논문 링크 :
Sequence to Sequence Learning with Neural Networks
Deep Neural Networks (DNNs) are powerful models that have achieved excellent performance on difficult learning tasks. Although DNNs work well whenever large labeled training sets are available, they cannot be used to map sequences to sequences. In this pap
arxiv.org
참고 자료 링크 :
1) 시퀀스-투-시퀀스(Sequence-to-Sequence, seq2seq)
이번 실습은 케라스 함수형 API에 대한 이해가 필요합니다. 함수형 API(functional API, https://wikidocs.net/38861 )에 대해서 우선 숙 ...
wikidocs.net

DNN이 sequence를 sequence에 맵핑하지 못함
(*mapping : 연결을 표현하는 지도를 만드는 것, 정의해봄)
시퀀스 구조에 대한 최소한의 가정을 하는 (일반적인 종단 간) 시퀀스 학습 접근법을 제시
다층의 LSTM으로 입력 시퀀스를 고정된 차원의 벡터에 매핑하고
다른 deep LSTM으로 타깃 시퀀스를 벡터로부터 복호화하는 것
- 어휘 (목록)에 없는 단어에서도 BLEU score가 잘 나옴.
(*BELU SCORE : 번역 성능의 척도가 되는 점수)
- LSTM은 긴 문장에 대해 어려움을 갖지 않음
- LSTM은 어순에 민감하고 능동태와 수동태에 상대적으로 변하지 않는(덜 민감한) 실용적인 구와 문장 표현을 학습했음
- 타겟 문장이 아닌 모든 원천 문장들의 단어 순서를 뒤집으면 LSTM의 성능을 눈에 띄게 높일 수 있음을 발견함
BLEU SCORE :
3) BLEU Score(Bilingual Evaluation Understudy Score)
앞서 언어 모델(Language Model)의 성능 측정을 위한 평가 방법으로 펄플렉서티(perplexity, PPL)를 소개한 바 있습니다. 기계 번역기에도 PPL을 평가 ...
wikidocs.net
Optimization problem :
01-01 Optimization problems?
[https://convex-optimization-for-all.github.io/](https://convex-optimization-for-all.github.io/) ...
wikidocs.net
DNN은 입력과 타깃이 고정된 차원의 벡터로 부호화할 수 있는 문제에만 적용될 수 있음
많은 중요 문제들이 길이가 미리 알려지지 않은 시퀀스로 표현됨을 생각하면 이것은 중대한 한계임
시퀀스를 시퀀스에 맵핑하는 방법을 배우는, 도메인에 독립적인 방법론이 유용할 것임은 명확해 보임
DNN은 입력과 출력의 차원의 알려지고 고정되어야 하기 때문에 시퀀스 문제에 어려움이 있음
하나의 LSTM을 사용해서 입력 시퀀스를 한 번에 한 타임 step 씩 읽어 큰 고정 차원 벡터 표현을 얻고,
또 다른 LSTM을 사용해서 출력 시퀀스를 그 벡터에서 뽑아내자는 것이 아이디어
두 번째 LSTM은 입력 시퀀스에 조건적이라는 점을 제외하고는 본질적으로 상기 레퍼런스들의 RNNLM임
입력과 그에 대응하는 출력 사이의 상당한 시간 지연 때문에
이 어플리케이션에 LSTM을 사용함.
LSTM은 장거리의 시간 종속성을 지닌 데이터에 대해 성공적으로 학습한다는 능력이 있음
위에는 유관 연구들에 대한 이야기
모델은 EOS 토큰을 출력한 후에 예측 만드는 작업을 멈춤
LSTM은 입력 시퀀스를 거꾸로 읽는데,
이것이 데이터의 단기 종속성을 전달하여 최적화 문제를 훨씬 쉽게 만들기 때문

단순한 왼쪽-오른쪽 beam 탐색 디코더를 사용한
(각각 384M개의 파라미터들과 8000 차원 상태의) 5개 심층 LSTMs 앙상블에서 직접 추출한 번역의 성능이 좋았음
개선의 여지가 많은 상대적으로 덜 최적화된 작은-어휘 (목록) NN 아키텍쳐가 구문 기반의 SMT 시스템보다 우수함을 보여줌
(*STM : Statistical Machine Translation, 통계적 기계 번역)

반복되는 내용이지만 계속 강조하기 때문에 가져옴
LSTM : 매우 긴 문장에서 나빠지지 않음
입력 문장 순서를 거꾸로 함 : 단기 종속성을 전달해 최적화 문제를 매우 단순하게 만듦
그래서 SGD(최적화)가, 긴 문장에 문제 없는, LSTM을 잘 학습함
SGD 자료 링크 :
[파이썬][딥러닝] 매개변수 최적화 (SGD,모멘텀,AdaGrad,Adam)
매개변수 갱신 신경망 학습의 목적은 손실 함수의 값을 가능한 한 낮추는 매개변수를 찾는 것이다. 이는 곧...
blog.naver.com


LSTM의 유용한 특성은 그것이 가변적 길이의 입력 문장을
고정된 차원의 벡터 표현으로 매핑하는 방법을 학습한다는 것임
번역문이 원천 문장들의 다른 말 표현임을 감안하면,
번역 목표는 LSTM이 그 의미를 포착하는 문장 표현을 찾도록 권장함
비슷한 의미의 문장들은 가깝고 다른 문장 의미들은 멀기 때문
우리 모델은 단어 순서를 인지하고 있고 능동태와 수동태에 상당히 불변함(결과나 성능이 달라지지 않는다)

RNN 설명하면서 그 한계(복잡하고 단조롭지 않은 관계를 지닌 길이가 다른 시퀀스들을 다루지 못함)를 얘기
그리고 LSTM은 다를 것이라며 전환

LSTM의 목표는 조건부 확률 p(y1,...,yt'|x1,...,xt)를 추정하는 것
(x1,...,xt)가 입력 시퀀스이며 (y1,...,yt')가 대응 출력 시퀀스, 출력 시퀀스의 길이 T'는 T에 따라 달라짐
LSTM은 먼저, LSTM의 마지막 은닉 상태로 주어진 입력 시퀀스(x1,...,xt)의
고정된 차원 표현인 v를 얻은 다음 조건부 확률을 계산함
그다음, 표준 LSTM-LM 공식을 사용해
그것의 초기 은닉 상태가 x1,...,xt의 v표현으로 설정된 y1,...,yt'의 확률을 계산함
위의 방정식에서 각 p(yt|v,t1,...,yt-1) 분포는 어휘 (목록)의 모든 단어들에 softmax를 적용해 표현됨
<EOS>를 사용해 각 문장의 끝을 표현, 모델이 모든 가능한 길이의 시퀀스에 대한 분포를 정의할 수 있게 해 줌
softmax에 대한 자료 링크 :
09) 소프트맥스 회귀(Softmax Regression)
앞서 로지스틱 회귀를 통해 2개의 선택지 중에서 1개를 고르는 이진 분류(Binary Classification)를 풀어봤습니다. 이번에는 3개 이상의 선택지 중에서 1개를 ...
wikidocs.net

실제 모델은 위의 설명과 세 가지 중요한 측면에서 다름 (엇?)
첫째로, 두 개의 다른 LSTM을 사용함
- 무시할 수 있는 계산 비용으로 파라미터 수가 증가하기 때문
- 다중 언어 쌍을 동시에 학습할 수 있기 때문
둘째로, deep LSTM이 shallow LSTM을 상당히 능가하기 때문에, 4층으로 쌓아진 LSTM을 사용
셋째로, 입력 문장의 단어 순서를 거꾸로 함(매우 중요)
그래서 SGD가 입력과 출력 사이의 "커뮤니케이션 확립"을 쉽게 하도록 만들어줌

STM 시스템과 비교 실험함

데이터셋 : WMT`14 영어 - 프랑스어 데이터셋
데이터 : 384M개의 프랑스 단어와 304M개의 영어 단어로 구성된 12M개의 문장의 하위 집합
양 언어에 대해 고정된 어휘 (목록)을 사용
원천 언어에서 가장 많이 나오는 16만 개의 단어들과
타깃 언어에서 가장 많이 나오는 8만 개의 단어들을 사용
어휘 (목록)에 없는 모든 단어는 "UNK" 토큰으로 치환

실험의 핵심은 많은 문장 쌍에 대해 크고 깊은 LSTM을 학습시키는 것
주어진 원천 문장 S에 대해 맞는 번역 T의 로그 확률을 극대화하며 학습시킴
1번 수식이 훈련 목표
훈련이 끝나고 나면, LSTM에 따라 가장 가능성이 높은 번역을 찾아 번역을 생성
(*argmax : arguments of the maxima, 함숫값이 최대화되는 일부 함수 영역의 점 또는 요소)

단순한 왼쪽-오른쪽 beam search decoder로 가장 그럴듯한 번역을 찾음
이 decoder는 작은 숫자 B만큼의 부분 가설을 유지함
각 timestep 마다 어휘 (목록)의 모든 가능한 언어에 대해 beam의 각 부분 가설을 확장함
이것이 가설의 숫자를 매우 많이 증가시키기 때문에
우리는 모델의 로그 확률에 따라 가장 가능성이 높은 가설 중 B만큼을 빼고 나머지를 다 버림
가설에 <EOS> 심벌이 추가되면 그 즉시 빔에서 제거된 후 완전한 가설 세트에 추가됨
빔 사이즈가 2일 때 가장 효과를 봤음
위의 내용이 모두 Beam search에 대한 설명이고 추가 자료를 보는 것이 이해에 도움 됨
Beam Search 관련 자료 :
[Sooftware 머신러닝] Beam Search (빔서치)
Machine Learning: Beam Search (+ Implementation by PyTorch) "Sooftware" 이 글은 제...
blog.naver.com


원천 문장을 뒤집었을 때의 효과에 대해 설명
test perplexity(혼란도) 하락, test BLEU score 상승
원천 언어의 처음 몇 단어들이 타깃 언어의 처음 몇 단어들과 매우 가까워졌기 때문에 최소 시간 지연이 크게 감소함
그래서 역전파가 원천 문장과 타깃 문장 사이의 "커뮤니케이션 확립"을 좀 더 쉽게 하였고,
그 결과 전반적인 성능이 크게 향상되었다고 봄
역전된 원천 문장에서 학습한 LSTM이 가공되지 않은 원천 문장에서 학습한 LSTM 보다
긴 문장에서 훨씬 더 나은 성능을 보였으며
이는 입력 문장을 역전시키면 더 나은 메모리 활용도를 가진 LSTM이 된다는 것을 암시함

LSTM with 4 Layers, 레이어 당 1000개의 cells, 1000차원의 단어 임베딩,
입력 어휘 (목록의 수)는 160,000개이며 출력 어휘 (목록의 수)는 80,000개
문장을 표현하는데 8000개의 실제 값을 씀
각 출력에서 80,000개가 넘는 단어들에 native softmax를 적용
384M개의 파라미터와 64M개의 순수 순환 연결을 가진 LSTM이 됨
- -0.08과 0.08 사이의 균일 분포로 LSTM 파라미터들을 초기화함
- 가속도가 없는 SGD를 사용함 lr = 0.7
- gradient에 128 시퀀스들의 배치들을 사용함 그리고 배치 크기(128)로 나눔
- LSTM이 explodinig gradients 문제를 가질 수 있음에 따라 gradient의 norm이 threshold(임계값)을 넘으면 그것을 scaling(조정)해주는 방식으로 gradient(기울기)의 norm에 대해 엄격한 제약을 적용함
- 문장들의 길이가 제각각이라 미니 배치의 모든 문장들이 대략적으로 같은 길이를 지니도록 해주었고 2배의 속도 향상을 얻음

8-GPU 머신으로 모델을 병렬화함
LSTM의 4 layers 들을 별개의 GPU에 배치함
나머지 4개의 GPU가 softmax를 병렬 처리함 따라서
각 GPU는 1000*20000 크기의 행렬을 곱하는 데 사용됨

무작위 초기화와 미니 배치의 무작위 순서로 다른 LSTM들의 앙상블에서 최고의 결과를 얻음 (아래 표)
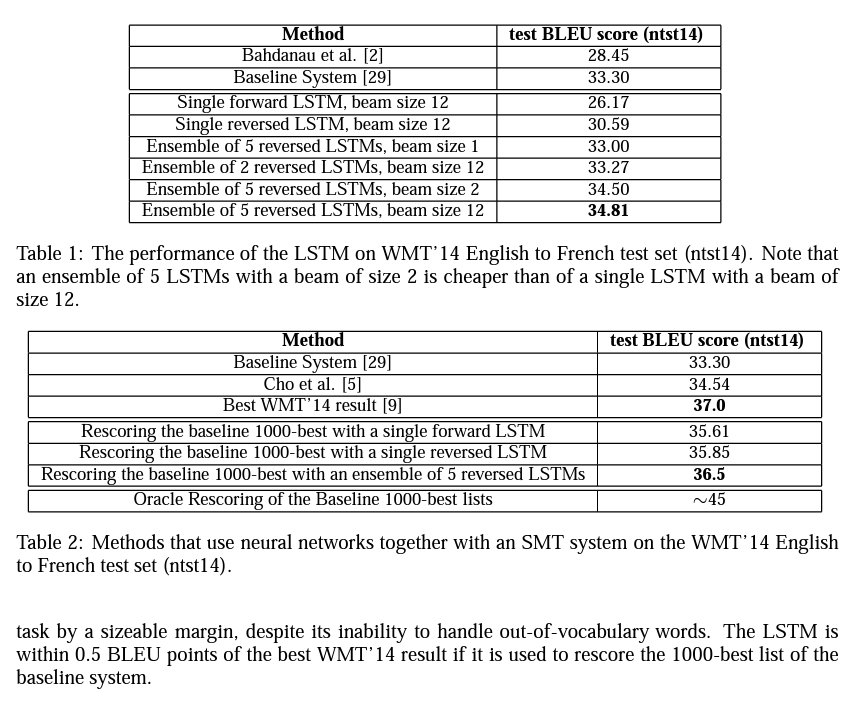
BEST result를 넘지는 못했지만(2번째 표) 대규모 기계 번역에서 순수 신경 번역 시스템이 구문 기반 SMT 기준치를 넘은 것은 처음

단어-가방 모델에서는 포착하기 힘든 의미에 따라 구문들이 clustered(군집됨)
이 예제에서는 주로 단어 순서 기능
두 클러스터(군집) 모두 유사한 내부 구조를 가지고 있음을 유의해라

우리 모델의 매력적인 특징 중 하나는 단어들의 시퀀스를 고정된 차원을 가진 벡터로 전환한다는 것
능동태와 수동태의 replacement(대체)에 대해서는 상당히 둔감한 것을 볼 수 있음
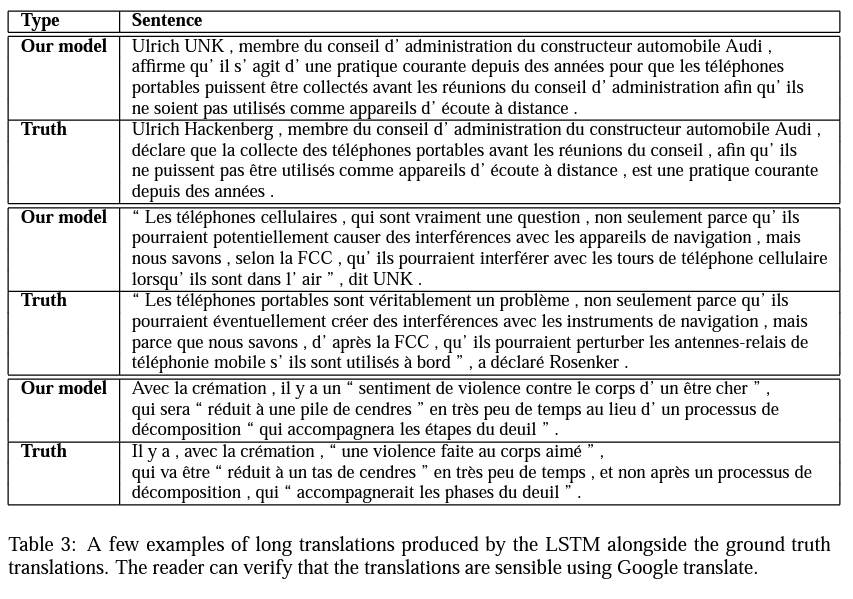
모델 출력과 실제 자료 비교
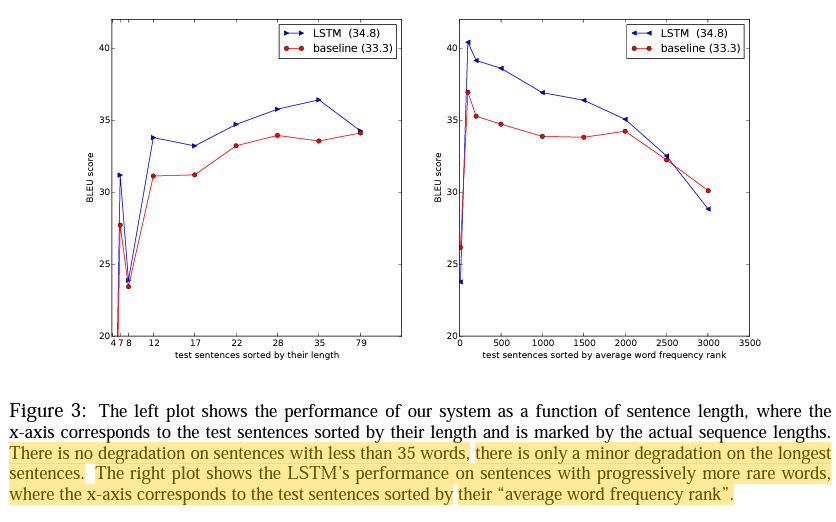
35 단어들 이상의 긴 문장에서는 작은 degradation(성능 저하)이 일어남
희소한 단어들에 대해서도 좋은 성능을 보임(x축은 "평균 단어 빈도 순위"에 따라 정렬된 테스트 문장들에 해당)


유관 연구들의 특징과 한계에 대해 설명함

원천 문장 단어들을 역전시킴으로 얻은 향상의 정도가 놀라울 정도였다
매우 긴 문장들을 정확히 번역해내는 LSTM의 능력에 놀랐다
단순하고, 복잡하지 않으며 상대적으로 최적화되지 않은 접근 방식이 SMT 시스템을 능가함을 보임
앞으로 추가 작업을 통해 번역 정확도가 더 높아질 가능성이 높음

감사함