논문 링크 :
Distributed Representations of Words and Phrases and their Compositionality
The recently introduced continuous Skip-gram model is an efficient method for learning high-quality distributed vector representations that capture a large number of precise syntactic and semantic word relationships. In this paper we present several extens
arxiv.org
자료 링크 :
- 모델의 구조 및 동작에 대한 설명이 디테일하게 잘 되어 있음
- word2vec에 대한 리뷰도 있으니 참고하면 좋을듯
Word2Vec (2) : Skip Gram 모델 & 튜닝 기법
An Ed edition
reniew.github.io
논문 제목은 단어 및 구의 분산 표현과 합성성(구성)이며
합성성 (Compositionality)
출처 : https://en.dict.naver.com/#/entry/koen/d39606a57a034e5e83ec77ea6305479e
아래의 글에서 다룬 이전 논문인 Efficient Estimation of Word Representations in Vector Space를 읽었다는 가정 하에 글을 작성하겠음
[논문 같이 읽기] Efficient Estimation of Word Representations in Vector Space
논문 링크 : Efficient Estimation of Word Representations in Vector Space We propose two novel model architectures for computing continuous vector representations of words from very large data sets...
neulvo.tistory.com

최근 소개된 연속적인 Skip-gram model은 고품질의 분산 벡터 표현들을 학습하는데 유용했음
- 다수의 정확한 구문 및 의미 단어 관계들을 파악했음
-> 여기서 우리는 벡터의 품질과 학습 속도를 향상시키는 몇 가지 확장을 제시할 것
1. 빈번한 단어들을 subsampling(*sample의 부분을 취하는 것)함으로써 상당한 속도 향상을 얻고 규칙적인 단어 표현들을 더 많이 학습함
2. negtive sampling을 설명할 것(계층적 softmax의 간단한 대안)
단어 표현들의 내재적 한계는
1. 그들이 단어 순서에 무관심하다는 것과
2. 관용구 표현을 표현하는 데에 대한 무능력함에 있음
-> 텍스트에서 구를 찾는 간단한 방법을 제시하고 수백만 개의 구에 대한 좋은 벡터 표현을 학습하는 것이 가능하다는 것을 보여줄 것

단어의 벡터 공간에서의 분산 표현은 학습 알고리즘으로 하여금 유사한 단어를 그룹화하여 nlp 과제들에 대해 더 좋은 성능을 얻을 수 있게 해주었음
Skip-gram의 학습은 dense matrix multiplications(빽빽한 행렬 곱셈들)를 포함하지 않음
(단어 벡터를 학습하는 데 이전에 사용된 대부분의 NN 아키텍쳐와 다르게)
-> 학습을 매우 효율적으로 만듦, 최적화된 단일-기계 구현은 하루에 1,000억 개 이상의 단어를 훈련할 수 있음
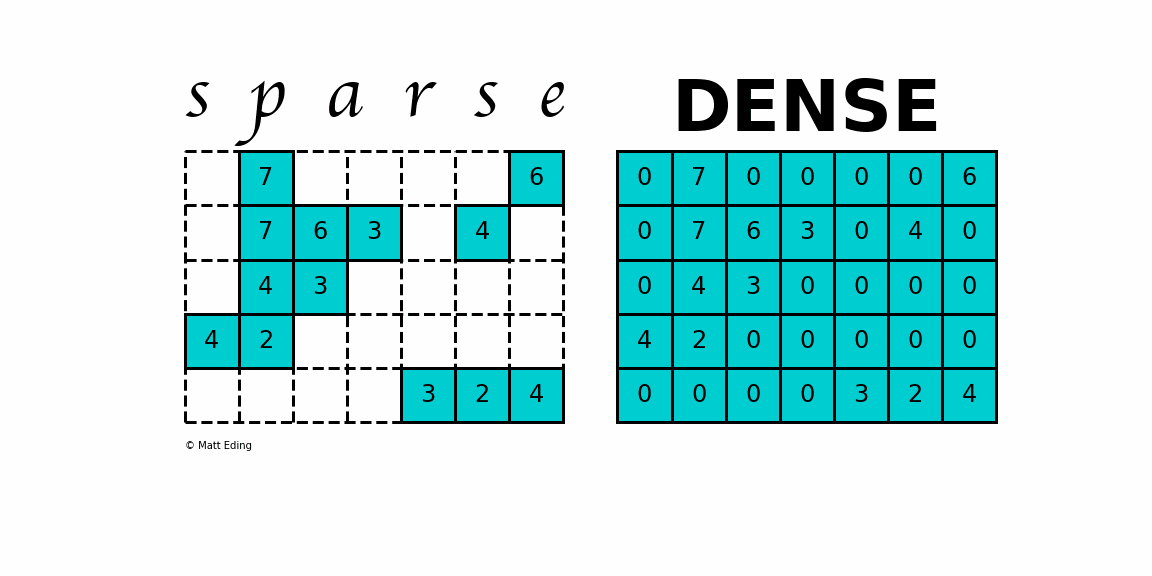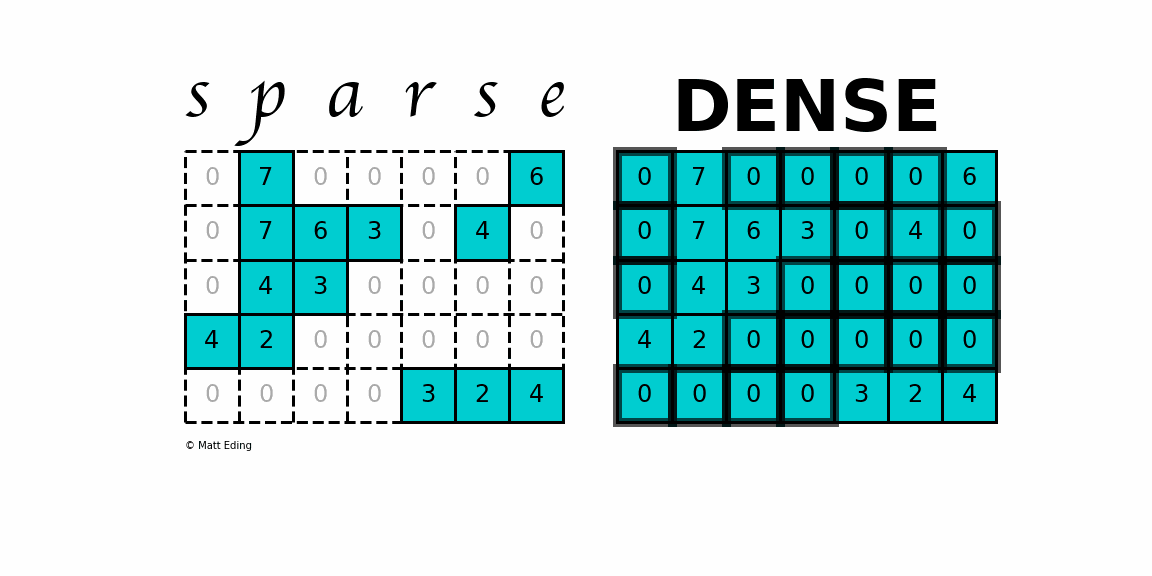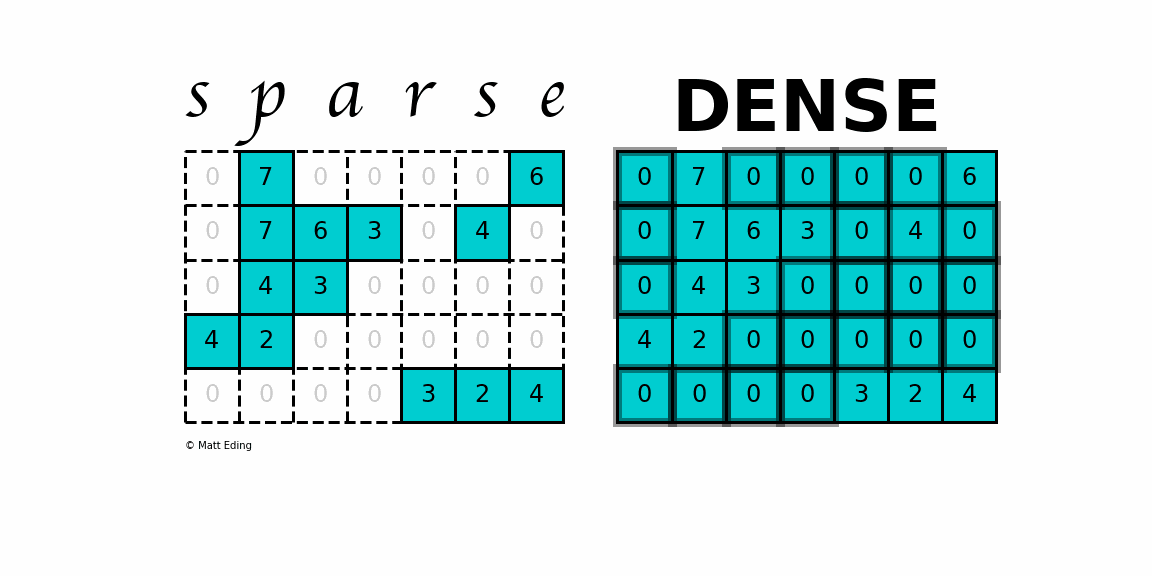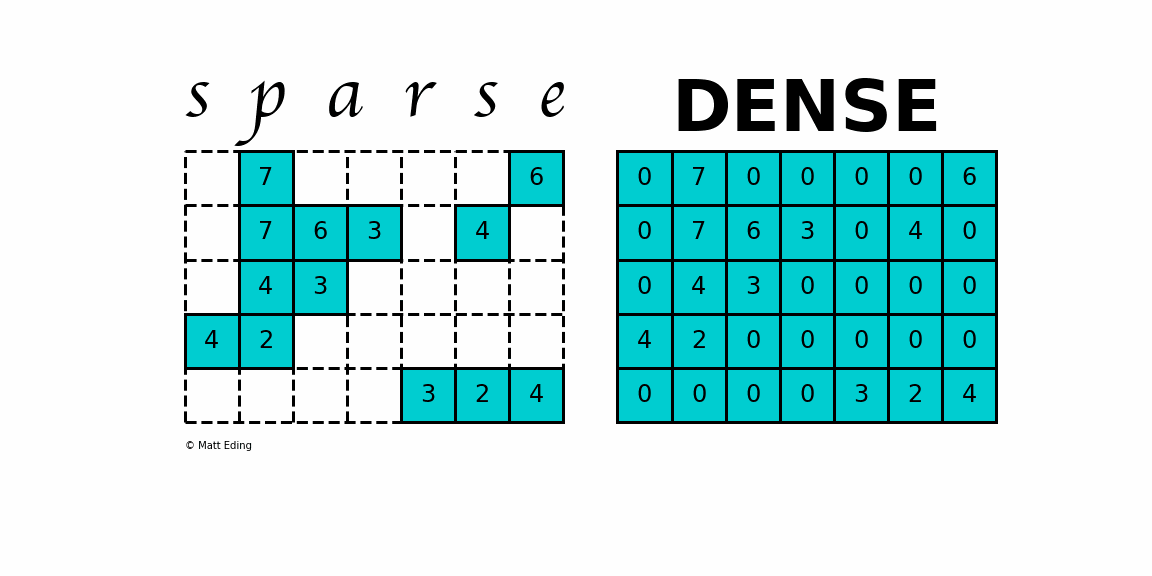
skip-gram 등의 단어의 벡터 표현 이전에는
단어 표현이 행렬(matrix)로 이루어져 자원 소모가 심했다는 것을
이야기하기 위해 dense matrix multiplications를 언급한 것으로 보임


학습된 벡터는 많은 언어적 규칙성과 패턴들을 명시적으로 인코딩(부호화)하기 때문에 NN으로 계산된 단어 표현들은 매우 흥미로움 (많은 언어적 규칙성과 패턴들을 담고 있다 보면 됨)
다소 놀랍게도, 이러한 패턴들 중 많은 부분이 선형 변환으로 표시될 수 있었음
Madrid(수도) - Spain(나라) + France(나라) = Paris(수도)

내용이 중복되긴 하지만,
학습 도중 빈번한 단어들을 subsampling하면 속도가 크게 향상되고
덜 빈번한 단어 표현의 정확도가 높아진다는 것을 보일 것임
게다가, NCE(잡음 대조 측정(?))의 단순화된 변형을 제시할 것
(NCE가 앞서 말한 negative sampling 방법과 관련있음을 짐작할 수 있음)
A Gentle Introduction to Noise Contrastive Estimation - KDnuggets
Find out how to use randomness to learn your data by using Noise Contrastive Estimation with this guide that works through the particulars of its implementation.
www.kdnuggets.com

단어 표현은 개별 단어들의 합성이 아닌 관용구를 표현할 수 없기 때문에 제한됨(없는 제한 사항이 있음)
따라서 전체 구를 표현하기 위해 벡터를 사용하면(구 벡터) Skip-gram 모델의 표현력을 높일 수 있음
(recursive autoencoders에서도 단어 벡터 대신 구 벡터를 사용하는 것이 더 이점이 있음)
단어 기반 모델에서 구 기반 모델로의 확장은 상대적으로 간단
- 먼저 데이터 기반 접근 방식을 사용하여 많은 수의 구들을 식별한 후에, 학습 도중에 구들을 개별 tokens로 처리
(구 벡터의 품질을 평가하기 위해 단어와 구를 모두 포함하는 유추 추론 과제의 테스트 셋을 개발함)
Skip-gram 모델의 또다른 흥미로운 속성이 있음, 간단한 벡터 덧셈이 종종 의미있는 결과를 생성한다는 것
이러한 합성성은 단어 벡터 표현에 대한 기본 수학 연산을 사용하여 (겉보기에) 명확하지 않은 수준의 언어 이해를 얻을 수 있다는 것을 시사함 (의미 관계를 포함)
아래는 recursive auto-encoder의 도식



Skip-gram 모델의 학습 목표는 문장이나 문서에서 주변 단어를 예측하는 데 유용한 단어 표현들을 찾는 것
더 공식적으로, 훈련 단어 시퀀스 w1,w2,w3,...,wt가 주어졌을 때 Skip-gram 모델의 목표는 평균 로그 확률을 극대화하는 것임
여기서 c는 학습 context(vector, an array of numbers)의 사이즈임(중심 단어 wt의 함수일 수 있음)
보다 큰 c는 더 많은 학습 예제를 가지며 훈련 시간을 비용으로 더 높은 정확도를 가짐(훈련 시간이 늘어난다)
기본 Skip-gram 공식은 softmax 함수를 사용하여 p(wt+j|wt)를 정의함
vw와 v'w는 w의 "입력"과 "출력" 벡터 표현이고 W는 어휘의 단어 수
이 공식은 ∇logp(wO|wI)를 계산하는 것의 비용이 종종 (10^5-10^7 용어들) 정도로 큰 W에 비례하기 때문에 비실용적

주요 이점 : 확률 분포를 얻기 위해 NN에서 W 출력 노드를 평가하는 대신에 log2(W) 노드에 대해서만 평가하면 됨
계층적 softmax는 W개의 단어들을 잎으로 사용하는 출력 레이어의 이진 트리 표현을 이용해서 각 노드에 대해 자식 노드들의 상대적 확률을 명시적으로 나타냄
이것은 단어들에 확률을 할당하는 난보(random walk)를 정의함
수식을 풀어보면, n(w,j+1)은 root에서 w까지의 path에서 마주치는 j+1번째 노드를 가리키고
ch(n(w,j))는 root에서 w까지의 path에서 마주치는 j번째 노드의 임의로 고정된 자식을 가리킴
이 둘이 같으면 1 아니면 -1을 리턴하고
그 값을 n(w,j)에 대한 벡터 표현 v'와 입력 w에 대한 벡터 표현인 vT와 곱한 뒤
sigmoid 함수를 통과시켜준 후 product를 사용해 그 결과값들을 곱해 p(w|wI)의 값을 얻음
그리고 이 확률 값의 합은 1
이것은 logp(wO|wI) 및 ∇logp(wO|wI)르 계산하는 비용이 평균적으로 logW보다 크지 않은 L(wO)에 비례한다는 것을 의미함
또한, 두 개의 표현 vw와 v'w를 각 단어 w에 할당하는 Skip-gram의 표준 softmax 공식과 달리
계층적 softmax 공식은 각 단어 w에 대해 하나의 표현 vw를 가지며 모든 내부의 노드 n에 대해 하나의 표현 v'n을 가짐
우리는 이진 Huffman tree를 사용하는데, 이는 빈번한 단어들에 대해 짧은 코드를 할당하기 때문이고 이는 빠른 훈련으로 귀결됨
단어를 빈도 별로 그룹화하는 것이 NN 기반 언어 모델에서 매우 간단한 속도 향상 기술로 잘 작동된다는 것이 이전에 관찰됨
추가로 갑자기 궁금해진 softmax가 왜 soft인지에 대한 discussion 링크:
Why is the softmax function called that way?
I understand that the function "squashes" a real vector space between the values 0 and 1. However I don't see what this has to do with the "max" function, or why that makes it a "softer" version o...
math.stackexchange.com


NCE(잡음 대조 측정)는 좋은 모델은 로지스틱 회귀 방법론을 통해 노이즈와 데이터를 구별할 수 있어야한다고 가정함
NCE는 softmax의 로그 확률을 대략적으로 극대화할 수 있지만, Skip-gram 모델은 고품질의 벡터 표현에만 관심이 있으므로 벡터 표현의 품질이 유지되는 한 우리는 NCE를 단순화할 수 있음
Skip-gram 목표에서 모든 logP(wO|wI) 항을 대체하는 데 사용되는 목적으로 음수 샘플링(NEG)를 정의함
(Skip-gram에서 음수 샘플링을 통해 모든 logP(wO|wI) 항을 대체하겠다는 뜻인듯)
따라서 과제는 각 데이터 샘플에 k개의 음수 샘플이 있는 잡음 분포 Pn(W)에 로지스틱 회귀를 사용해서 뽑은 것들에서 target 단어 wO를 구별하는 것이 됨 (잡음 분포에 로지스틱 회귀를 적용해 뽑은 output에서 target 단어 wO를 구별하는 것이 과제)
NGE와 NCE의 주요 차이점은 NCE는 샘플과 노이즈 분포의 수치적 확률이 모두 필요한 반면 NGE는 샘플만 사용한다는 것
(4) equation에 대한 질의와 해설 링크 (해설의 tutorial article 링크도 좋음)
NLP - negative sampling - how to draw negative samples from noise distribution?
From my understanding, negative sampling randomly samples K negative samples from a noise distribution, P(w). The noise distribution is basically the frequency distribution + some modification on w...
stackoverflow.com


위의 그림은 국가와 수도의 1000차원 Skip-gram 벡터의 2차원 PCA 투영(*PCA : 주성분 분석, 고차원의 데이터를 저차원의 데이터로 환원시키는 기법)
NCE와 NGE는 모두 free parameter로 잡음 분포 Pn(w)를 가짐
unigram 분포 U(w)의 3/4승(U(w)3/4/Z)가 unigram과 균일 분포의 성능을 모두 유의미하게 능가한다는 것을 발견함
PCA에 대한 링크:
[선형대수학 #6] 주성분분석(PCA)의 이해와 활용
주성분 분석, 영어로는 PCA(Principal Component Analysis). 주성분 분석(PCA)은 사람들에게 비교적 널리 알려져 있는 방법으로서, 다른 블로그, 카페 등에 이와 관련된 소개글 또한 굉장히 많다. 그래도 기
darkpgmr.tistory.com


매우 큰 말뭉치에서, 가장 빈번한 단어는 쉽게 수억 번 나타날 수 있음(in, the, a)
이러한 단어는 보통 희귀 단어보다 정보 가치가 적음
이 아이디어는 반대 방향으로도 적용될 수 있음
빈번한 단어의 벡터 표현은 수백만 개의 예제를 학습한 후에도 크게 변하지 않음
희귀 단어와 빈번한 단어 사이의 불균형에 대응하기 위해, 간단한 subsampling 접근 방식을 사용함
학습 세트의 각 단어 wi는 공식에 의해 계산된 확률에 따라 버려짐
공식에서 f(wi)는 단어 wi의 빈도이고 t는 선택된 임계값, 일반적으로 10^-5의 값을 가지는
빈도 순위를 유지하면서 빈도가 t보다 큰 단어를 적극적으로 subsampling 하기 때문에 이 공식을 선택함
다음 섹션에서 볼 수 있듯이 학습을 가속화하고 희귀 단어의 학습된 벡터의 정확도를 크게 향상시킴

계층적 softmax, NCE, NEG 의 성능 비교, NEG를 사용할 때 그리고 k=15일 때 성능이 좋게 나왔다. subsampling을 통해 성능은 보존하면서도 학습 시간을 단축시킬 수 있었다.

위 표의 내용에 대한 부연으로 보임
HS, NCE, NEG, Subsampling을 평가함
구문론적 유추("빠른": "빠르게"::"느린":"느리게")와 의미론적 유추(국가 to 수도 관계)의 두 가지 광범위한 범주의 과제
Skip-gram 모델을 훈련하기 위해 다양한 뉴스 기사로 구성된 대규모 데이터 셋을 사용(10억 단어가 포함된 내부 구글 데이터셋)
학습 데이터에서 5회 미만으로 발생하는 모든 어휘를 삭제하여 692K 크기의 어휘를 만듦
빈번한 단어의 subsampling은 학습 속도를 여러 번 향상시키고 단어 표현을 훨씬 더 정확하게 만듦
Skip-gram 모델의 선형성이 그 벡터들을 선형 유추 추론에 더욱 적합하게 만들었다고 주장할 수 있지만 Mickolov et al.(word2vec 논문)의 결과는 또한 표준 sigmoid RNN(매우 비선형적)에 의해 학습된 벡터가 학습 데이터의 양이 증가함에 따라 이 과제에서 크게 향상되었음을 보여주므로, 비선형 모델 또한 단어 표현의 선형 구조에 대한 선호를 가지고 있음을 시사하고 있음을 알 수 있음


이미 논의된 바와 같이, 많은 구들은 개별 단어들의 의미의 단순한 합성이 아닌 의미를 가지고 있음(복합적인 의미)
구의 벡터 표현을 학습하기 위해, 먼저 함께 자주 등장하고 다른 맥락에서는 드물게 나타나는 단어들을 찾음
이러한 방식으로, 어휘의 크기를 크게 늘리지 않고도 많은 합리적인 구들을 형성할 수 있음
이론적으로 n-gram을 사용하여 Skip-gram 모델을 훈련할 수 있지만 이는 너무 메모리 집중적임(소모가 많다)
unigram과 bigram을 기반으로 구를 형성하는 간단한 데이터 기반 접근 방식을 사용하기로 함
δ는 할인 계수로 사용되어 매우 빈번하지 않은 단어들로 너무 많은 구들이 형성되는 것을 방지함
그런 다음 선택된 임계값 보다 높은 점수를 가진 bigram이 구로 사용됨
일반적으로 임계값을 줄이면서 2-4번 학습 데이터를 통과시켜 여러 단어로 합성된 긴 구가 형성되도록 함
자주 나와서 달아본 n-gram 링크:
3) N-gram 언어 모델(N-gram Language Model)
n-gram 언어 모델은 여전히 카운트에 기반한 통계적 접근을 사용하고 있으므로 SLM의 일종입니다. 다만, 앞서 배운 언어 모델과는 달리 이전에 등장한 모든 단어를 고려하 ...
wikidocs.net

유추 추론 과제의 예제, 앞에 세 구를 통해 4번 째 구를 계산하는 것이 목표, 72% 정확도를 얻음


이전 실험과 동일한 뉴스 데이터로 시작하여 먼저 구 기반 학습 말뭉치를 구성한 다음 다른 하이퍼 파라미터들을 사용하여 여러 Skip-gram 모델을 훈련함
이전과 마찬가지로 300 벡터 차원과 5 context 크기를 사용
결과는 NEG가 k=5일 때 상당한 정확도를 얻고 k=15를 사용하면 더 나은 성능을 달성함을 보여줌
놀랍게도 계층적 softmax가 subsampling 없이 학습됐을 때 낮은 성능을 얻는 다는 것을 발견했지만, 빈번한 단어들을 downsampling했을 때에는 가장 성능이 좋은 방법이 되었음
이것은 subsampling이 학습을 빠르게 할 수 있게 하고 정확도를 향상시킬 수 있다는 것을 보여줌, 적어도 몇몇 케이스들에서는
Table3은 위의 내용의 실험 결과


구 유추 과제의 정확도를 극대화하기 위해, 약 330억 개의 단어가 있는 데이터셋을 사용해 학습 데이터의 양을 늘렸음
계층적 softmax, 1000 차원, context에 대한 전체 문장을 사용함
그 결과 모델의 정확도가 72%에 도달함
학습 데이터의 크기를 6B로 줄였을 때, 더 낮은 정확도인 66%를 얻었음, 많은 양의 학습 데이터가 중요하다는 것을 시사함
다른 모델에 의해 학습된 표현들이 얼마나 다른지에 대한 추가적인 통찰을 얻기 위해, 다양한 모델을 사용하여 자주 사용하지 않는 구의 가장 가까운 이웃을 수동으로 검사했음
테이블 4에 그러한 비교의 샘플이 나와있음
이전 결과와 일관되게 계층적 softmax와 subsampling을 사용하는 모델에서 구에 대한 최고의 표현이 학습되는 것으로 보임


Skip-gram 모델에 의해 학습된 단어와 구 표현이 간단한 벡터 산수를 사용하여 정확한 유추 추론을 수행하는 것이 가능한 선형 구조를 나타냄을 보여주었음
흥미롭게도, Skip-gram 표현은 벡터 표현을 성분 별로 추가하여 단어를 의미있게 결합할 수 있는 또 다른 종류의 선형 구조를 나타냄
이 현상은 표 5에 나와 있음
벡터의 더해지는 속성은 학습 목표를 검사하여 설명될 수 있음
단어 벡터는 softmax 비선형성에 대한 입력과 선형 관계에 있음
단어 벡터가 문장에서 주변 단어들을 예측하도록 훈련됨에 따라 벡터는 단어가 나타나는 context의 분포를 나타내는 것으로 볼 수 있음
이 값은 출력 레이어에서 계산된 확률과 대수적으로 연관되어 있으므로 두 단어 벡터의 합은 두 context 분포의 곱과 관련됨
곱은 여기서 AND 함수로 작동함: 두 단어 모두에 의해 높은 확률이 할당된 단어는 높은 확률을 가지며, 다른 단어는 낮은 확률을 가짐
따라서, "볼가 강"이 "러시아"와 "강"이란 단어들과 같은 문장에서 함께 자주 등장하는 경우 이 두 단어 벡터의 합은 "볼가 강"의 벡터와 가까운 특성 벡터가 됨


학습된 벡터의 품질의 차이에 대한 더 많은 통찰을 주기 위해, 우리는 표6에서 빈번하지 않은 단어의 가장 가까운 이웃을 보여줌으로써 실증적 비교를 제공함
이 예제들은 큰 말뭉치에서 학습된 큰 Skip-gram 모델이 학습된 표현의 품질에서 다른 모델들보다 눈에 띄게 우수함을 보여줌
이는 이 모델이 약 300억 개의 단어로 훈련되었다는 사실에 부분적으로 기인하며, 이는 이전 작업에서 사용된 일반적인 사이즈보다 수백~수천 배의 데이터임
흥미롭게도, 학습 세트가 훨씬 더 크지만, Skip-gram 모델의 학습 시간은 이전 모델 아키텍쳐에 필요한 시간 복잡성의 일부분에 불과함

모델 별 빈번하지 않은 단어의 최근접 이웃 목록

단어와 구의 분산 표현을 Skip-gram 모델로 어떻게 학습시키는지 보여주었음 그리고 이러한 표현들이 정확한 유추 추론을 가능케 하는 선형 구조를 띄고 있음을 입증하였음
계산적으로 효율적인 모델 아키텍쳐 덕분에 이전에 발표된 모델들보다 여러 자릿수 더 많은 데이터 로 모델을 성공적으로 훈련하였음
그것에 대한 결과로 학습된 단어와 구 표현의 품질의 큰 향상을 이루었음, 특히 희소한 독립체들에 대해서
우리는 또한 빈번한 단어의 subsampling이 학습을 더 빠르게 하고 흔하지 않은 단어를 훨씬 더 잘 표현한다는 것을 발견하였음
또 다른 기여는 NEG 알고리즘으로, 특히 빈번한 단어들에 대해 정확한 표현을 학습하는 매우 간단한 학습 방법임
우리의 실험에서 성능에 영향을 미치는 가장 중요한 결정들은, 모델 아키텍쳐의 선택, 벡터의 크기, subsampling 비율, 그리고 학습 window의 크기임
이 작업의 매우 흥미로운 결과는 단어 벡터가 간단한 벡터 덧셈을 사용하여 다소 의미 있게 결합될 수 있다는 것임
이 논문에서 제시하는 구 표현 학습에의 또 다른 접근 방식은 하나의 토큰으로 단순히 구를 표현하는 것임
이 두 가지 접근 방식의 조합은 계산 복잡성을 최소화하면서 텍스트의 긴 부분을 표현하는 단순하지만 강력한 방법을 제공함
따라서 우리의 작업은 재귀적인 행렬-벡터 연산을 사용하여 구를 표현하려는 기존 접근 방식에 대한 보완물로 볼 수 있음
이렇게까지 열심히 할 생각은 아니었는데
하나 하나 뜯어보다 보니까 여기에 좀 매몰됐던 것 같다.
중간을 추구해야 하나 싶기도 하지만
작업하면서 많은 것을 배웠으니까 당장은 괜찮은 걸로 하자.