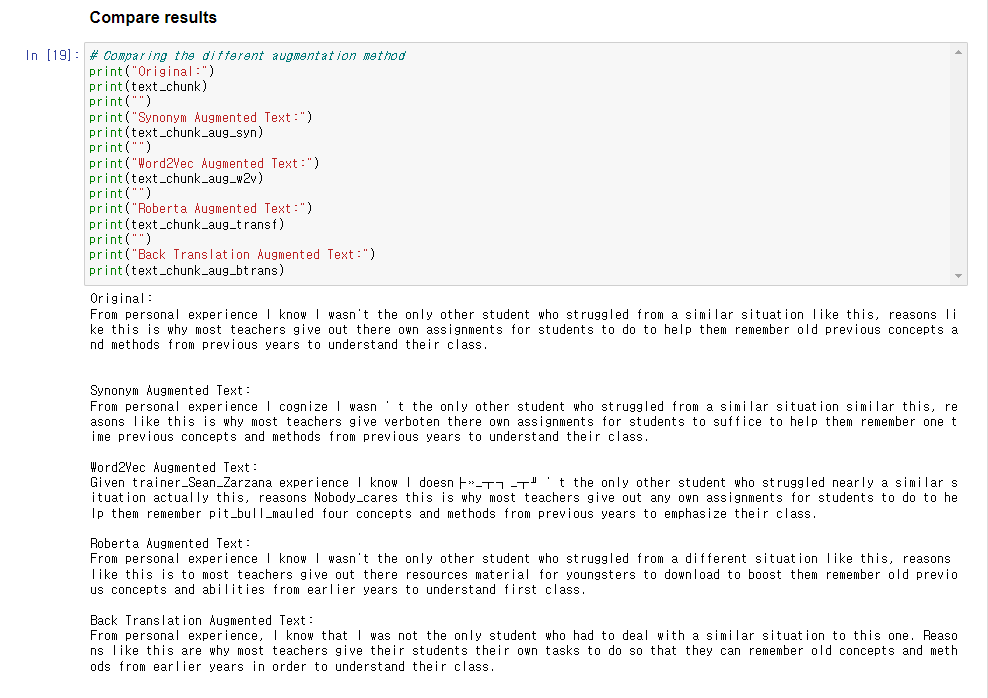
논문 링크 : Distributed Representations of Words and Phrases and their Compositionality The recently introduced continuous Skip-gram model is an efficient method for learning high-quality distributed vector representations that capture a large number of precise syntactic and semantic word relationships. In this paper we present several extens arxiv.org 자료 링크 : - 모델의 구조 및 동작에 대한 설명이 디테일하게 잘 되어 있음 - w..