re — 정규식 연산 — Python 3.10.4 문서
re — 정규식 연산 소스 코드: Lib/re.py 이 모듈은 Perl에 있는 것과 유사한 정규식 일치 연산을 제공합니다. 패턴과 검색 할 문자열은 모두 유니코드 문자열(str)과 8비트 문자열(bytes)이 될 수 있습니
docs.python.org
re — Regular expression operations — Python 3.10.4 documentation
re — Regular expression operations Source code: Lib/re.py This module provides regular expression matching operations similar to those found in Perl. Both patterns and strings to be searched can be Unicode strings (str) as well as 8-bit strings (bytes).
docs.python.org
이번에는 re 모듈에 대해서 중점적으로 다뤄보겠다.
정규식에 관해서는 아래의 링크를 참조
정규표현식 python re
정규식 HOWTO — Python 3.10.4 문서 대소 문자를 구분하지 않는 일치를 수행합니다; 문자 클래스와 리터럴 문자열은 대소 문자를 무시하여 문자와 일치합니다. 예를 들어 [A-Z]는 소문자와도 일치합니
neulvo.tistory.com
Re 메서드 표
| 메서드 | 설명 |
| re.compile(pattern, flags=0) | 정규식 패턴을 정규식 객체로 컴파일 정규식이 단일 프로그램에서 여러 번 사용될 때, 효율적 |
| re.search(pattern, string, flags=0) | string을 통해 스캔하여 정규식 pattern이 일치하는 첫 번째 위치를 찾고, 대응하는 일치 객체를 반환 |
| re.match(pattern, string, flags=0) | string 시작 부분에서 0개 이상의 문자가 정규식 pattern과 일치하면, 해당 일치 객체를 반환 |
| re.fullmatch(pattern, string, flags=0) | 전체 string이 정규식 pattern과 일치하면, 해당 일치 객체를 반환 |
| re.split(pattern, string, maxsplit=0, flags=0) | string을 pattern으로 나눔, maxsplit은 최대 분할 개수 |
| re.findall(pattern, string, flags=0) | string의 모든 겹치지 않는 pattern을 string 리스트 혹은 튜플로 반환 |
| re.finditer(pattern,string,flags=0) | string에서 겹치지 않는 RE pattern의 모든 일치를 일치 객체를 산출하는 이터레이터로 반환 |
| re.sub(pattern, repl, string, count=0, flags=0) | string에서 겹치지 않는 pattern의 가장 왼쪽 일치를 repl로 치환하여 얻은 문자열을 반환 패턴을 찾지 못하면, string이 변경되지 않고 반환 선택적 인자 count는 치환될 패턴 발생의 최대수 |
| re.subn(pattern, repl, string, count=0, flags=0) | sub()와 같은 연산을 수행, 튜플 (new_string, number_of_subs_made)를 반환 |
| re.escape(pattern) | pattern에서 특수 문자를 이스케이프 처리 |
| re.purge() | 정규식 캐시를 지움 |
| re.error(msg, pattern=None, pos=None) | 여기에 있는 함수 중 하나에 전달된 문자열이 유효한 정규식이 아니거나 컴파일이나 일치 중에 다른 에러가 발생할 때 발생하는 예외 msg 포맷되지 않은 에러 메시지 pattern 정규식 패턴 pos 컴파일이 실패한 위치를 가리키는 pattern의 인덱스 lineno pos에 해당하는 줄, colno pos에 해당하는 열 |
Re 플래그 메서드 표
| 플래그 메서드 | |
| re.A / re.ASCII | \w, \W, \b, \B, \d, \D, \s 및 \S가 전체 유니코드 일치 대신 ASCII 전용 일치를 수행하도록 함 |
| re.DEBUG | 컴파일된 정규식에 대한 디버그 정보를 표시 |
| re.I / re.IGNORECASE | 대/소문자를 구분하지 않는 일치를 수행 |
| re.L / re.LOCALE | \w, \W, \b, \B 및 대소 문자를 구분하지 않는 일치를 현재 로케일에 의존하도록 만듦 바이트열 패턴에서만 사용 가능 |
| re.M / re.MULTILINE | 지정될 때, 패턴 문자 '^'는 문자열 시작과 각 줄의 시작(각 줄 바꿈 바로 다음)에서 일치 지정될 때, 패턴 문자 '$'는 문자열의 끝과 각 줄의 끝(각 줄 바꿈 직전)에서 일치 |
| re.S / re.DOTALL | '.' 특수 문자가 줄 넘김을 포함하여 모든 문자와 일치하도록 함 |
| re.X / re.VERBOSE | 이 플래그를 사용하면 패턴의 논리 섹션을 시각적으로 분리하고 주석을 추가해서 더 멋지게 보이고 읽기 쉬운 정규식을 작성할 수 있음 |
자세히 살펴보기
re.compile(pattern, flags=0)

정규식 객체
| 정규식 객체 메서드 | 설명 |
| Pattern.search(string[,pos[,endpos]]) | string을 통해 스캔하여 이 정규식이 일치하는 첫 번째 위치를 찾고, 대응하는 일치 객체를 반환 |
| Pattern.match(string[,pos[,endpos]]) | string의 처음에서 0개 이상의 문자가 이 정규식과 일치하면, 해당하는 일치 객체를 반환 |
| Pattern.fullmatch(string[,pos[,endpos]]) | 전체 string이 이 정규식과 일치하면, 해당하는 일치 객체를 반환 |
| Pattern.split(string, maxsplit=0) | split() 함수와 같은데, 컴파일된 패턴을 사용 |
| Pattern.findall(string[,pos[,endpos]]) | findall() 함수와 유사한데, 컴파일된 패턴을 사용 영역을 제한하는 pos, endpos 사용 이점 |
| Pattern.finditer(string[,pos[,endpos]]) | finditer() 함수와 유사한데, 컴파일된 패턴을 사용 |
| Pattern.sub(repl, string, count=0) | sub() 함수와 같은데, 컴파일된 패턴을 사용 |
| Pattern.subn(repl, string, count=0) | subn() 함수와 같은데, 컴파일된 패턴을 사용 |
| Pattern.flags | 정규식 일치 플래그 |
| Pattern.groups | 패턴에 있는 포착 그룹 수 |
| Pattern.groupindex | (?P<id>)로 정의된 기호 그룹 이름을 그룹 번호에 매핑하는 딕셔너리 |
| Pattern.pattern | 패턴 객체가 컴파일된 패턴 문자열 |



re.match(string[, pos[, endpos]])
| 매서드/어트리뷰트 | 설명 |
| Match.expand(template) | sub() 메서드에서 수행되는 것처럼, 템플릿 문자열 template에 역 슬래시 치환을 수행하여 얻은 문자열을 반환 |
| Match.group([group1, ...]) | match의 하나 이상의 서브 그룹을 반환 |
| Match.__getitem__(g) | m.group(g)와 같으며 match에서 개별 그룹에 더 쉽게 액세스할 수 있게 해줌 |
| Match.groups(default=None) | 1에서 패턴에 있는 그룹의 수까지 일치의 모든 서브 그룹을 포함하는 튜플을 반환 |
| Match.groupdict(default=None) | Match의 모든 이름 있는 서브 그룹을 포함하고, 서브 그룹의 이름을 키로 사용하는 딕셔너리를 반환 |
| Match.start([group]) | Match의 시작 위치를 반환 |
| Match.end([group]) | Match의 끝 위치를 반환 |
| Match.span([group]) | Match의 (시작, 끝) 위치를 포함하는 튜플을 반환 |
| Match.pos | 정규식 객체의 search()나 match() 메서드에 전달된 pos 값 |
| Match.endpos | 정규식 객체의 search()나 match() 메서드에 전달된 endpos 값 |
| Match.lastindex | 마지막으로 일치하는 포착 그룹의 정수 인덱스, 또는 그룹이 전혀 일치하지 않으면 None |
| Match.lastgroup | 마지막으로 일치하는 포착 그룹의 이름, 또는 그룹에 이름이 없거나, 그룹이 전혀 일치하지 않으면 None |
| Match.re | match()나 search() 메서드가 이 일치 인스턴스를 생성한 정규식 객체 |
| Match.string | match()나 search()에 전달된 문자열 |








re.split(pattern, string, maxsplit=0, flags=0)
구분자에 포착 그룹이 있고 문자열 시작 부분에서 일치하면, 결과는 빈 문자열로 시작, 문자열의 끝에 대해서도 마찬가지

패턴에 대한 빈(empty) 일치는 이전의 빈 일치와 인접하지 않을 때만 문자열을 분할

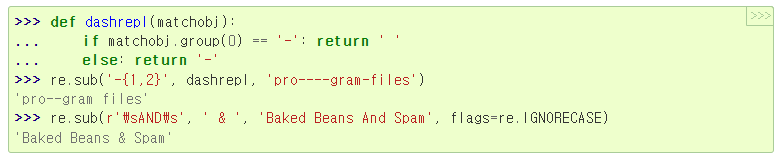
re.sub(pattern, repl, string, count=0, flags=0)
repl이 함수면, pattern의 겹치지 않는 모든 일치마다 호출
이 함수는 단일 일치 객체 인자를 취하고, 치환 문자열을 반환
'Data > Information' 카테고리의 다른 글
| git fork에 대한 짧은 조사 + 고찰 (0) | 2022.11.26 |
|---|---|
| 정규표현식 python re (0) | 2022.04.22 |
| Sql 문법 빠르게 훑어보기 (0) | 2022.04.01 |
| Hugging Face, Question answering (0) | 2022.04.01 |
| Hugging Face, Training a causal language model from scratch (0) | 2022.04.01 |



