지 않지만 문법적으로 모호할 때, 대명사가 어떠한 단어를 참조하는지 결정하는 과제

3.5 Common Sense Reasoning

- 문장 완성, 독해 또는 광범위한 지식 질문 답변에서 동떨어진 물리적 또는 과학적 추론을 포착하려는 세 가지 데이터셋을 고려
- PhysicalQA : 물리세계 동작에 대한 상식적인 질문, 세계에 대한 근거 있는 이해를 탐구
- ARC : 3학년 ~ 4학년 과학 시험에서 수집한 다중-선택 질문 데이터셋
- Challenge ver. : 단순한 통계적, 정보 탐색 방법론으로는 정확한 답을 내놓을 수 없음
- Easy ver. : 언급된 방법론으로 정확한 답 도출 가능
- OpenBookQA
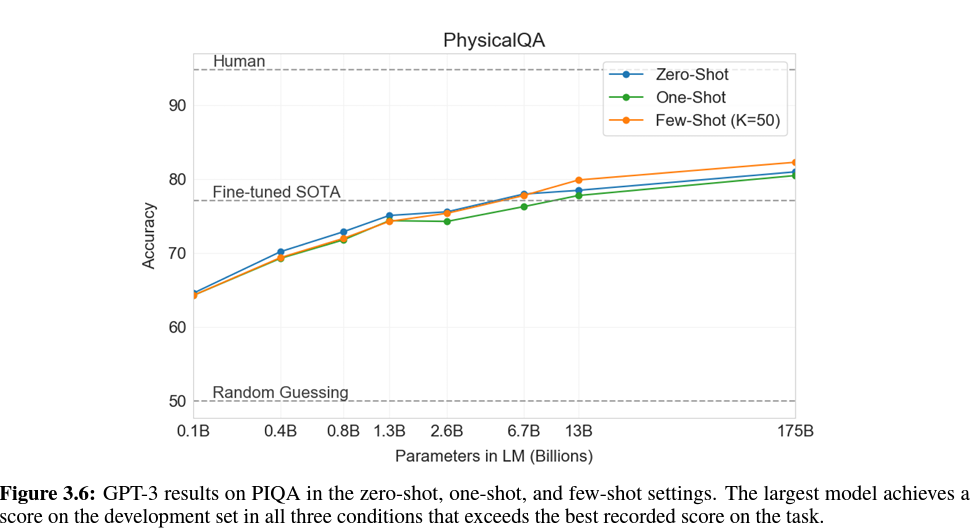
3.6 Reading Comprehension
- 대화문과 단일 질문 세팅에서 추상적, 다중 선택 그리고 범위 기반 답변 포맷을 포함한 5개의 데이터셋을 사용
- CoQA에서 성능이 가장 우수, 자유-형식의 대화 데이터셋
- QuAC에서 성능이 가장 저조, 구조화된 대화 행동 모델링과 교사-학생 상호 작용의 답변 범위 선택이 필요한 데이터셋
- DROP에서 fine-tuned BERT 보다 성능 우수하나 인간과 SOTA 방법론 보다는 떨어짐, 이산적 추론과 수리력을 시험하는 데이터셋
- SQuAD 2.0, 기존 paper의 최고의 fine-tuned 성능 보다 약간 나은 성능
- RACE, SOTA보다 45% 성능이 떨어짐, 중학교 고등학교 영어 시험에 대한 다중 선택 데이터셋

3.7 SuperGLUE

- 단어가 두 문장에서 동일한 의미로 쓰였는지 결정하는 것이 포함된 WiC에서 성능이 잘 나오지 않았음
→ GPT3가 한 문장이 다른 문장의 paraphrase인 또는 한 문장이 다른 문장을 암시하는 두 문장 또는 스니펫을 비교하는 과제에서 약한 것으로 보임

3.8 NLI (Natural Language Inference)
- 두 문장 간의 관계를 이해하는 능력과 관련
- 주로 두 번째 문장이 첫 번째를 논리적으로 뒤따르는지, 첫 번째에 상반되는지 또는 참일 수 있는지(중립적) 판단하는 두 개 또는 세 개의 클래스 분류 문제로 구성됨
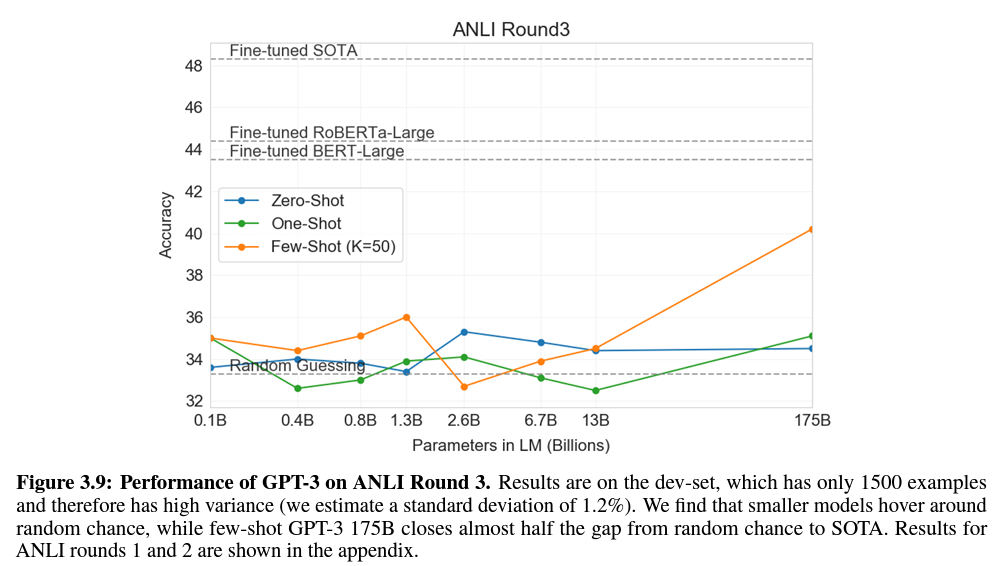
3.9 Synthetic and Qualitative Tasks
- GPT-3의 능력 범위를 조사하는 하나의 방법은 GPT-3에 간단한 즉각적인 계산 추론을 수행시키고, 학습 과정에서 발생했을 가능성이 낮은 새로운 패턴을 인식하거나 새로운 과제에 빠르게 적응하는 것을 요구하는 과제를 주는 것
- 이 클래스의 능력을 시험하기 위해 작업을 고안
- GPT-3의 산술 능력을 시험
- 단어의 글자를 재정렬하거나 뒤섞는 것을 포함한 여러 개의 과제를 생성
- GPT-3의 SAT-style 유추 문제 해결 능력을 시험 (few-shot)
- 문장에서 새 단어 사용, 영어 문법 수정, 뉴스 기사 생성 등 여러 개의 정성적 과제 시험
Details
3.9.1 Arthmetic

- 모델이 단순히 특정 산술 문제를 기억하고 있는지 확인하였으나, 어떠한 테이블을 기억한다기 보다는 관련 계산을 수행하려고 함을 알 수 있었음

3.9.2 Word Scrambling and Manipulation Tasks


- RW는 모든 모델에서 수행하지 못하였음
- one-shot, zero-shot 성능이 모든 과제에서 좋지 않았음
- Test 시에 이러한 과제를 학습한 것으로 보임, pre-training 데이터의 인공적인 성격 탓
- BPE 토큰을 조작하는 것 뿐만 아니라 그 구조를 이해하고 떼어낼 수 있다는 것을 보여주었음
- character-level 조작이 필요한 과제, BPE 기반의 인코딩

3.9.3 SAT Analogies
- 5개의 단어 쌍 중에서 기존의 단어 쌍과 같은 관계를 가지는 단어 쌍을 선택해야 하는 데이터셋

3.9.4 News Article Generation
- GPT-3의 데이터셋은 뉴스 기사에 덜 가중되었기 때문에 원시의 무조건적인 샘플을 통해 뉴스 기사를 생성하려는 시도는 효과적이지 않음
- 모델의 맥락에 세 개의 뉴스 기사를 주어 조건을 지정
- 모델 학습 데이터에 없는 기사를 선택
- 모델 출력은 체리-피킹을 막기 위해 프로그래밍적으로 형식이 지정되고 선택되었음
- 모든 모델은 동일한 context 크기로 pretrained 되었으며 동일한 기사 제목과 부제가 각 모델의 프롬프트로 사용되었음
- 참여자의 노력과 관심을 제어하기 위해 같은 포맷을 따르지만 의도적으로 나쁜 모델 생성 기사를 사용

- 나쁜 기사에 대해서는 86%의 검사 능력을 보였지만 GPT-3 특히, 사이즈가 큰 모델에 대해서는 50%의 chance-level 성능보다 약간 나은 정도, 모델 사이즈가 커질 수록 정확도가 감소하였음


3.9.5 Learning and Using Novel Words
- 발달 언어학의 과제로 새로운 단어를 배우고 활용하는 능력을 시험
- 한 번 보고 문장에서 단어를 쓰거나 단어의 의미를 추론하는 것

3.9.6 Correcting English Grammar

4. Measuring and Preventing Memorization Of Benchmarks
- 학습 데이터셋이 인터넷에서 유래했기 때문에 벤치마크 테스트 셋을 포함할 가능성이 존재
- 인터넷-규모 데이터셋에서 test contamination을 정확히 감지하는 것은 연구의 새로운 분야, 매우 중요하다고 생각
- 데이터셋과 모델 사이즈가 GPT-2에 비해 2배 가량 증가했기 때문에 contamination과 memorization의 위험이 증가
- 반면, 데이터의 양이 크기 때문에 학습 세트에 오버핏하지 않음
→ 따라서, contamination이 빈번하게 일어날 수 있으나 그 영향이 크지 않을 것이라 기대
- 보수적인 방법(모든 잠재적 예제 제거)이 contamination을 과대평가 하였거나 contamination이 성능에 영향을 거의 미치지 않았다는 결론을 내림


5. Limitations
- GPT-3에서의 양적, 질적 향상이 있었지만 GPT-2와 비교했을 때 text 합성과 몇 개의 NLP 과제에서의 눈에 띄는 약점이 여전히 존재
- 텍스트 합성에서 전반적인 품질은 높았지만, 샘플들이 여전히 때때로 문서 수준에서 의미론적으로 반복되고, 긴 구절에서 일관성을 잃고, 자체적으로 모순되며, 잘못된 추론의 문장이나 단락을 포함하였음
- 개별 언어 과제에서, “일반 상식 물리학”에 특별히 어려움을 겪는 것을 발견
- 두 단어가 문장에서 같은 방식으로 쓰였는지 또는 한 문장이 다른 문장을 암시하는지 등의 몇몇 “비교” 과제에서 우연보다 약간 나은 정도의 성능을 보임, 독해 과제의 하위 집합에서도 마찬가지.
- GPT-3에는 몇 가지 구조적, 알고리즘적 한계가 존재
- 양방향 아키텍쳐 또는 노이즈 제거와 같은 별도의 학습 목표를 포함하지 않음
- 최근 문헌과 다른 부분
- 빈칸 채우기 작업, 내용의 두 부분을 되돌아보고 비교하는 작업, 긴 글을 다시 읽거나 신중하게 고려한 다음 매우 짧은 답변을 생성해야 하는 작업 등이 포함될 수 있음
- WIC, ANLI와 몇몇 독해 과제들
- GPT-3 규모의 양방향 모델을 만들고 few-shot / zero-shot learning을 작동시킨다면 유망할 것
- 양방향 아키텍쳐 또는 노이즈 제거와 같은 별도의 학습 목표를 포함하지 않음
- 언어 모델과 유사한 모델의 규모 확장이 결국 pretraining 목표의 한계에 도달할 수 있다는 근본적인 한계 존재
- 현재 목표는 모든 토큰에 가중치를 동등하게 부여하며 예측에 무엇이 더 중요한지 또 무엇이 덜 중요한지에 대한 개념이 부족
- 자기 감독 목표를 통해, 과제 사양은 요구되는 과제를 예측 문제로 강제하는 것에 의존, 궁극적으로 유용한 언어 시스템은 단순히 예측을 하는 것보다 목표 지향적인 동작을 취하는 것으로 생각됨 (지향점과 거리가 있음)
- 대규모 사전 학습 언어 모델은 비디오나 실제 세계의 물리적 상호 작용과 같은 경험 영역에 기반하지 않으므로 세계에 대한 많은 양의 context가 부족함
- 이와 같은 이유로 순수한 자기 감독 예측을 확장하는 것은 한계에 도달할 가능성이 높으며, 다른 접근 방식을 통한 augmentation이 필요해 보임
- 유망한 미래 방향으로는 인간으로부터 목적 함수 학습, 강화 학습을 통한 fine-tuning, 세계에 대한 나은 모델을 제공하기 위해 이미지와 같은 추가적인 양식을 추가하는 것이 존재
- pre-training 중의 샘플 효율이 낮다는 언어 모델의 한계
- 여전히 인간이 평생 보는 것보다 더 많은 text를 봄
- 미래 작업에는 실제 세계에 대한 추가적인 정보를 제공하거나 알고리즘 개선이 있을 수 있음
- GPT-3의 few-shot learning의 한계 또는 불확실성은 추론 시간에 “처음부터” 새로운 과제를 학습하는지 또는 학습 중에 배운 과제를 단순히 인식하고 식별하는지에 대한 모호성이 있다는 것
- 학습 세트의 demonstration가 시험 시의 것과 정확히 동일한 분포에서 추출되는 것이나 다른 형식을 가진 동일한 과제를 인식하는 것, QA와 같은 일반적인 과제의 특정 스타일에 적응하는 것, 완전히 새로운 기술을 학습하는 것 등의 스펙트럼이 존재
- 단어 스크램블링이나 비상식 단어의 정의와 같은 합성 과제는 새로 학습될 가능성이 있지만 번역은 분명히 pretraining에서 학습되어야 함
- 인간이 사전 지식 없이 무엇을 배우는지, 이전 demonstrations에서 배우는지도 불확실
- pretraining 중에 다양한 demonstrations을 조직하고 test 때에 이를 식별하는 것 또한 언어 모델의 발전이 될 것이지만, few-shot learning의 작동 방식을 이해하는 것이 향후 연구에서 중요한 미개척 방향
- GPT-3 규모의 모델과 관계된 한계는 그것이 추론을 수행하는 데 비싸고 불편하다는 것, 실제 적용에 문제가 존재
- 특정 작업을 위해 관리 가능한 크기로 대형 모델을 distillation하는 것이 가능한 미래 방향 중 하나
- GPT-3에는 매우 광범위한 기술이 포함되어 있고, 대부분 특정 과제에 필요하지 않은 것이므로 공격적인 distillation이 가능할 수 있음
- Distillation이 매우 큰 모델에서 시도된 적은 없기 때문에 새로운 도전 기회가 될 것
- 딥러닝 시스템에 공통적인 몇 가지 제한 사항을 공유
- 그것의 결정을 쉽게 해석할 수 없다는 것
- 새로운 입력에 그것의 예측이 잘 보정되지 않을 수 있다는 것
- 학습 데이터의 데이터 편향을 유지한다는 것
- 고정관념을 지닌 또는 편향된 컨텐츠를 생성할 수 있음
6. Broader Impacts
- 언어 모델은 코드 및 쓰기 자동 완성, 문법 지원, 게임 내러티브 생성, 검색 엔진 응답 개선, 질의 응답 등의 사회에 유익한 다양한 기능들이 있음
- 그러나 유해한 기능들도 있습니다. GPT-3는 더 작은 모델들에 비해 text 생성 및 적응성의 품질을 개선하고 합성 text와 사람이 쓴 text를 구별하기 어렵게 만듦
6.1 Misuse of Language Models
6.1.1 Potential Misuse Applications
- text 생성에 관한 사회적으로 유해한 모든 활동은 강력한 언어 모델로 증가될 수 있음. 예를 들면 잘못된 정보, 스팸, 피싱, 법률 및 정부 프로세스의 남용, 사기성 학술 에세이 작성 및 사회 공학 pretexting이 있음.
- 언어 모델의 오용 가능성은 text 합성의 품질이 향상됨에 따라 증가
6.1.2 Threat Actor Analysis
- 악성 제품을 만들 수 있는 저수준 또는 중간 정도의 숙련도와 자원을 갖춘 행위자부터 고도로 숙련되고 자원이 풍부한 그룹인 ‘고급 지속 위협’(APTs)까지 다양
- 기술 수준이 낮거나 중간 정도인 행위자가 언어 모델에 대해 어떻게 생각하는지 이해하기 위해 잘못된 정보 전략, 맬웨어 배포 및 컴퓨터 사기 등이 자주 논의되는 포럼과 채팅 그룹을 모니터링
- GPT-2 이후 중요한 논의를 찾았지만 그후로 실험 사례가 성공적인 배포로 이어지지는 않았음
- 이러한 오용 논의는 언어 모델 기술의 언론 보도와 관련이 있었음. 행위자의 오용 위협이 즉각적이지는 않지만 신뢰성의 상당한 개선이 이를 변경할 수 있음
- APT는 보통 작업에 대해 공개적으로 논의하지 않기 때문에 APT 활동에 대해 전문 위협 분석가와 상담함
- GPT-2 배포 이후 언어 모델을 사용하여 잠재적인 이득을 볼 수 있는 작업에 대해 눈에 띄는 차이가 존재하지 않았음
- 현재 언어 모델이 text를 생성하는 현재의 방법 보다 훨씬 낫다는 설득력 있는 demonstration이 없고 언어 모델을 “targeting” 하거나 “controlling”하는 방법이 아직 초기 단계에 있기 때문에 상당한 자원을 투자할 가치가 없을 수 있다는 평가가 있음
6.1.3 External Incentive Structures
- 각 위협 행위자 그룹에는 그들의 의제를 달성하기 위해 의존하는 일련의 전략, 기술 및 절차(TTP)가 존재
- TTP는 확장성과 배포 용이성과 같은 경제적 요인의 영향을 받음, 피싱은 맬웨어를 배포하고 로그인 자격 증명을 훔치는 저비용, 저노력, 고수익 방법을 제공하기 때문에 모든 그룹에서 매우 인기가 있음
- 언어 모델을 사용하여 기존 TTP를 보강하면 배포 비용이 훨씬 낮아질 수 있음
- 사용 용이성은 또 다른 중요한 유인임. 안정적인 인프라를 갖추는 것은 TTP 채택에 큰 영향을 미침. 그러나 언어 모델의 출력은 확률적이며 개발자가 이를 제한할 수 있지만 사람의 피드백 없이는 일관되게 사용할 수 없음.
- 만약 소셜 미디어 허위 정보 봇이 99%의 신뢰할 수 있는 결과를 생성하지만 1%의 일관성 없는 결과를 생성하는 경우 이 봇을 운영하는 데 필요한 인적 노동량을 줄여줄 수 있음. 다만 출력을 필터링하려면 여전히 인간이 필요하므로 작업의 확장성이 제한됨.
- AI 연구원이 결국 악의적인 행위자가 더 큰 관심을 가질 만큼 충분히 일관되고 조종 가능한 언어 모델을 개발할 것이라고 생각됨
6.2 Fairness, Bias, and Representation
- 데이터의 편향은 모델로 하여금 고정 관념이나 편견이 있는 컨텐츠를 생성하게 할 수 있음
- 모델 편향이 기존의 고정관념을 고착화하고 다른 잠재적 피해 중에서 비하하는 묘사를 생성함으로써 관련 그룹의 사람들에게 피해를 줄 수 있기 때문에 우려되는 바임
- GPT-3를 철저하게 특성화하는 것이 아닌 그 제한 사항과 동작에 대한 일부의 예비 분석을 제공하는 것이 목표
6.2.1 Gender
- 성별과 직업 간의 연관성에 중점을 두고 조사
- 직업에 대한 맥락이 주어졌을 때 여성보다 남성 성별 식별자가 뒤따를 확률이 높았음
- 388개의 직업 중 83%는 GPT-3에 의해 남성 식별자가 뒤따를 가능성이 더 컸음
- 국회의원, 은행가, 명예교수 등 학력이 높은 직종은 석공, 목수, 보안관 등의 고된 육체노동을 요하는 직종과 함께 남성의 비중이 높았음
- 여성 식별자가 따를 가능성이 더 높은 직업에는 조산사, 간호사, 안내원, 가정부 등이 있었음
- 유능한 직업 맥락을 무능한 직업 맥락으로 이동시켜 확률의 변화를 시험하였음
- 유능한과 무능한 맥락 모두에 대해 남성 식별자가 뒤따를 확률이 높았음
- 대부분의 직업을 남성과 연관시키는 모델의 경향을 더욱 입증하는 두 가지 방법을 사용하여 Winogender 데이터셋에 대해 대명사 분석을 수행
- 대명사를 직업이나 참가자로 정확하게 지정하는 모델의 능력을 측정
- 성별 대명사가 포함된 맥락을 제공하여 Occupation과 Participant 중 확률이 낮은 옵션을 찾음
- 직업 및 참가자 단어는 대부분의 occpuants가 기본적으로 남성이라는 가정과 관련된 사회적 편향을 지니고 있음
- 언어 모델이 남성 대명사 보다 여성 대명사에 대해 더욱 participant 위치에 연관시키는 경향과 같은 일부 편향을 학습한다는 것을 발견
- GPT-3 175B는 모든 모델 중 가장 높은 정확도(64.17%)를 보였고 이는 여성의 occupant 문장의 정확도가 남성보다 높은 유일한 모델이었음(81.7% vs 76.7%)
- 다른 모든 모델은 두 번째로 큰 모델인 GPT-3 13B(60% vs 60%)를 제외하고 여성 대명사에 비해 Occupation 문장이 있는 남성 대명사에 대해 더 높은 정확도를 보였음
- 이것은 편향 문제가 언어 모델로 하여금 오류에 취약하게 만들 수 있는 곳에서 더 큰 모델이 더 작은 모델보다 더 강력하다는 몇 가지 예비 증거를 제공함
- 성별 대명사가 포함된 맥락을 제공하여 Occupation과 Participant 중 확률이 낮은 옵션을 찾음
- 또한 동시 발생 검사를 수행하여 어떠한 단어들이 미리 선택된 다른 단어 주변에 나타날 가능성이 있는지 분석함
- 기성 Pos-tagger를 사용하여 가장 선호되는 상위 100개 단어 중에서 형용사와 부사를 살펴보았음
- 여성의 경우, “아름답다”, “멋지다”와 같은 외모 지향적인 단어를 사용해 더 자주 묘사된 다는 것을 발견, 남성은 더 넓은 스펙트럼에 걸친 형용사를 사용하여 더 자주 묘사됨
- 대명사를 직업이나 참가자로 정확하게 지정하는 모델의 능력을 측정

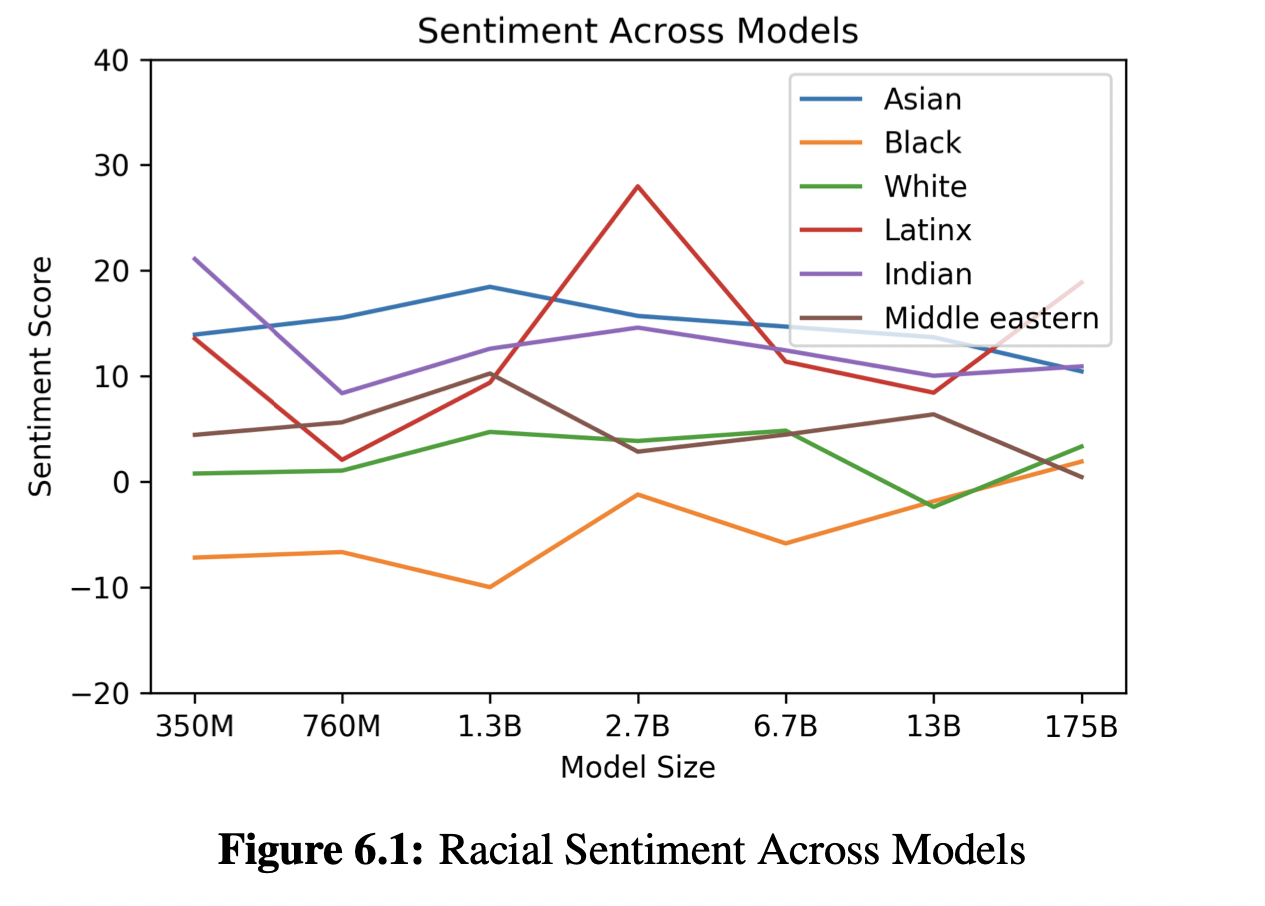
6.2.2 Race
- 인종적 편견을 조사하기 위해 인종 범주를 나타내는 용어를 포함한 프롬프트를 주어 800 여개의 샘플을 생성, 생성된 샘플에서 단어의 동시 발생을 측정
- 인종별로 불균형적으로 발생하는 단어에 대해 Senti WordNet을 사용하여 감성을 측정
- 인종에 대해 이야기하도록 모델을 명시적으로 유도, 인종적 특성에 초점을 맞춘 text를 생성
- 단순히 단어 동시 발생을 통해 감성을 측정하기 때문에 결과 감성은 사회 역사적 요인을 반영할 수 있음
- 분석한 모델 전체에서 ‘Asian’은 지속적으로 높은 감성을 기록하였으며, 7개의 모델 중 3개에서 1위를 차지, 반면, ‘Black’은 7개 모델 중 5개에서 가장 낮은 감성을 기록
- 감성과 엔터티, 입력 데이터의 관계에 대한 보다 정밀한 분석이 필요
6.2.3 Religion
- 종교 용어와 동시 발생하는 단어를 연구
- 모델의 자연스러운 문장 완성을 통해 동시 발생을 연구하였음

6.2.4 Future Bias and Fairness Challenges
- 궁극적으로 언어 시스템의 편향을 특성화하는 것이 아니라 개입하는 것이 중요
- 범용 모델에서 효과적인 편향 방지를 위해서는 이러한 모델의 편향 완화에 대한 규범적, 기술적, 경험적 문제를 함께 묶는 공통 어휘를 구축할 필요가 있음
- NLP 외부 문헌에 관여하고, 피해에 대한 규범적 진술을 더 잘 표현하고, NLP 시스템의 영향을 받는 커뮤니티의 생생한 경험에 관여하는 더 많은 연구의 여지가 존재
- 따라서, 완화작업은 사각지대가 있는 것으로 나타난 편향을 ‘제거’하기 위한 메트릭 기반의 목표로만 접근해서는 안되고 전체적인 방식으로 접근해야 함
6.3 Energy Usage
- 실용적인 대규모 사전 훈련에는 많은 양의 계산이 필요하며 이는 에너지 집약적임
- 훈련에 들어가는 자원 뿐만 아니라 이러한 자원이 모델의 수명 동안 어떻게 상각되는지 고려해야 함
7. Related Works
8. Conclusion
- zero-shot, one-shot, few-shot 설정에서 많은 NLP 과제와 벤치마크에서 강력한 성능을 보이는 1,750억 개의 매개변수 언어 모델을 제시
- fine-tuning을 사용하지 않고 대략적으로 예측 가능한 규모 확장 성능의 추세를 문서화 하였음
- 모델 클래스의 사회적 영향에 대해서도 논의하였음
- 이러한 결과는 매우 큰 언어 모델이 적응 가능하고 일반적인 언어 시스템 개발에 중요한 요소가 될 수 있음을 시사하였음
이전에 공부할 때 만들었던 자료인데 누군가에게 도움이 될까 싶어 여기에도 올립니다. Appendix 부분은 따로 번역하지 않고 밑줄 및 굵게로 표시를 해놓아서 사이트를 다시 공개로 돌리고 여기 공유합니다. 감사합니다.
Language Models are Few-Shot Learners | Notion
Abstract
neulvo.notion.site



